













Python爬蟲實戰:單線程、多線程和協程性能對比
一、前言
今天我要給大家分享的是如何爬取中農網產品報價數據,并分別用普通的單線程、多線程和協程來爬取,從而對比單線程、多線程和協程在網絡爬蟲中的性能。
目標URL:https://www.zhongnongwang.com/quote/product-htm-page-1.html
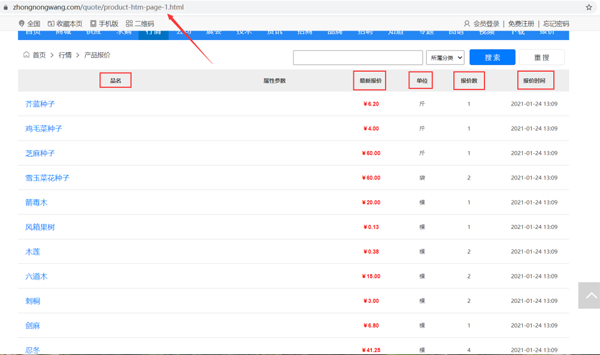
爬取產品品名、最新報價、單位、報價數、報價時間等信息,保存到本地Excel。
二、爬取測試
翻頁查看 URL 變化規律:
- https://www.zhongnongwang.com/quote/product-htm-page-1.html
- https://www.zhongnongwang.com/quote/product-htm-page-2.html
- https://www.zhongnongwang.com/quote/product-htm-page-3.html
- https://www.zhongnongwang.com/quote/product-htm-page-4.html
- https://www.zhongnongwang.com/quote/product-htm-page-5.html
- https://www.zhongnongwang.com/quote/product-htm-page-6.html
檢查網頁,可以發現網頁結構簡單,容易解析和提取數據。
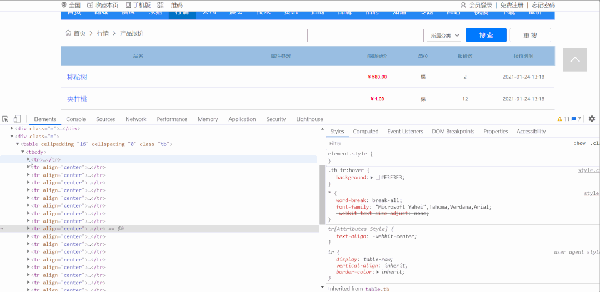
思路:每一條產品報價信息在 class 為 tb 的 table 標簽下的 tbody 下的 tr 標簽里,獲取到所有 tr 標簽的內容,然后遍歷,從中提取出每一個產品品名、最新報價、單位、報價數、報價時間等信息。
- # -*- coding: UTF-8 -*-
- """
- @File :demo.py
- @Author :葉庭云
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- import logging
- from fake_useragent import UserAgent
- from lxml import etree
- # 日志輸出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 隨機產生請求頭
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- url = 'https://www.zhongnongwang.com/quote/product-htm-page-1.html'
- # 偽裝請求頭
- headers = {
- "Accept-Encoding": "gzip", # 使用gzip壓縮傳輸數據讓訪問更快
- "User-Agent": ua.random
- }
- # 發送請求 獲取響應
- rep = requests.get(url, headersheaders=headers)
- print(rep.status_code) # 200
- # Xpath定位提取數據
- html = etree.HTML(rep.text)
- items = html.xpath('/html/body/div[10]/table/tr[@align="center"]')
- logging.info(f'該頁有多少條信息:{len(items)}') # 一頁有20條信息
- # 遍歷提取出數據
- for item in items:
- name = ''.join(item.xpath('.//td[1]/a/text()')) # 品名
- price = ''.join(item.xpath('.//td[3]/text()')) # 最新報價
- unit = ''.join(item.xpath('.//td[4]/text()')) # 單位
- nums = ''.join(item.xpath('.//td[5]/text()')) # 報價數
- time_ = ''.join(item.xpath('.//td[6]/text()')) # 報價時間
- logging.info([name, price, unit, nums, time_])
運行結果如下:
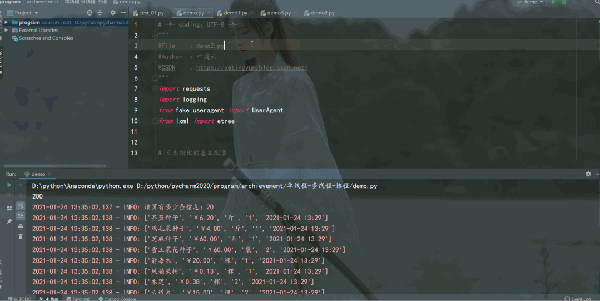
可以成功爬取到數據,接下來分別用普通的單線程、多線程和協程來爬取 50 頁的數據、保存到Excel。
三、單線程爬蟲
- # -*- coding: UTF-8 -*-
- """
- @File :單線程.py
- @Author :葉庭云
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- import logging
- from fake_useragent import UserAgent
