使用深度強化學(xué)習(xí)預(yù)測股票:DQN 、Double DQN和Dueling Double DQN對比和代碼示例
深度強化學(xué)習(xí)可以將深度學(xué)習(xí)與強化學(xué)習(xí)相結(jié)合:深度學(xué)習(xí)擅長從原始數(shù)據(jù)中學(xué)習(xí)復(fù)雜的表示,強化學(xué)習(xí)則使代理能夠通過反復(fù)試驗在給定環(huán)境中學(xué)習(xí)最佳動作。通過DRL,研究人員和投資者可以開發(fā)能夠分析歷史數(shù)據(jù)的模型,理解復(fù)雜的市場動態(tài),并對股票購買、銷售或持有做出明智的決策。
下面我們一邊寫代碼一邊介紹這些相關(guān)的知識
數(shù)據(jù)集
import numpy as np
import pandas as pd
import copyimport numpy as npimport chainer
import chainer.functions as F
import chainer.links as Lfrom plotly import tools
from plotly.graph_objs import *
from plotly.offline import init_notebook_mode, iplot, iplot_mpl
from tqdm import tqdm_notebook as tqdminit_notebook_mode()這里主要使用使用Jupyter notebook和plotly進行可視化,所以需要一些額外的設(shè)置,下面開始讀取數(shù)據(jù)
try:
data = pd.read_csv('../input/Data/Stocks/goog.us.txt')
data['Date'] = pd.to_datetime(data['Date'])
data = data.set_index('Date')except (FileNotFoundError): import datetime
import pandas_datareader as pdr
from pandas import Series, DataFrame start = datetime.datetime(2010, 1, 1)
end = datetime.datetime(2017, 1, 11) data = pdr.get_data_yahoo("AAPL", start, end)print(data.index.min(), data.index.max())split_index = int(len(data)/2)
date_split = data.index[split_index]
train = data[:split_index]
test = data[split_index:]#date_split = '2016-01-01'
date_split = '2016-01-01'
train = data[:date_split]
test = data[date_split:]
print(len(data), len(train), len(test))
display(data)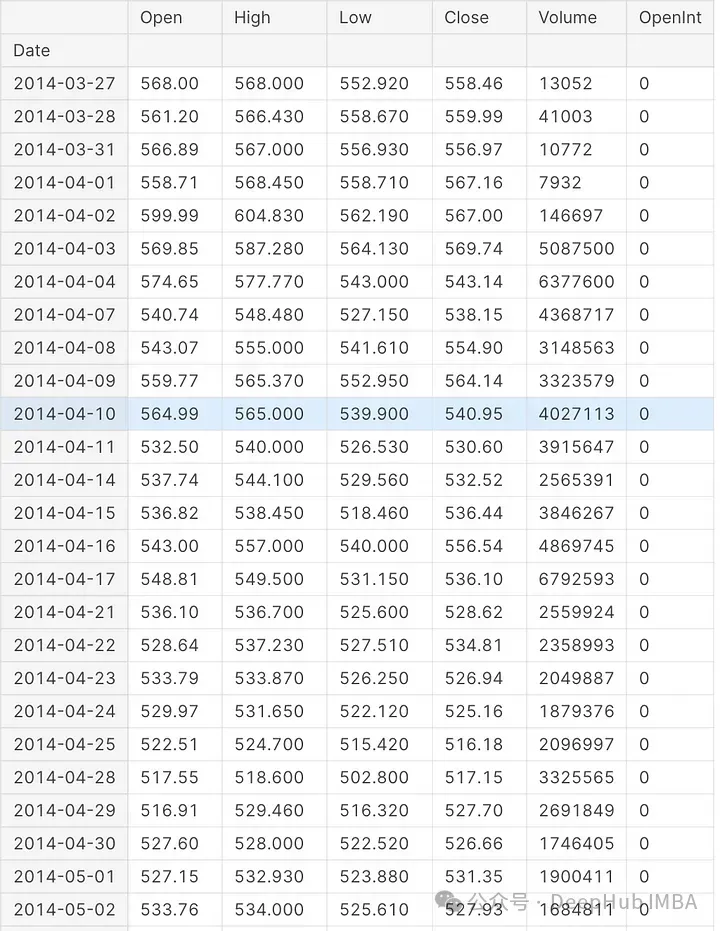
代碼從數(shù)據(jù)集中讀取數(shù)據(jù)。進行測試和驗證集的拆分,然后使用' display '函數(shù),代碼在Jupyter筆記本中顯示導(dǎo)入的數(shù)據(jù)。
def plot_train_test(train, test, date_split):
data = [
Candlestick(x=train.index, open=train['Open'], high=train['High'], low=train['Low'], close=train['Close'], name='train'),
Candlestick(x=test.index, open=test['Open'], high=test['High'], low=test['Low'], close=test['Close'], name='test')
]
layout = {
'shapes': [
{'x0': date_split, 'x1': date_split, 'y0': 0, 'y1': 1, 'xref': 'x', 'yref': 'paper', 'line': {'color': 'rgb(0,0,0)', 'width': 1}}
],
'annotations': [
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'left', 'text': ' test data'},
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'right', 'text': 'train data '}
]
}
figure = Figure(data=data, layout=layout)
