













深度學習這些概念都弄清楚了么?TF、TLT、TRT、DS
最近遇到不少同學在使用NVIDIA GPU產品和SDK學習Deep Learning,經常會看到這些詞語,也很容易混淆。今天我們就來擼一擼。
在講這些概念之前,我們先復習啥叫深度學習(Deep Learning)吧.
DL-Deep Learning
深度學習是機器學習的一個分支,其特點是使用幾個,有時上百個功能層。深度學習已經從能夠進行線性分類的感知器發展到添加多層來近似更復雜的函數。加上卷積層使得小圖像的處理性能有了提升,可以識別一些手寫數字。現在,隨著大型圖像數據集的可用性和高性能并行計算卷積網絡正在大規模圖像上得到應用,從而實現了以前不實用的廣泛應用。

在這里,我們看到一些實際應用的深度學習是如何被使用的。
深度學習擅長的一個領域是圖像分類和目標檢測,可以用于機器人和自動車輛以及其他一些應用程序。對于機器人來說,目標檢測是很重要的,因為它使機器人智能地使用視覺信息與環境交互。深度學習也用于人臉識別,可以通過視覺來驗證個人的身份信息,常見于智能手機。但深度學習不僅僅是圖像處理,還可以用來做自然語言處理,比如智能音箱和語音輔助搜索。其他應用還包括醫學圖像、解釋地震圖像判讀和內容推薦系統。

很多應用可以利用云端強大的性能,但有些應用就不能,比如一些應用程序需要低延遲,如機器人或自動汽車,響應時間和可靠性是至關重要的。還有應用程序需要高帶寬,比如視頻分析,我們不斷地流數據從幾個攝像機傳輸給遠程服務器是不實際的。還有些應用比如醫療成像,涉及到病人數據的隱私。另外對于無人飛機,也無法使用云。對于這些應用我們需要在傳感器本身或者附近,就近處理,這就是為什么NVIDIA Jetson平臺是一個很好的邊緣計算平臺。
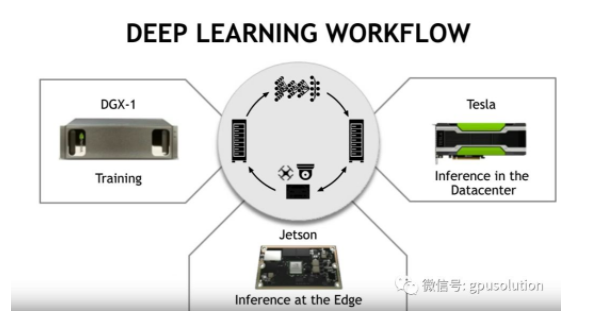
典型的Jetson平臺的工作流程是在GPU服務器或者工作站上進行訓練, 然后將訓練的數據模型在Jetson上做邊緣推理。Nvidia通過為所有主要的深度學習軟件框架集成CUDA加速,使得訓練模型變得容易。這些軟件框架簡化了開發和部署深度學習應用程序的過程。

這些框架大多有細微的差別,但每個框架通常都提供了構建神經網絡的方法和訓練神經網絡的算法。雖然有許多不同的框架,每個框架都有自己的好處.
TF-TensorFlow
Tensorflow就是深度學習框架之一

TensorFlow是種流行的深度學習框架,由谷歌公司開源。在TensorFlow里,神經網絡被定義成一系列相關的操作構成的圖,這些操作可能是卷積,也可能是矩陣乘法,還可能是其它的任意對每層的元素進行變換的操作。雖然在訓練的過程中,網絡層中的參數會發生變化,但網絡結構不會。

