













大數據架構師一定要弄清楚Fair Scheduler和Capacity Scheduler
1.項目背景
公司集群上千物理節點,存儲容量100PB+,當前使用50PB左右,YARN的計算內存150Tb+,CPU 30000 Cores+。當前使用的CDH集群,因為性能瓶頸,需要遷移到自建的apache Hadoop3集群。CDH集群默認的是Fair Scheduler,Ambari(Hortonwork)默認使用Capacity Scheduler。CDH和HDP合并后,新的CDP會默認使用Capacity Scheduler調度器。所以如果需要將CDH群集遷移到CDP時,必須從Fair Scheduler遷移到Capacity Scheduler。遷移過程包括在遷移之前自動將某些Fair Scheduler配置轉換為Capacity Scheduler配置,并在遷移之后進行手動微微調。
目前Hadoop3.x默認使用的是Capacity Scheduler,并且Capacity Scheduler支持了Node Labels機制,即通過給節點打標簽的形式,讓不同隊列使用不同的標簽節點進而更好地做計算資源隔離和資源保障。目前大公司來說使用Capacity Scheduler和Fair Scheduler的公司都有很多。至于FIFO調度器在生產上的使用幾乎可以忽略不計。對于一家公司,中型集群規模的話,到底是選擇Capacity Scheduler還是Fair Scheduler呢?從配置使用友好度,日常管理,生產上資源分配,拓展,實際使用經驗等多個維度去考核對比一下兩者的聯系
2.Fair Scheduler和Capacity Scheduler的調研
現在隨著hadoop3的更新,Fair Scheduler和Capacity Scheduler的功能性越來越同質化,相近。但是兩者的之所以沒有合并或者湮沒一家,是因為本質上還是不同,都有一些自己的特質與特定的功能,在不同方向發揮著自己的余熱。下面基于其重要的特性做了一些對比。
編號 | 比較類別 | Fair Scheduler | Capacity Scheduler |
1 | 是否支持多租戶的使用 | 支持 | 支持 |
2 | 是否支持多隊列的資源管理,支持隊列的樹狀結構以及子隊列 | 支持 都可以配置多個父隊列,每個父隊列下多個子隊列 同一個父隊列下的子隊列資源分配值加起來可以不等于父隊列,這樣有利于提高父隊列的資源利用率。但是實際使用最大小值會受父類的限制。 | 支持 都可以配置多個父隊列,每個父隊列下多個子隊列 同一個父隊列下的同一級別的子隊列Capacity之和必須為100,比較麻煩。 |
3 | 支持隊列的最小資源保障 | 支持 可以配置隊列的最小資源,舊的格式支持固定值,新的配置格式支持百分比;vcores = X,memory-mb = Y”或“ vcores = X%,memory-mb = Y%。 同一級別的容量之和加起來可以超過100% 分配文件必須為XML格式 | 支持, 默認配置百分比值或者小數 同一級別隊列的容量總和必須100或者100% 比如30,表示占父隊列的資源總和的30%。 尖叫提示: 不管是Fair Scheduler和Capacity Scheduler,如果當前隊列沒有任務提交時,是不會分配最小資源的,這個時候不保障最小資源,都是0。 如果該隊列有任務提交時,需要等待當前集群釋放資源時,才會分配滿足最小資源的保證。也就說只有有任務跑時才會滿足最小資源。 注意:當一個隊列多個用戶提交使用時,只保證整個隊列的最小資源使用,不保證每個用戶是否能有最小資源保證 默認資源分配都是以內存為調度單位的,但都支持CPU+內存 |
4 | 支持隊列的最大資源限制 | 支持 配置格式同上,最小資源保障的配置。 尖叫提示:不管是Fair Scheduler和Capacity Scheduler隊列的最大資源限制是隊列可以使用的資源最大值,無論如何都不會超過這個值。 同樣,如果父隊列有最大值的限制,則子隊列使用的資源總和不會超過父隊列的最大值。也說明了每個用戶的最大資源使用是有限制的。 | 支持, 默認配置百分比值或者小數 同一級別隊列的容量總和必須100或者100% 比如30,表示占父隊列的資源總和的30%。 |