iplot(figure)這段代碼定義了一個名為plot_train_test的函數(shù),該函數(shù)使用Python繪圖庫Plotly創(chuàng)建可視化圖。基于指定的日期,圖表將股票數(shù)據(jù)分為訓(xùn)練集和測試集。輸入?yún)?shù)包括train、test和date_split。
可視化結(jié)果如下:
plot_train_test(train, test, date_split)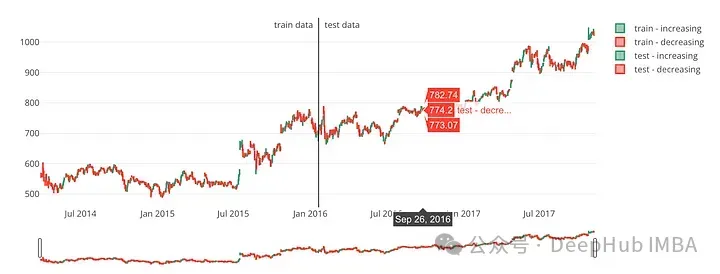
環(huán)境
下面我們開始編寫強化學(xué)習(xí)相關(guān)的內(nèi)容
class Environment:
def __init__(self, data, history_t=90):
self.data = data
self.history_t = history_t
self.reset()
def reset(self):
self.t = 0
self.done = False
self.profits = 0
self.positions = []
self.position_value = 0
self.history = [0 for _ in range(self.history_t)]
return [self.position_value] + self.history # obs
def step(self, act):
reward = 0
# act = 0: stay, 1: buy, 2: sell
if act == 1:
self.positions.append(self.data.iloc[self.t, :]['Close'])
elif act == 2: # sell
if len(self.positions) == 0:
reward = -1
else:
profits = 0
for p in self.positions:
profits += (self.data.iloc[self.t, :]['Close'] - p)
reward += profits
self.profits += profits
self.positions = []
# set next time
self.t += 1
self.position_value = 0
for p in self.positions:
self.position_value += (self.data.iloc[self.t, :]['Close'] - p)
self.history.pop(0)
self.history.append(self.data.iloc[self.t, :]['Close'] - self.data.iloc[(self.t-1), :]['Close'])
# clipping reward
if reward > 0:
reward = 1
elif reward < 0:
reward = -1
return [self.position_value] + self.history, reward, self.done, self.profits # obs, reward, done, profits首先定義強化學(xué)習(xí)的環(huán)境,這里的Environment的類模擬了一個簡單的交易環(huán)境。使用歷史股票價格數(shù)據(jù),代理可以根據(jù)這些數(shù)據(jù)決定是否購買、出售或持有股票。
init()接受兩個參數(shù):data,表示股票價格數(shù)據(jù);history_t,定義環(huán)境應(yīng)該維持多少時間步長。通過設(shè)置data和history_t值并調(diào)用reset(),構(gòu)造函數(shù)初始化了環(huán)境。
Reset()初始化或重置環(huán)境的內(nèi)部狀態(tài)變量,包括當(dāng)前時間步長(self.t)、完成標志、總利潤、未平倉頭寸、頭寸值和歷史價格。該方法返回由頭寸價值和價格歷史組成的觀測值。
step()方法,可以基于一個動作更新環(huán)境的狀態(tài)。動作用整數(shù)表示:0表示持有,1表示購買,2表示出售。如果代理人決定買入,股票的當(dāng)前收盤價將被添加到頭寸列表中。一旦經(jīng)紀人決定賣出,該方法計算每個未平倉頭寸的利潤或損失,并相應(yīng)地更新利潤變量。然后,所有未平倉頭寸被平倉。根據(jù)賣出行為中產(chǎn)生的利潤或損失,獎勵被削減到- 1,0或1。
代理可以使用Environment類學(xué)習(xí)并根據(jù)歷史股票價格數(shù)據(jù)做出決策,Environment類模擬股票交易環(huán)境。在受控環(huán)境中,可以訓(xùn)練強化學(xué)習(xí)代理來制定交易策略。
env = Environment(train)
print(env.reset())
for _ in range(3):
pact = np.random.randint(3)