在典型的工作流程中,開發人員通過在Python中進行tensorflow API調用來定義計算圖形,Python調用創建一個圖形數據結構,完全定義神經網絡,然后開發人員可以使用明確定義的圖形結構來編寫訓練或推理過程。
TLT-Transfer Learning Toolkit
除了定義新的神經網絡之外,很容易重新使用已經由其他開發人員或研究人員定義和訓練的現有網絡,這些所謂的預訓練網絡可以按原樣使用重新用于新任務,叫遷移學習。在遷移學習的情況下,開發人員將從已保存的文件中加載預先訓練的參數,然后使用新數據集運行訓練過程,這種技術通常會導致更高的準確度,因為訓練樣本少于從頭開始訓練網絡。
NVIDIA推出的NVIDIA Transfer Learning工具包(TLT)主打“無需AI框架方面的專業知識,即可為智能視頻分析和計算機視覺創建準確而高效的AI模型。像零編碼的專業人士一樣發展。”
Transfer Learning Toolkit(TLT)是一個基于python的AI工具包,用于獲取專門構建的預先訓練的AI模型并使用您自己的數據進行自定義。遷移學習將學習到的特征從現有的神經網絡提取到新的神經網絡。當創建大型訓練數據集不可行時,經常使用遷移學習。開發智能視覺AI應用程序和服務的開發人員,研究人員和軟件合作伙伴可以將自己的數據用于微調經過預先訓練的模型,而無需從頭開始進行培訓。
針對特定用例(例如建筑物占用分析,交通監控,停車管理,車牌識別,異常檢測等),NVIDIA已經幫你準備好了預訓練模型,避免開發者從頭開始創建和優化模型的耗時過程,從而讓你將工程工作從80周減少到大約8周,從而在較短的時間內實現更高的吞吐量和準確性。通過使用DeepStream部署視覺AI應用程序,您可以釋放更大的流密度并進行大規模部署。
預先訓練的模型可加速AI訓練過程,并從頭減少與大規模數據收集,標記和訓練模型相關的成本。NVIDIA專門構建的預訓練模型具有高質量的生產質量,可用于各種用例,例如人數統計,車輛檢測,交通優化,停車管理,倉庫運營等。
TRT-TensorRT
一旦網絡完成,就可以直接部署模型。然而,如果模型使用tensorRT進行優化,那么通常會有顯著的性能優勢。TensorRT是由nvidia提供的,是一種優化神經網絡推理的加速器。
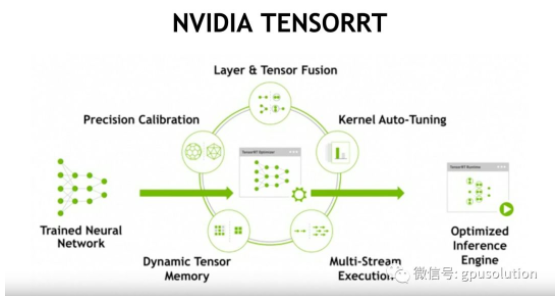
記住:與tensorflow和其他框架不同,tensorRT不用于訓練深度學習模型,而是在你完成訓練時 使用tensorRT優化模型以進行部署,轉換過程重新構建模型以利用高度優化的GPU操作,從而降低延遲并提高吞吐量。
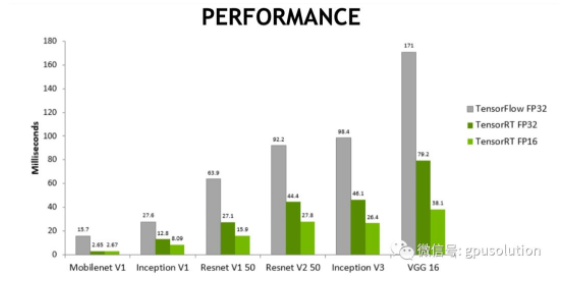
大家可以通過這個視頻來了解如何用TensorRT來部署模型
DS-Deepstream
深度學習是全球視頻分析應用增長的動力,開發者們越來越多的在基于計算機視覺應用中使用深度學習了。到2020年全球啟用的攝像頭達到10億,這是一個難以置信的原始傳感器數據量。有了這些數據,人們、社會團體和公司正在構建強大的應用,利用攝像頭和streaming分析來做一些東西,比如機場的入境管理,制造中心和工廠的產線管理、停車管理,還有客流分析應用,這對構建智慧城市是很重要的。零售分析也是另外一個很重要的使用場景,對于商店來說可以幫助他們了解客戶想買什么....還有其它的行業應用,這些都需要利用視頻分析從而讓人們具備更全面的洞察力。

NVIDIA Deepstream SDK是一個通用的Steaming分析框架,可以讓你從各個傳感器中構建你自己的應用。它實際上是一個建立在GStreamer之上的SDK,GStreamer是一個開源的多媒體分析框架。NVIDIA將Deepstream作為SDK,旨在加速流視頻分析所需的完整堆棧。它是一個模塊化的SDK,允許開發人員為智能視頻分析(IVA)構建一個高效的管道。您在這里看到的是一個典型的IVA管道,由Deepstream插件構建,它支持插件使用的底層硬件、管道的每個功能,并利用硬件體系結構移動數據,而無需任何內存拷貝。
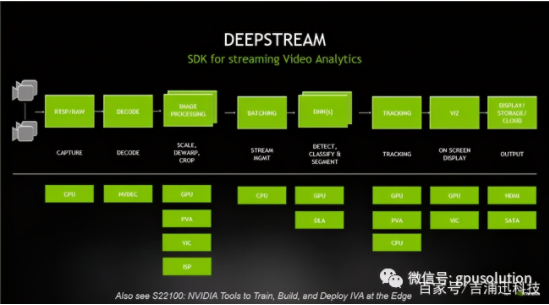
以上這幾個概念在我們開發一個AI應用時候可以互相結合。比如:
- 可以使用TensorFlow開發的深度神經網絡部署在NVIDIA 的邊緣設備上,并利用TensorRT提高推理速度,降低延遲。邊緣計算筆記(三):從Tensorflow生成TensorRT引擎的方法(完結篇)
- 結合NVIDIA Transfer Learning Toolkit(TLT)來使用具有生產質量的AI模型,再使用DeepStream SDK可以輕松部署生成的TLT優化模型,開發一個跟視頻處理相關的智能應用。NVIDIA Deepstream 4.0筆記(四):工業檢測場景應用
希望本文能給大家帶來啟發。



















