Scrapy源碼剖析:Scrapy有哪些核心組件?
在上一篇文章:Scrapy源碼剖析:Scrapy是如何運行起來的?我們主要剖析了 Scrapy 是如何運行起來的核心邏輯,也就是在真正執行抓取任務之前,Scrapy 都做了哪些工作。
這篇文章,我們就來進一步剖析一下,Scrapy 有哪些核心組件?以及它們主要負責了哪些工作?這些組件為了完成這些功能,內部又是如何實現的。
爬蟲類
我們接著上一篇結束的地方開始講起。上次講到 Scrapy 運行起來后,執行到最后到了 Crawler 的 crawl 方法,我們來看這個方法:
- @defer.inlineCallbacks
- def crawl(self, *args, **kwargs):
- assert not self.crawling, "Crawling already taking place"
- self.crawling = True
- try:
- # 從spiderloader中找到爬蟲類 并實例化爬蟲實例
- selfself.spider = self._create_spider(*args, **kwargs)
- # 創建引擎
- selfself.engine = self._create_engine()
- # 調用爬蟲類的start_requests方法 拿到種子URL列表
- start_requests = iter(self.spider.start_requests())
- # 執行引擎的open_spider 并傳入爬蟲實例和初始請求
- yield self.engine.open_spider(self.spider, start_requests)
- yield defer.maybeDeferred(self.engine.start)
- except Exception:
- if six.PY2:
- exc_info = sys.exc_info()
- self.crawling = False
- if self.engine is not None:
- yield self.engine.close()
- if six.PY2:
- six.reraise(*exc_info)
- raise
執行到這里,我們看到首先創建了爬蟲實例,然后創建了引擎,最后把爬蟲交給引擎來處理了。
在上一篇文章我們也講到,在 Crawler 實例化時,會創建 SpiderLoader,它會根據我們定義的配置文件 settings.py 找到存放爬蟲的位置,我們寫的爬蟲代碼都在這里。
然后 SpiderLoader 會掃描這些代碼文件,并找到父類是 scrapy.Spider 爬蟲類,然后根據爬蟲類中的 name 屬性(在編寫爬蟲時,這個屬性是必填的),生成一個 {spider_name: spider_cls} 的字典,最后根據 scrapy crawl <spider_name> 命令中的 spider_name 找到我們寫的爬蟲類,然后實例化它,在這里就是調用了_create_spider方法:
- def _create_spider(self, *args, **kwargs):
- # 調用類方法from_crawler實例化
- return self.spidercls.from_crawler(self, *args, **kwargs)
實例化爬蟲比較有意思,它不是通過普通的構造方法進行初始化,而是調用了類方法 from_crawler 進行的初始化,找到 scrapy.Spider 類:
- @classmethod
- def from_crawler(cls, crawler, *args, **kwargs):
- spider = cls(*args, **kwargs)
- spider._set_crawler(crawler)
- return spider
- def _set_crawler(self, crawler):
- self.crawler = crawler
- # 把settings對象賦給spider實例
- self.settings = crawler.settings
- crawler.signals.connect(self.close, signals.spider_closed)
在這里我們可以看到,這個類方法其實也是調用了構造方法,進行實例化,同時也拿到了 settings 配置,來看構造方法干了些什么?
- class Spider(object_ref):
- name = None
- custom_settings = None
- def __init__(self, name=None, **kwargs):
- # name必填
- if name is not None:
- self.name = name
- elif not getattr(self, 'name', None):
- raise ValueError("%s must have a name" % type(self).__name__)
- self.__dict__.update(kwargs)
- # 如果沒有設置start_urls 默認是[]
- if not hasattr(self, 'start_urls'):
- self.start_urls = []
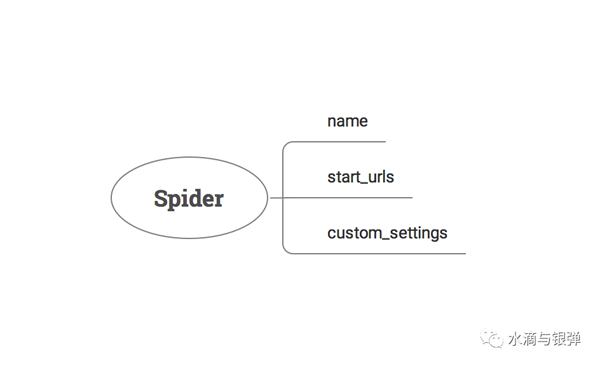
看到這里是不是很熟悉?這里就是我們平時編寫爬蟲類時,最常用的幾個屬性:name、start_urls、custom_settings:
- name:在運行爬蟲時通過它找到我們編寫的爬蟲類;
- start_urls:抓取入口,也可以叫做種子URL;
- custom_settings:爬蟲自定義配置,會覆蓋配置文件中的配置項;
引擎
分析完爬蟲類的初始化后,還是回到 Crawler 的 crawl 方法,緊接著就是創建引擎對象,也就是 _create_engine 方法,看看初始化時都發生了什么?