5 | 隊列之間資源共享與搶占 | 支持 當集群中有隊列資源空閑時,其他供其他隊列搶占使用,這是FS的重要特質 | 支持 當集群中有隊列資源空閑時,其他供其他隊列搶占使用,CP的搶占管理更加精細化,相比配置也更加麻煩。 |
6 | 支持隊列內為不同隊列配置不同的調度策略 | 支持 默認是基于內存的Fair share,也支持FIFO,以及多資源調度策略 | 不支持 |
7 | 支持限制隊列內某個用戶的最大資源使用量 | 不支持 尖叫提示: Capacity Scheduler支持限制隊列中每個用戶可以使用多少資源。這樣可以避免一個用戶接管集群中的所有資源。 | 支持 可以通過配置參數,限制單個用戶使用隊列最大資源的百分比,防止單個用戶獨占整個隊列資源 |
8 | 支持負載均衡機制 | 支持 Fair Schedule的負載均衡機制會將集群中的任務盡可能的分配到各個節點上 | 不支持 |
9 | 資源分配策略 | FAIR,FIFO或者DRF | FIFO或者DRF,默認FIFO |
10 | 支持任務搶占調度 | 支持 FS的搶占比較簡單,直接計算權重比,所以可以任意配置整數權重值。 | 支持 |
11 | 隊列的ACL權限控制 | 支持 | 支持 |
12 | 限制隊列或集群的最大并發Appplication的個數 | 支持 | 支持 yarn.scheduler.capacity.root.yarn_mobdi_prd.maximum-applications 尖叫提示:區別是Fair Scheduler調度,超出最大并發數比如40后,其他任務處理等待狀態;而Capacity Scheduler超出后任務直,拒絕申請,拋出異常超出最大application的限制 |
13 | 限制基于用戶的最大并發Appplication的個數 | 支持 | 不支持 |
14 | 限制AppMaster在隊列/集群中最大資源使用 | 支持 | 支持 尖叫提示:這個限制的好處是防止集群中運行了很多APPMaster,也就是初始化了很多任務,因為本質上APPMaster就是一個container。進而沒有資源給真正的計算任務運行,造成大量任務處于饑餓狀態。 |
15 | 是否支持動態刷新配置文件 | 支持 | 支持 尖叫提示:刷新資源配置文件后,如增加隊列,調整資源分配,比重,無需重啟,一般10s后自動加載生效 |
16 | 是否支持Node Label | 不支持 | 支持 尖叫提示:Node Label節點分區是一種基于硬件/用途將大型群集劃分為幾個較小的群集的方法。容量和ACL可以添加到分區。 |
17 | 是否支持動態調整container的大小 | 不支持 | 支持 yarn.resourcemanager.auto-update.containers默認值是false,應用程序可以根據工作負載的變化來更新其正在運行的容器的大小。不會殺死任務。 尖叫提示:敲黑板!單個container使用的最大資源不會超過機器分配NM的最大值 |
18 | 規整化因子,很重要 | 支持,FS內置了資源規整化算法,它規定了最小可申請資源量、最大可申請資源量和資源規整化因子,如果應用程序申請的資源量小于最小可申請資源量,則YARN會將其大小改為最小可申請量;如果應用程序申請的資源量大于最大可申請資源量,則會拋出異常,無法申請成功;yarn.scheduler.increment-allocation-mb和yarn.scheduler.increment-allocation-vcores 比如:YARN的container最小資源內存量為3G,規整因子是512Mb,如果一個應用程序申請3.2G內存,則會得到3.5內存。 | 不支持, 動態規劃因子。比如:YARN的container最小資源內存量為3G,規整因子是512Mb,如果一個應用程序申請3.5G內存,則會得到6G內存。Fair Scheduler的資源增加是最小資源的整數倍。相比FS更加可以提高資源的利用率。 |
19 | 配置方式 | Fair Scheduler使用嵌套的xml配置來模仿隊列的層次結構,比傳統的Hadoop風格的配置更加直觀 | 通過.的形式配置a.b.c 尖叫提示:相比后者,Fair Scheduler使用的配置更加方便,直觀,好吧就是簡單。 |