- from lxml import etree
- import openpyxl
- from datetime import datetime
- # 日志輸出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 隨機產生請求頭
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook()
- sheet = wb.active
- sheet.append(['品名', '最新報價', '單位', '報價數', '報價時間'])
- start = datetime.now()
- for page in range(1, 51):
- # 構造URL
- url = f'https://www.zhongnongwang.com/quote/product-htm-page-{page}.html'
- # 偽裝請求頭
- headers = {
- "Accept-Encoding": "gzip", # 使用gzip壓縮傳輸數據讓訪問更快
- "User-Agent": ua.random
- }
- # 發送請求 獲取響應
- rep = requests.get(url, headersheaders=headers)
- # print(rep.status_code)
- # Xpath定位提取數據
- html = etree.HTML(rep.text)
- items = html.xpath('/html/body/div[10]/table/tr[@align="center"]')
- logging.info(f'該頁有多少條信息:{len(items)}') # 一頁有20條信息
- # 遍歷提取出數據
- for item in items:
- name = ''.join(item.xpath('.//td[1]/a/text()')) # 品名
- price = ''.join(item.xpath('.//td[3]/text()')) # 最新報價
- unit = ''.join(item.xpath('.//td[4]/text()')) # 單位
- nums = ''.join(item.xpath('.//td[5]/text()')) # 報價數
- time_ = ''.join(item.xpath('.//td[6]/text()')) # 報價時間
- sheet.append([name, price, unit, nums, time_])
- logging.info([name, price, unit, nums, time_])
- wb.save(filename='data1.xlsx')
- delta = (datetime.now() - start).total_seconds()
- logging.info(f'用時:{delta}s')
運行結果如下:
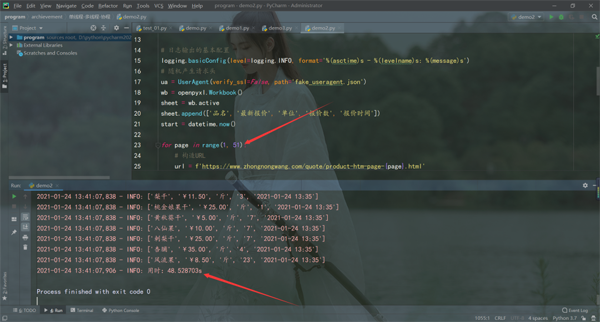
單線程爬蟲必須上一個頁面爬取完成才能繼續爬取,還可能受當時網絡狀態影響,用時48.528703s,才將數據爬取完,速度比較慢。
四、多線程爬蟲
- # -*- coding: UTF-8 -*-
- """
- @File :多線程.py
- @Author :葉庭云
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- import logging
- from fake_useragent import UserAgent
- from lxml import etree
- import openpyxl
- from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
- from datetime import datetime
- # 日志輸出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 隨機產生請求頭
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook()
- sheet = wb.active
- sheet.append(['品名', '最新報價', '單位', '報價數', '報價時間'])
- start = datetime.now()
- def get_data(page):
- # 構造URL
- url = f'https://www.zhongnongwang.com/quote/product-htm-page-{page}.html'
- # 偽裝請求頭
- headers = {
- "Accept-Encoding": "gzip", # 使用gzip壓縮傳輸數據讓訪問更快
- "User-Agent": ua.random
- }
- # 發送請求 獲取響應
- rep = requests.get(url, headersheaders=headers)
- # print(rep.status_code)