- class ExecutionEngine(object):
- """引擎"""
- def __init__(self, crawler, spider_closed_callback):
- self.crawler = crawler
- # 這里也把settings配置保存到引擎中
- self.settings = crawler.settings
- # 信號
- self.signals = crawler.signals
- # 日志格式
- self.logformatter = crawler.logformatter
- self.slot = None
- self.spider = None
- self.running = False
- self.paused = False
- # 從settings中找到Scheduler調度器,找到Scheduler類
- self.scheduler_cls = load_object(self.settings['SCHEDULER'])
- # 同樣,找到Downloader下載器類
- downloader_cls = load_object(self.settings['DOWNLOADER'])
- # 實例化Downloader
- self.downloader = downloader_cls(crawler)
- # 實例化Scraper 它是引擎連接爬蟲類的橋梁
- self.scraper = Scraper(crawler)
- self._spider_closed_callback = spider_closed_callback
在這里我們能看到,主要是對其他幾個核心組件進行定義和初始化,主要包括包括:Scheduler、Downloader、Scrapyer,其中 Scheduler 只進行了類定義,沒有實例化。
也就是說,引擎是整個 Scrapy 的核心大腦,它負責管理和調度這些組件,讓這些組件更好地協調工作。

下面我們依次來看這幾個核心組件都是如何初始化的?
調度器
調度器初始化發生在引擎的 open_spider 方法中,我們提前來看一下調度器的初始化。
- class Scheduler(object):
- """調度器"""
- def __init__(self, dupefilter, jobdir=None, dqclass=None, mqclass=None,
- logunser=False, stats=None, pqclass=None):
- # 指紋過濾器
- self.df = dupefilter
- # 任務隊列文件夾
- selfself.dqdir = self._dqdir(jobdir)
- # 優先級任務隊列類
- self.pqclass = pqclass
- # 磁盤任務隊列類
- self.dqclass = dqclass
- # 內存任務隊列類
- self.mqclass = mqclass
- # 日志是否序列化
- self.logunser = logunser
- self.stats = stats
- @classmethod
- def from_crawler(cls, crawler):
- settings = crawler.settings
- # 從配置文件中獲取指紋過濾器類
- dupefilter_cls = load_object(settings['DUPEFILTER_CLASS'])
- # 實例化指紋過濾器
- dupefilter = dupefilter_cls.from_settings(settings)
- # 從配置文件中依次獲取優先級任務隊列類、磁盤隊列類、內存隊列類
- pqclass = load_object(settings['SCHEDULER_PRIORITY_QUEUE'])
- dqclass = load_object(settings['SCHEDULER_DISK_QUEUE'])
- mqclass = load_object(settings['SCHEDULER_MEMORY_QUEUE'])
- # 請求日志序列化開關
- logunser = settings.getbool('LOG_UNSERIALIZABLE_REQUESTS', settings.getbool('SCHEDULER_DEBUG'))
- return cls(dupefilter, jobdir=job_dir(settings), logunserlogunser=logunser,
- stats=crawler.stats, pqclasspqclass=pqclass, dqclassdqclass=dqclass, mqclassmqclass=mqclass)
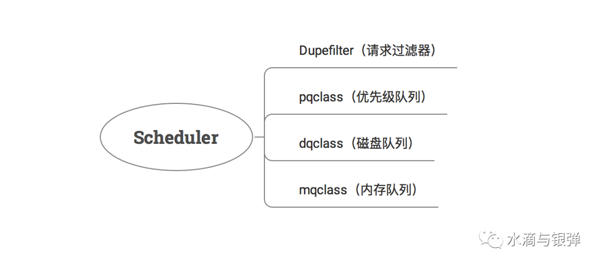
可以看到,調度器的初始化主要做了 2 件事:
- 實例化請求指紋過濾器:主要用來過濾重復請求;
- 定義不同類型的任務隊列:優先級任務隊列、基于磁盤的任務隊列、基于內存的任務隊列;
請求指紋過濾器又是什么?