20 | 數據局部特性 | 支持 數據本地計算策略的百分比 yarn.scheduler.fair.locality.threshold.node yarn.scheduler.fair.locality.threshold.rack 默認值是-1,0表示不放棄任何調度機會。正常值配置在0-1之間。 | 支持 Capacity Scheduler利用“延遲調度”來遵守任務局部性約束。有3個級別的位置限制:節點本地,機架本地和關閉交換機。當無法滿足地點要求時,調度程序會計算錯過的機會的數量,并等待此計數達到閾值,然后再將地點約束放寬到下一個級別 尖叫提示:這個對于任務本地化的控制有用,尤其對于帶寬緊張的集群。 |
3.最后的最后
3.1 Fair Scheduler
- Fair Scheduler是資源池概念,大家共享這個池子里面的資源。
- 多隊列多租戶使用時,可以根據業務線,部門,隊列的實際使用情況,根據每個隊列的日均最小使用資源給隊列配置一個min resource,保證這個隊列的任務可以滿足最低運行需求。同時為了防止單個隊列過多占用集群的資源,可以通過設置max resource限制隊列使用資源上線。但是max resource謹慎使用,設置不合理可能降低集群的資源使用率。
- 在滿足了不同隊列最小使用資源的保障后,再根據實際應用場景,給不同的隊列配置不同的權重,最后FS會根據權重來為各個對列的資源池(各個對列還有子隊列)分配資源(這種搶占的按照權重分配的方式本質和capacity 分配一樣)。權重的設置相對capacitye很靈活,想增加權重直接修改權重整數值即可,FS會將各個對列的權重值求和。用當前隊列權重值/總和的形式分配資源,其實也就是按所占的百分比分配資源。這種方式有利于動態調整資源池的使用。同一級別的隊列可以設置權重進行資源分配搶占。同一個父隊列的子隊列之間的資源也可以通過配置權重來進行資源分配搶占,注意子隊列只搶占父隊列的資源。
- 如下,隊列的生產配置情況。可以通過權重,限制并發,最小資源,最大資源,調度策略等方式保證隊列任務的穩定調度。
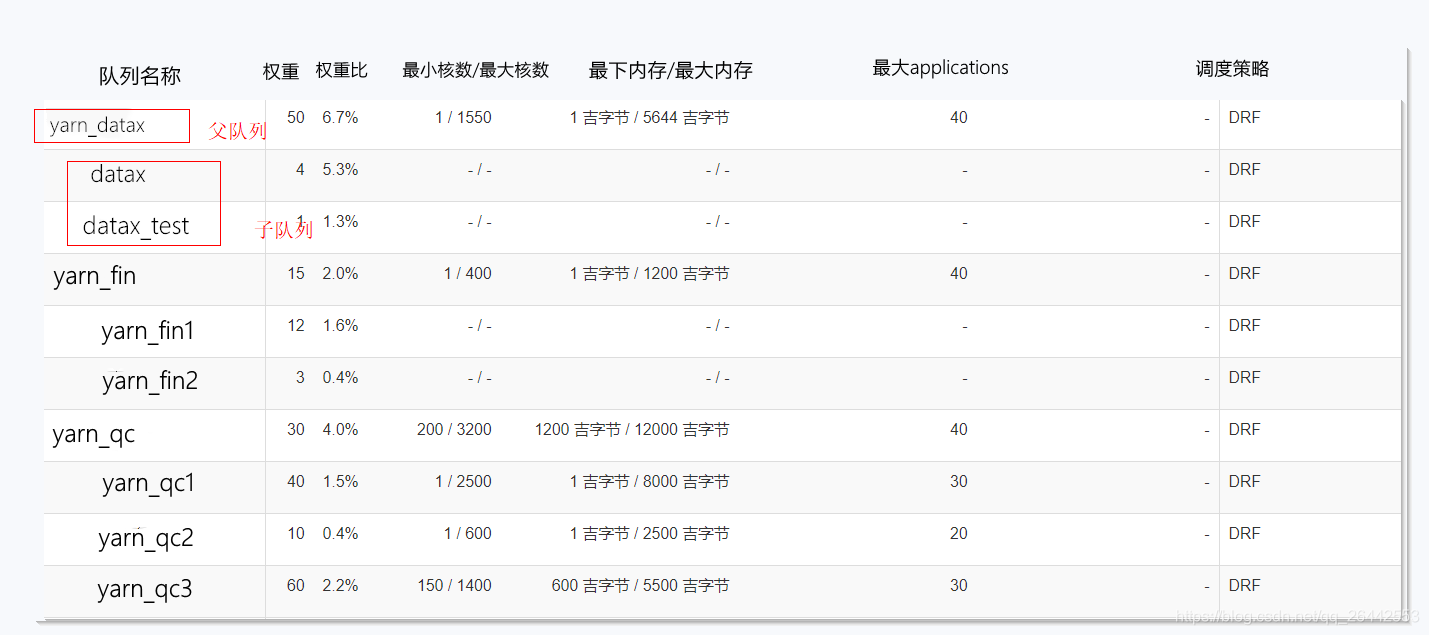
- 可以結合公司實際不同部門的資源使用情況,比如A部門主要晚上用,B部門主要夜里用,配置早晚兩套或者N套資源隊列分配配置文件,通過調度自動更新配置文件,yarn會每隔10s去更新讀取一次配置文件,這樣在無感知的情況下更加有利于調高集群的吞吐率。
3.2 Capacity Scheduler
- 相比Capacity Scheduler 是一個隊列概念,新增一個任務,如果發現資源不夠了,則根據FIFO規則排隊;什么時候資源夠了,再用。
- Fair Scheduler可以配置自動創建pool,但是Capacity則無法創建隊列;其實本質差別就是在于一個是pool共享資源的概念。對于FS而言,可以使用資源池中未被使用的資源,但是Capacity則不允許;所以前者比較靈活,后者相對呆滯。
3.3 建議
如果是中小型集群,上千節點以內,資源比較緊張,建議使用Fair Scheduler,配置簡單,對資源的使用效率也高。相比Fair Scheduler更加靈活,允許作業使用群集中未使用的資源。它通過基于定義的權重來給任務的公平搶占和穩定提供保證。對于中小型集群,這是一個很好的默認設置。
容量調度程序對于資源的管理更加細化,配置起來也是調度器中最麻煩的。其使用資源配額定義隊列。作業不能消耗額外的資源。這需要更多的配置和不斷的試錯,調整容量規劃。所以它更加適合不同工作負載且具有不同需求的大型集群。比如大幾千,上萬,類似阿里巴巴那樣的集群。
參考資料:
https://docs.cloudera.com/cdp/latest/data-migration/topics/cdp-data-migration-yarn-scheduler-migration.html
Apache Hadoop 3.3.4 – YARN Node Labels
本文轉載自微信公眾號「滌生大數據」,作者「滌生大數據」,可以通過以下二維碼關注。

轉載本文請聯系「滌生大數據」公眾號。

