- # Xpath定位提取數據
- html = etree.HTML(rep.text)
- items = html.xpath('/html/body/div[10]/table/tr[@align="center"]')
- logging.info(f'該頁有多少條信息:{len(items)}') # 一頁有20條信息
- # 遍歷提取出數據
- for item in items:
- name = ''.join(item.xpath('.//td[1]/a/text()')) # 品名
- price = ''.join(item.xpath('.//td[3]/text()')) # 最新報價
- unit = ''.join(item.xpath('.//td[4]/text()')) # 單位
- nums = ''.join(item.xpath('.//td[5]/text()')) # 報價數
- time_ = ''.join(item.xpath('.//td[6]/text()')) # 報價時間
- sheet.append([name, price, unit, nums, time_])
- logging.info([name, price, unit, nums, time_])
- def run():
- # 爬取1-50頁
- with ThreadPoolExecutor(max_workers=6) as executor:
- future_tasks = [executor.submit(get_data, i) for i in range(1, 51)]
- wait(future_tasks, return_when=ALL_COMPLETED)
- wb.save(filename='data2.xlsx')
- delta = (datetime.now() - start).total_seconds()
- print(f'用時:{delta}s')
- run()
運行結果如下:
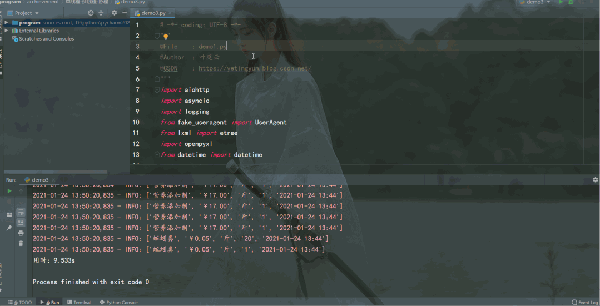
多線程爬蟲爬取效率提升非常可觀,用時 2.648128s,爬取速度很快。
五、異步協程爬蟲
- # -*- coding: UTF-8 -*-
- """
- @File :demo1.py
- @Author :葉庭云
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import aiohttp
- import asyncio
- import logging
- from fake_useragent import UserAgent
- from lxml import etree
- import openpyxl
- from datetime import datetime
- # 日志輸出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 隨機產生請求頭
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook()
- sheet = wb.active
- sheet.append(['品名', '最新報價', '單位', '報價數', '報價時間'])
- start = datetime.now()
- class Spider(object):
- def __init__(self):
- # self.semaphore = asyncio.Semaphore(6) # 信號量,有時候需要控制協程數,防止爬的過快被反爬
- self.header = {
- "Accept-Encoding": "gzip", # 使用gzip壓縮傳輸數據讓訪問更快
- "User-Agent": ua.random
- }
- async def scrape(self, url):
- # async with self.semaphore: # 設置最大信號量,有時候需要控制協程數,防止爬的過快被反爬
- session = aiohttp.ClientSession(headers=self.header, connector=aiohttp.TCPConnector(ssl=False))
- response = await session.get(url)
- result = await response.text()
- await session.close()
- return result
- async def scrape_index(self, page):
- url = f'https://www.zhongnongwang.com/quote/product-htm-page-{page}.html'
- text = await self.scrape(url)
- await self.parse(text)
- async def parse(self, text):
- # Xpath定位提取數據
