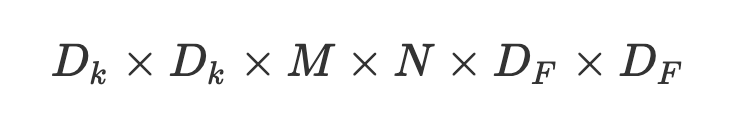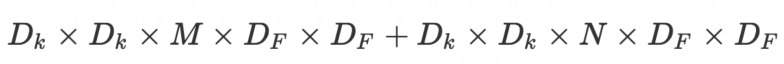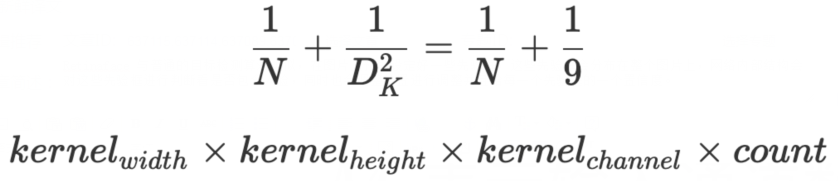人臉檢測之Retina FaceNet
retinaface 人臉檢測算法
甜點
最近一直了解人臉檢測的算法,所以也嘗試學多人臉檢測框架。所以這里將拿出來和大家分享一下
Retinaface 與普通的目標檢測算法類似,在圖片上預先設定好一些先驗框,這些先驗框會分布在整個圖片上,網絡內部結構會對這些先驗框進行判斷看是否包含人臉,同時也會調整位置進行調整并且給每一個先驗框的一個置信度。
在 Retinaface 的先驗框不但要獲得人臉位置,還需要獲得每一個人臉的五個關鍵點位置
接下來我們對 Retinaface 執行過程其實就是在圖片上預先設定好先驗框,網絡的預測結果會判斷先驗框內部是否包含人臉并且對先驗框進行調整獲得預測框和五個人臉關鍵點。
主干特征提取網絡
- mobileNet 和 Resnet
- 在主干網絡(例如 mobileNetv1) 不斷進行特征提取,在特征提取過程就是壓縮長寬到深度(通道擴張)上過程(下采樣)
mobileNet
MobileNet 網絡是由 google 團隊在 2017 年提出的,專注移動端和嵌入式設備中輕量級 CNN 網絡,在大大減少模型參數與運算量下,對于精度只是小幅度下降而已。
加強特征提取網絡 FPN 和 SHH
FPN 構建就是生成特征圖進行融合,通過上采樣然后和上一層的有效特征層進行
SSH 的思想非常簡單,使用了 3 個并行結構,利用 3 x 3 卷積的堆疊代替 5 x 5 與 7 x 7 卷積的效果,
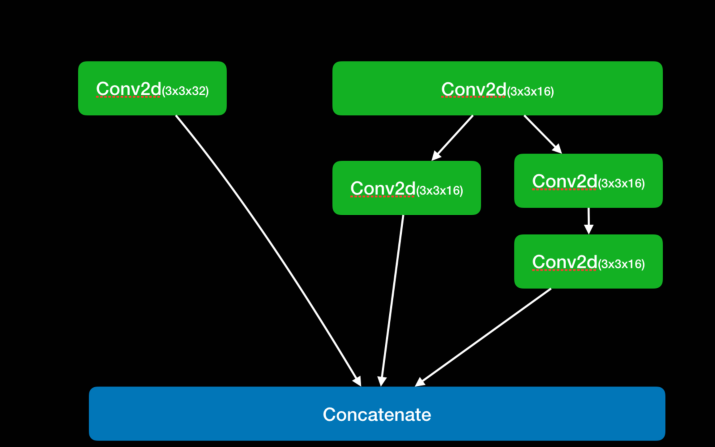
retina head
在主干網絡輸出的相當輸出了不同大小網格,用于檢測不同大小目標,先驗框默認數量為 2,這些先驗框用于檢測目標,然后通過調整得到目標邊界框。
- face classification 用于檢測先驗框中是否存在人臉。也就是判斷先驗框內部是否包含目標,利用一個 1 x 1 的卷積,將 SSH 的通道數調整成 num_anchors x 2 ,用于代表每個先驗框內部包含人臉的概率, 這里覺得有必要解釋一下 2,通常不就是用一個概率來表示先驗框存在人臉的概率,而在這里用了兩個值來表示人臉是否存在先驗框內的概率。其實在兩個值中,如果第一個值比較大,就表示有人臉,那么如果第二值比較大,表示沒有人臉存在
- face box regression 用于調整先驗框的中心和寬高,用四個參數對先驗框進行調整。此時可以利用 1 x 1 的卷積,將 SSH 的通道數調整成 num_anchors x 4 用于表示每個先驗框的調整參數
- facial landmark regression 對先驗框進行調整獲得人臉關鍵點,每一個人臉關鍵點需要兩個調整參數,一共有五個人臉關鍵點。此時利用 1 x 1 的卷積,將 SSH 通道調整成為 num_anchor(num_anchors x 5 x 2) 表示每個先驗框的每一個人臉關鍵點的調整,5 就是人臉上 5 個關鍵點,這里 2 表示對人臉中心點進行調整的參數。