print(env.step(pact))

DQN
def train_dqn(env, epoch_num=50):
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, output_size)
) def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
y = self.fc3(h)
return y
def reset(self):
self.zerograds()
Q = Q_Network(input_size=env.history_t+1, hidden_size=100, output_size=3)
Q_ast = copy.deepcopy(Q)
optimizer = chainer.optimizers.Adam()
optimizer.setup(Q)
step_max = len(env.data)-1
memory_size = 200
batch_size = 20
epsilon = 1.0
epsilon_decrease = 1e-3
epsilon_min = 0.1
start_reduce_epsilon = 200
train_freq = 10
update_q_freq = 20
gamma = 0.97
show_log_freq = 5 memory = []
total_step = 0
total_rewards = []
total_losses = [] start = time.time()
for epoch in range(epoch_num): pobs = env.reset()
step = 0
done = False
total_reward = 0
total_loss = 0
while not done and step < step_max: # select act
pact = np.random.randint(3)
if np.random.rand() > epsilon:
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data) # act
obs, reward, done, profit = env.step(pact) # add memory
memory.append((pobs, pact, reward, obs, done))
if len(memory) > memory_size:
memory.pop(0) # train or update q
if len(memory) == memory_size:
if total_step % train_freq == 0:
shuffled_memory = np.random.permutation(memory)
memory_idx = range(len(shuffled_memory))
for i in memory_idx[::batch_size]:
batch = np.array(shuffled_memory[i:i+batch_size])
b_pobs = np.array(batch[:, 0].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_pact = np.array(batch[:, 1].tolist(), dtype=np.int32)
b_reward = np.array(batch[:, 2].tolist(), dtype=np.int32)
b_obs = np.array(batch[:, 3].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_done = np.array(batch[:, 4].tolist(), dtype=np.bool)
q = Q(b_pobs)
maxq = np.max(Q_ast(b_obs).data, axis=1)
target = copy.deepcopy(q.data)
for j in range(batch_size):
target[j, b_pact[j]] = b_reward[j]+gamma*maxq[j]*(not b_done[j])
Q.reset()
deephub_loss = F.mean_squared_error(q, target)
total_loss += loss.data
loss.backward()
optimizer.update()
if total_step % update_q_freq == 0:
Q_ast = copy.deepcopy(Q) # epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease # next step
total_reward += reward
pobs = obs
step += 1
total_step += 1
total_rewards.append(total_reward)