在配置文件中,我們可以看到定義的默認指紋過濾器是 RFPDupeFilter:
- class RFPDupeFilter(BaseDupeFilter):
- """請求指紋過濾器"""
- def __init__(self, path=None, debug=False):
- self.file = None
- # 指紋集合 使用的是Set 基于內存
- self.fingerprints = set()
- self.logdupes = True
- self.debug = debug
- self.logger = logging.getLogger(__name__)
- # 請求指紋可存入磁盤
- if path:
- self.file = open(os.path.join(path, 'requests.seen'), 'a+')
- self.file.seek(0)
- self.fingerprints.update(x.rstrip() for x in self.file)
- @classmethod
- def from_settings(cls, settings):
- debug = settings.getbool('DUPEFILTER_DEBUG')
- return cls(job_dir(settings), debug)
請求指紋過濾器初始化時,定義了指紋集合,這個集合使用內存實現的 Set,而且可以控制這些指紋是否存入磁盤以供下次重復使用。
也就是說,指紋過濾器的主要職責是:過濾重復請求,可自定義過濾規則。
在下篇文章中我們會介紹到,每個請求是根據什么規則生成指紋的,然后是又如何實現重復請求過濾邏輯的,這里我們先知道它的功能即可。
下面來看調度器定義的任務隊列都有什么作用?
調度器默認定義了 2 種隊列類型:
- 基于磁盤的任務隊列:在配置文件可配置存儲路徑,每次執行后會把隊列任務保存到磁盤上;
- 基于內存的任務隊列:每次都在內存中執行,下次啟動則消失;
配置文件默認定義如下:
- # 基于磁盤的任務隊列(后進先出)
- SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleLifoDiskQueue'
- # 基于內存的任務隊列(后進先出)
- SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.LifoMemoryQueue'
- # 優先級隊列
- SCHEDULER_PRIORITY_QUEUE = 'queuelib.PriorityQueue'
如果我們在配置文件中定義了 JOBDIR 配置項,那么每次執行爬蟲時,都會把任務隊列保存在磁盤中,下次啟動爬蟲時可以重新加載繼續執行我們的任務。
如果沒有定義這個配置項,那么默認使用的是內存隊列。
細心的你可能會發現,默認定義的這些隊列結構都是后進先出的,什么意思呢?
也就是在運行我們的爬蟲代碼時,如果生成一個抓取任務,放入到任務隊列中,那么下次抓取就會從任務隊列中先獲取到這個任務,優先執行。
這么實現意味什么呢?其實意味著:Scrapy 默認的采集規則是深度優先!
如何改變這種機制,變為廣度優先采集呢?這時候我們就要看一下 scrapy.squeues 模塊了,在這里定義了很多種隊列:
- # 先進先出磁盤隊列(pickle序列化)
- PickleFifoDiskQueue = _serializable_queue(queue.FifoDiskQueue, \
- _pickle_serialize, pickle.loads)
- # 后進先出磁盤隊列(pickle序列化)
- PickleLifoDiskQueue = _serializable_queue(queue.LifoDiskQueue, \
- _pickle_serialize, pickle.loads)
- # 先進先出磁盤隊列(marshal序列化)
- MarshalFifoDiskQueue = _serializable_queue(queue.FifoDiskQueue, \
- marshal.dumps, marshal.loads)
- # 后進先出磁盤隊列(marshal序列化)
- MarshalLifoDiskQueue = _serializable_queue(queue.LifoDiskQueue, \
- marshal.dumps, marshal.loads)
- # 先進先出內存隊列
- FifoMemoryQueue = queue.FifoMemoryQueue
- # 后進先出內存隊列
- LifoMemoryQueue = queue.LifoMemoryQueue
如果我們想把抓取任務改為廣度優先,我們只需要在配置文件中把隊列類修改為先進先出隊列類就可以了!從這里我們也可以看出,Scrapy 各個組件之間的耦合性非常低,每個模塊都是可自定義的。
如果你想探究這些隊列是如何實現的,可以參考 Scrapy 作者寫的 scrapy/queuelib 項目,在 Github 上就可以找到,在這里有這些隊列的具體實現。
下載器
回到引擎的初始化的地方,接下來我們來看,下載器是如何初始化的。
在默認的配置文件 default_settings.py 中,下載器配置如下:
- DOWNLOADER = 'scrapy.core.downloader.Downloader'
我們來看 Downloader 類的初始化:
- class Downloader(object):
- """下載器"""
- def __init__(self, crawler):