FPN
- class FPN(nn.Module):
- def __init__(self,in_channels_list,out_channels):
- super(FPN,self).__init__()
- leaky = 0
- if (out_channels <= 64):
- leaky = 0.1
- # 利用 1x1 卷積對獲得的3有效特征層進行通道數的調整,輸出通道數都為 64
- self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride = 1, leaky = leaky)
- self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride = 1, leaky = leaky)
- self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride = 1, leaky = leaky)
- self.merge1 = conv_bn(out_channels, out_channels, leaky = leaky)
- self.merge2 = conv_bn(out_channels, out_channels, leaky = leaky)
- def forward(self, input):
- # names = list(input.keys())
- input = list(input.values())
- #
- output1 = self.output1(input[0])
- output2 = self.output2(input[1])
- output3 = self.output3(input[2])
- # 對于最小特征層進行上采樣來獲得 up3
- up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest")
- # 然后將最小特征層經過上采用獲得結果和中間有效特征層進行相加
- output2 = output2 + up3
- # 進行 64 通道卷積進行特征整合
- output2 = self.merge2(output2)
- # 這個步驟和上面類似
- up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest")
- output1 = output1 + up2
- output1 = self.merge1(output1)
- out = [output1, output2, output3]
- return out
SSH
- class SSH(nn.Module):
- def __init__(self, in_channel, out_channel):
- super(SSH, self).__init__()
- assert out_channel % 4 == 0
- leaky = 0