- html = etree.HTML(text)
- items = html.xpath('/html/body/div[10]/table/tr[@align="center"]')
- logging.info(f'該頁有多少條信息:{len(items)}') # 一頁有20條信息
- # 遍歷提取出數據
- for item in items:
- name = ''.join(item.xpath('.//td[1]/a/text()')) # 品名
- price = ''.join(item.xpath('.//td[3]/text()')) # 最新報價
- unit = ''.join(item.xpath('.//td[4]/text()')) # 單位
- nums = ''.join(item.xpath('.//td[5]/text()')) # 報價數
- time_ = ''.join(item.xpath('.//td[6]/text()')) # 報價時間
- sheet.append([name, price, unit, nums, time_])
- logging.info([name, price, unit, nums, time_])
- def main(self):
- # 50頁的數據
- scrape_index_tasks = [asyncio.ensure_future(self.scrape_index(page)) for page in range(1, 51)]
- loop = asyncio.get_event_loop()
- tasks = asyncio.gather(*scrape_index_tasks)
- loop.run_until_complete(tasks)
- if __name__ == '__main__':
- spider = Spider()
- spider.main()
- wb.save('data3.xlsx')
- delta = (datetime.now() - start).total_seconds()
- print("用時:{:.3f}s".format(delta))
運行結果如下:
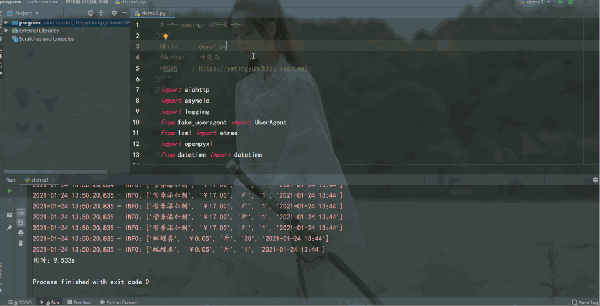
而到了協程異步爬蟲,爬取速度更快,嗖的一下,用時 0.930s 就爬取完 50 頁數據,aiohttp + asyncio 異步爬蟲竟恐怖如斯。異步爬蟲在服務器能承受高并發的前提下增加并發數量,爬取效率提升是非常可觀的,比多線程還要快一些。
三種爬蟲都將 50 頁的數據爬取下來保存到了本地,結果如下:
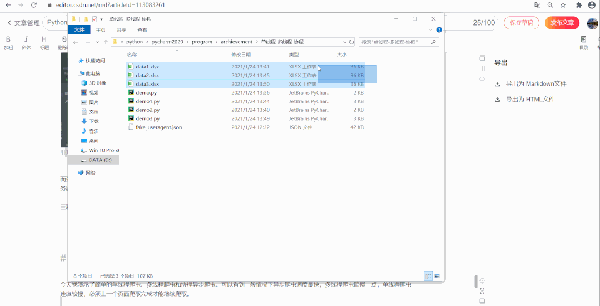
六、總結回顧
今天我演示了簡單的單線程爬蟲、多線程爬蟲和協程異步爬蟲。可以看到一般情況下異步爬蟲速度最快,多線程爬蟲略慢一點,單線程爬蟲速度較慢,必須上一個頁面爬取完成才能繼續爬取。
但協程異步爬蟲相對來說并不是那么好編寫,數據抓取無法使用 request 庫,只能使用aiohttp,而且爬取數據量大時,異步爬蟲需要設置最大信號量來控制協程數,防止爬的過快被反爬。所以在實際編寫 Python 爬蟲時,我們一般都會使用多線程爬蟲來提速,但必須注意的是網站都有 ip 訪問頻率限制,爬的過快可能會被封ip,所以一般我們在多線程提速的同時可以使用代理 ip 來并發地爬取數據。
- 多線程(multithreading):是指從軟件或者硬件上實現多個線程并發執行的技術。具有多線程能力的計算機因有硬件支持而能夠在同一時間執行多于一個線程,進而提升整體處理性能。具有這種能力的系統包括對稱多處理機、多核心處理器以及芯片級多處理或同時多線程處理器。在一個程序中,這些獨立運行的程序片段叫作 "線程" (Thread),利用它編程的概念就叫作 "多線程處理"。
- 異步(asynchronous):為完成某個任務,不同程序單元之間過程中無需通信協調,也能完成任務的方式,不相關的程序單元之間可以是異步的。例如,爬蟲下載網頁。調度程序調用下載程序后,即可調度其他任務,而無需與該下載任務保持通信以協調行為。不同網頁的下載、保存等操作都是無關的,也無需相互通知協調。這些異步操作的完成時刻并不確定。簡言之,異步意味著無序。
- 協程(coroutine),又稱微線程、纖程,協程是一種用戶態的輕量級線程。協程擁有自己的寄存器上下文和棧。協程調度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧。因此協程能保留上一次調用時的狀態,即所有局部狀態的一個特定組合,每次過程重入時,就相當于進入上一次調用的狀態。協程本質上是個單進程,協程相對于多進程來說,無需線程上下文切換的開銷,無需原子操作鎖定及同步的開銷,編程模型也非常簡單。我們可以使用協程來實現異步操作,比如在網絡爬蟲場景下,我們發出一個請求之后,需要等待一定的時間才能得到響應,但其實在這個等待過程中,程序可以干許多其他的事情,等到響應得到之后才切換回來繼續處理,這樣可以充分利用 CPU 和其他資源,這就是協程的優勢。



