- # 同樣的 拿到settings對象
- self.settings = crawler.settings
- self.signals = crawler.signals
- self.slots = {}
- self.active = set()
- # 初始化DownloadHandlers
- self.handlers = DownloadHandlers(crawler)
- # 從配置中獲取設置的并發數
- selfself.total_concurrency = self.settings.getint('CONCURRENT_REQUESTS')
- # 同一域名并發數
- selfself.domain_concurrency = self.settings.getint('CONCURRENT_REQUESTS_PER_DOMAIN')
- # 同一IP并發數
- selfself.ip_concurrency = self.settings.getint('CONCURRENT_REQUESTS_PER_IP')
- # 隨機延遲下載時間
- selfself.randomize_delay = self.settings.getbool('RANDOMIZE_DOWNLOAD_DELAY')
- # 初始化下載器中間件
- self.middleware = DownloaderMiddlewareManager.from_crawler(crawler)
- self._slot_gc_loop = task.LoopingCall(self._slot_gc)
- self._slot_gc_loop.start(60)
在這個過程中,主要是初始化了下載處理器、下載器中間件管理器以及從配置文件中拿到抓取請求控制的相關參數。
那么下載處理器是做什么的?下載器中間件又負責哪些工作?
先來看 DownloadHandlers:
- class DownloadHandlers(object):
- """下載器處理器"""
- def __init__(self, crawler):
- self._crawler = crawler
- self._schemes = {} # 存儲scheme對應的類路徑 后面用于實例化
- self._handlers = {} # 存儲scheme對應的下載器
- self._notconfigured = {}
- # 從配置中找到DOWNLOAD_HANDLERS_BASE 構造下載處理器
- # 注意:這里是調用getwithbase方法 取的是配置中的XXXX_BASE配置
- handlers = without_none_values(
- crawler.settings.getwithbase('DOWNLOAD_HANDLERS'))
- # 存儲scheme對應的類路徑 后面用于實例化
- for scheme, clspath in six.iteritems(handlers):
- self._schemes[scheme] = clspath
- crawler.signals.connect(self._close, signals.engine_stopped)
下載處理器在默認的配置文件中是這樣配置的:
- # 用戶可自定義的下載處理器
- DOWNLOAD_HANDLERS = {}
- # 默認的下載處理器
- DOWNLOAD_HANDLERS_BASE = {
- 'file': 'scrapy.core.downloader.handlers.file.FileDownloadHandler',
- 'http': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
- 'https': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
- 's3': 'scrapy.core.downloader.handlers.s3.S3DownloadHandler',
- 'ftp': 'scrapy.core.downloader.handlers.ftp.FTPDownloadHandler',
- }
看到這里你應該能明白了,下載處理器會根據下載資源的類型,選擇對應的下載器去下載資源。其中我們最常用的就是 http 和 https 對應的處理器。
但是請注意,在這里,這些下載器是沒有被實例化的,只有在真正發起網絡請求時,才會進行初始化,而且只會初始化一次,后面文章會講到。
下面我們來看下載器中間件 DownloaderMiddlewareManager 初始化過程,同樣地,這里又調用了類方法 from_crawler 進行初始化,而且 DownloaderMiddlewareManager 繼承了MiddlewareManager 類,來看它在初始化做了哪些工作:
- class MiddlewareManager(object):
- """所有中間件的父類,提供中間件公共的方法"""
- component_name = 'foo middleware'
- @classmethod
- def from_crawler(cls, crawler):
- # 調用from_settings
- return cls.from_settings(crawler.settings, crawler)
- @classmethod
- def from_settings(cls, settings, crawler=None):