- if (out_channel <= 64):
- leaky = 0.1
- self.conv3X3 = conv_bn_no_relu(in_channel, out_channel//2, stride=1)
- # 用 2 個 3 x 3 的卷積來代替 5 x 5 的卷積
- self.conv5X5_1 = conv_bn(in_channel, out_channel//4, stride=1, leaky = leaky)
- self.conv5X5_2 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
- # 使用 3 個 3 x 3 的卷積來代替 7 x 7 的卷積
- self.conv7X7_2 = conv_bn(out_channel//4, out_channel//4, stride=1, leaky = leaky)
- self.conv7x7_3 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
- def forward(self, input):
- conv3X3 = self.conv3X3(input)
- conv5X5_1 = self.conv5X5_1(input)
- conv5X5 = self.conv5X5_2(conv5X5_1)
- conv7X7_2 = self.conv7X7_2(conv5X5_1)
- conv7X7 = self.conv7x7_3(conv7X7_2)
- # 堆疊
- out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1)
- out = F.relu(out)
- return out
先驗框調整
深度可分離卷積(Depthwise separable convolution)
深度可分離卷積好處就是可以減少參數數量,從而降低運算的成本。經常出現在一些輕量級的網絡結構(這些網絡結構適合于移動設備或者嵌入式設備),深度可分離卷積是由DW(depthwise)和PW(pointwise)組成
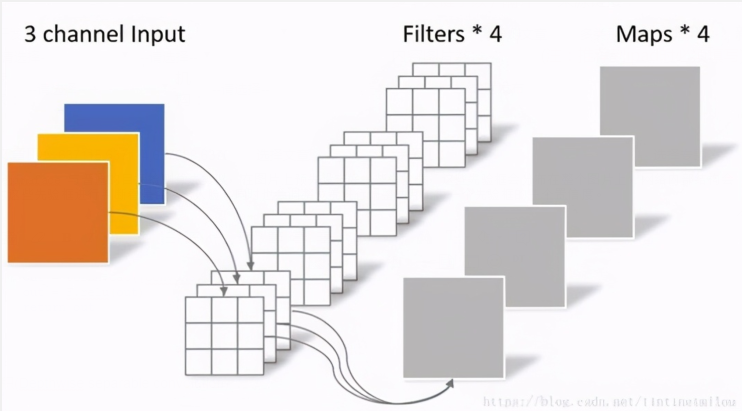
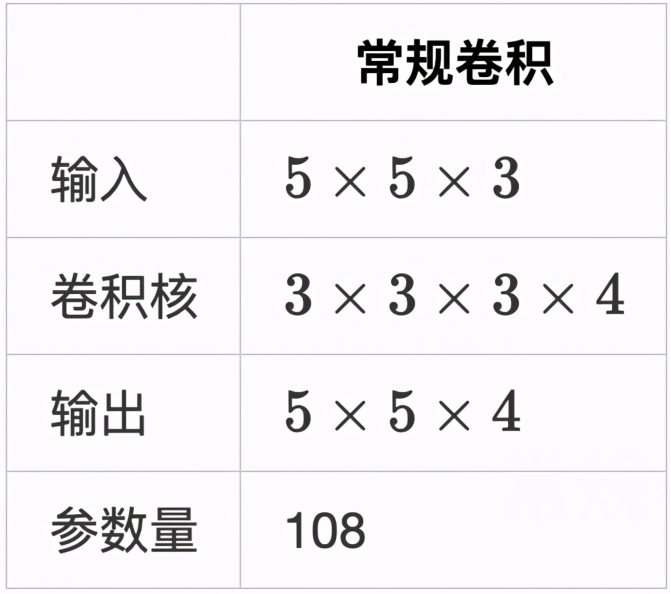
這里我們通過對比普通卷積神經網絡來解釋,深度可分離卷積是如何減少參數
- 卷積核通道數與輸入通道數保持一致
- 輸出通道與卷積核個數保持一致
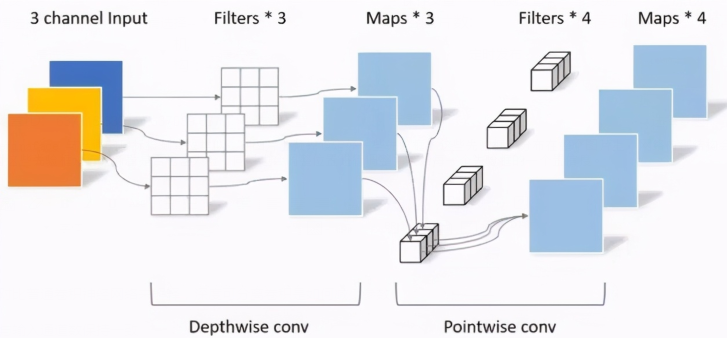
DW(Depthwise Conv)
我們先看圖中 DW 部分,在這一個部分每一個卷積核通道數 1 ,每一個卷積核對應一個輸入通道進行計算,那么可想而知輸出通道數就與卷積核個數以及輸入通道數量保持一致。
簡單總結一下有以下兩點
- 卷積核通道數為 1
- 輸入通道數等于卷積核個數等于輸出通道數
PW(Pointwise Conv)
PW 卷積核核之前普通卷積核類似,只不過 PW 卷積核大小為 1 ,卷積核深度與輸入通道數相同,而卷積核個數核輸出通道數相同