- # 調用子類_get_mwlist_from_settings得到所有中間件類的模塊
- mwlist = cls._get_mwlist_from_settings(settings)
- middlewares = []
- enabled = []
- # 依次實例化
- for clspath in mwlist:
- try:
- # 加載這些中間件模塊
- mwcls = load_object(clspath)
- # 如果此中間件類定義了from_crawler 則調用此方法實例化
- if crawler and hasattr(mwcls, 'from_crawler'):
- mw = mwcls.from_crawler(crawler)
- # 如果此中間件類定義了from_settings 則調用此方法實例化
- elif hasattr(mwcls, 'from_settings'):
- mw = mwcls.from_settings(settings)
- # 上面2個方法都沒有,則直接調用構造實例化
- else:
- mw = mwcls()
- middlewares.append(mw)
- enabled.append(clspath)
- except NotConfigured as e:
- if e.args:
- clsname = clspath.split('.')[-1]
- logger.warning("Disabled %(clsname)s: %(eargs)s",
- {'clsname': clsname, 'eargs': e.args[0]},
- extra={'crawler': crawler})
- logger.info("Enabled %(componentname)ss:\n%(enabledlist)s",
- {'componentname': cls.component_name,
- 'enabledlist': pprint.pformat(enabled)},
- extra={'crawler': crawler})
- # 調用構造方法
- return cls(*middlewares)
- @classmethod
- def _get_mwlist_from_settings(cls, settings):
- # 具體有哪些中間件類,子類定義
- raise NotImplementedError
- def __init__(self, *middlewares):
- self.middlewares = middlewares
- # 定義中間件方法
- self.methods = defaultdict(list)
- for mw in middlewares:
- self._add_middleware(mw)
- def _add_middleware(self, mw):
- # 默認定義的 子類可覆蓋
- # 如果中間件類有定義open_spider 則加入到methods
- if hasattr(mw, 'open_spider'):
- self.methods['open_spider'].append(mw.open_spider)
- # 如果中間件類有定義close_spider 則加入到methods
- # methods就是一串中間件的方法鏈 后期會依次調用
- if hasattr(mw, 'close_spider'):
- self.methods['close_spider'].insert(0, mw.close_spider)
DownloaderMiddlewareManager 實例化過程:
- class DownloaderMiddlewareManager(MiddlewareManager):
- """下載中間件管理器"""
- component_name = 'downloader middleware'
- @classmethod
- def _get_mwlist_from_settings(cls, settings):
- # 從配置文件DOWNLOADER_MIDDLEWARES_BASE和DOWNLOADER_MIDDLEWARES獲得所有下載器中間件
- return build_component_list(
- settings.getwithbase('DOWNLOADER_MIDDLEWARES'))
- def _add_middleware(self, mw):
- # 定義下載器中間件請求、響應、異常一串方法
- if hasattr(mw, 'process_request'):
- self.methods['process_request'].append(mw.process_request)
- if hasattr(mw, 'process_response'):
- self.methods['process_response'].insert(0, mw.process_response)
- if hasattr(mw, 'process_exception'):
- self.methods['process_exception'].insert(0, mw.process_exception)
下載器中間件管理器繼承了 MiddlewareManager 類,然后重寫了 _add_middleware 方法,為下載行為定義默認的下載前、下載后、異常時對應的處理方法。
這里我們可以想一下,中間件這么做的好處是什么?
從這里能大概看出,從某個組件流向另一個組件時,會經過一系列中間件,每個中間件都定義了自己的處理流程,相當于一個個管道,輸入時可以針對數據進行處理,然后送達到另一個組件,另一個組件處理完邏輯后,又經過這一系列中間件,這些中間件可再針對這個響應結果進行處理,最終輸出。

Scraper
下載器實例化完了之后,回到引擎的初始化方法中,然后就是實例化 Scraper,在Scrapy源碼分析(一)架構概覽這篇文章中我提到過,這個類沒有在架構圖中出現,但這個類其實是處于Engine、Spiders、Pipeline 之間,是連通這三個組件的橋梁。
我們來看一下它的初始化過程:
- class Scraper(object):
- def __init__(self, crawler):
- self.slot = None
- # 實例化爬蟲中間件管理器
- self.spidermw = SpiderMiddlewareManager.from_crawler(crawler)
- # 從配置文件中加載Pipeline處理器類
- itemproc_cls = load_object(crawler.settings['ITEM_PROCESSOR'])
- # 實例化Pipeline處理器
- self.itemproc = itemproc_cls.from_crawler(crawler)
- # 從配置文件中獲取同時處理輸出的任務個數
- self.concurrent_items = crawler.settings.getint('CONCURRENT_ITEMS')
- self.crawler = crawler
- self.signals = crawler.signals
- self.logformatter = crawler.logformatter
Scraper 創建了 SpiderMiddlewareManager,它的初始化過程:
- class SpiderMiddlewareManager(MiddlewareManager):
- """爬蟲中間件管理器"""
- component_name = 'spider middleware'
- @classmethod
- def _get_mwlist_from_settings(cls, settings):
- # 從配置文件中SPIDER_MIDDLEWARES_BASE和SPIDER_MIDDLEWARES獲取默認的爬蟲中間件類
- return build_component_list(settings.getwithbase('SPIDER_MIDDLEWARES'))
- def _add_middleware(self, mw):
- super(SpiderMiddlewareManager, self)._add_middleware(mw)
- # 定義爬蟲中間件處理方法
- if hasattr(mw, 'process_spider_input'):
- self.methods['process_spider_input'].append(mw.process_spider_input)
- if hasattr(mw, 'process_spider_output'):
- self.methods['process_spider_output'].insert(0, mw.process_spider_output)
- if hasattr(mw, 'process_spider_exception'):
- self.methods['process_spider_exception'].insert(0, mw.process_spider_exception)
- if hasattr(mw, 'process_start_requests'):
- self.methods['process_start_requests'].insert(0, mw.process_start_requests)
爬蟲中間件管理器初始化與之前的下載器中間件管理器類似,先是從配置文件中加載了默認的爬蟲中間件類,然后依次注冊爬蟲中間件的一系列流程方法。配置文件中定義的默認的爬蟲中間件類如下:
- SPIDER_MIDDLEWARES_BASE = {
- # 默認的爬蟲中間件類
- 'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
- 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
- 'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
- 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800,
- 'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
- }
這里解釋一下,這些默認的爬蟲中間件的職責:
- HttpErrorMiddleware:針對非 200 響應錯誤進行邏輯處理;
- OffsiteMiddleware:如果Spider中定義了 allowed_domains,會自動過濾除此之外的域名請求;
- RefererMiddleware:追加 Referer 頭信息;
- UrlLengthMiddleware:過濾 URL 長度超過限制的請求;
- DepthMiddleware:過濾超過指定深度的抓取請求;
當然,在這里你也可以定義自己的爬蟲中間件,來處理自己所需的邏輯。
爬蟲中間件管理器初始化完之后,然后就是 Pipeline 組件的初始化,默認的 Pipeline 組件是 ItemPipelineManager:
- class ItemPipelineManager(MiddlewareManager):
- component_name = 'item pipeline'
- @classmethod
- def _get_mwlist_from_settings(cls, settings):
- # 從配置文件加載ITEM_PIPELINES_BASE和ITEM_PIPELINES類
- return build_component_list(settings.getwithbase('ITEM_PIPELINES'))
- def _add_middleware(self, pipe):
- super(ItemPipelineManager, self)._add_middleware(pipe)
- # 定義默認的pipeline處理邏輯
- if hasattr(pipe, 'process_item'):
- self.methods['process_item'].append(pipe.process_item)
- def process_item(self, item, spider):
- # 依次調用所有子類的process_item方法
- return self._process_chain('process_item', item, spider)
我們可以看到 ItemPipelineManager 也是中間件管理器的一個子類,由于它的行為非常類似于中間件,但由于功能較為獨立,所以屬于核心組件之一。
從 Scraper 的初始化過程我們可以看出,它管理著 Spiders 和 Pipeline 相關的數據交互。

總結
好了,這篇文章我們主要剖析了 Scrapy 涉及到的核心的組件,主要包括:引擎、下載器、調度器、爬蟲類、輸出處理器,以及它們各自都是如何初始化的,在初始化過程中,它們又包含了哪些子模塊來輔助完成這些模塊的功能。
這些組件各司其職,相互協調,共同完成爬蟲的抓取任務,而且從代碼中我們也能發現,每個組件類都是定義在配置文件中的,也就是說我們可以實現自己的邏輯,然后替代這些組件,這樣的設計模式也非常值得我們學習。