total_losses.append(total_loss)
if (epoch+1) % show_log_freq == 0:
log_reward = sum(total_rewards[((epoch+1)-show_log_freq):])/show_log_freq
log_loss = sum(total_losses[((epoch+1)-show_log_freq):])/show_log_freq
elapsed_time = time.time()-start
print('\t'.join(map(str, [epoch+1, epsilon, total_step, log_reward, log_loss, elapsed_time])))
start = time.time()
return Q, total_losses, total_rewards這段代碼定義了一個函數(shù)train_dqn(),它為一個簡單的股票交易環(huán)境訓(xùn)練一個Deep Q-Network (DQN)。該函數(shù)接受兩個參數(shù):一個是env參數(shù),表示交易環(huán)境;另一個是epoch_num參數(shù),指定要訓(xùn)練多少epoch。
代碼定義了一個Q_Network類,它是Chainer的Chain類的一個子類。在Q-Network中,有三個完全連接的層,前兩層具有ReLU激活函數(shù)。模型梯度通過reset()方法歸零。
創(chuàng)建Q- network的兩個實例Q和Q_ast,以及用于更新模型參數(shù)的Adam優(yōu)化器。對于DQN訓(xùn)練,定義了幾個超參數(shù),包括緩沖區(qū)內(nèi)存大小、批處理大小、epsilon、gamma和更新頻率。
為了跟蹤模型在訓(xùn)練期間的表現(xiàn),在內(nèi)存列表中創(chuàng)建total_rewards和total_losses列表。在每個epoch的開始,環(huán)境被重置,一些變量被初始化。
代理根據(jù)當(dāng)前狀態(tài)和epsilon-greedy探索策略選擇一個動作(持有、買入或賣出)。然后,代理在環(huán)境中執(zhí)行動作,獲得獎勵,并觀察新的狀態(tài)。在緩沖區(qū)中,存儲了經(jīng)驗元組(前一個狀態(tài)、動作、獎勵、新狀態(tài)和完成標志)。
為了訓(xùn)練DQN,當(dāng)緩沖區(qū)滿時,從內(nèi)存中采樣一批經(jīng)驗。利用Q_ast網(wǎng)絡(luò)和Bellman方程,計算了目標q值。損失計算為預(yù)測q值與目標q值之間的均方誤差。計算梯度,優(yōu)化器更新模型參數(shù)。
目標網(wǎng)絡(luò)Q_ast使用主網(wǎng)絡(luò)q的權(quán)值定期更新,隨著智能體的學(xué)習(xí),epsilon值線性減小,促進更多的利用。每個時期,總獎勵和損失都會累積起來,結(jié)果也會被記錄下來。
訓(xùn)練結(jié)束時,train_dqn()返回訓(xùn)練后的Q-Network、總損失和總獎勵。DQN模型可用于根據(jù)輸入的股票價格數(shù)據(jù)和模擬的交易環(huán)境制定交易策略。
dqn, total_losses, total_rewards = train_dqn(Environment(train), epoch_num=25)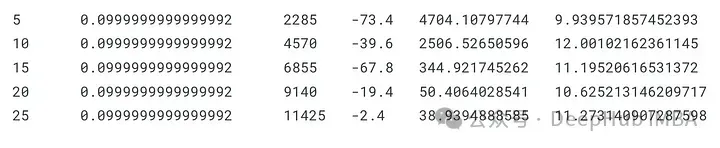
這段代碼使用來自指定環(huán)境的訓(xùn)練數(shù)據(jù)(使用train_dqn函數(shù))訓(xùn)練DQN模型,并返回訓(xùn)練后的模型以及每個訓(xùn)練歷元的總損失和獎勵。
def plot_loss_reward(total_losses, total_rewards):
figure = tools.make_subplots(rows=1, cols=2, subplot_titles=('loss', 'reward'), print_grid=False)
figure.append_trace(Scatter(y=total_losses, mode='lines', line=dict(color='skyblue')), 1, 1)
figure.append_trace(Scatter(y=total_rewards, mode='lines', line=dict(color='orange')), 1, 2)
figure['layout']['xaxis1'].update(title='epoch')
figure['layout']['xaxis2'].update(title='epoch')
figure['layout'].update(height=400, width=900, showlegend=False)
iplot(figure)plot_loss_reward”使用Plotly庫的“make_subplots”函數(shù)創(chuàng)建一個帶有兩個子圖的圖形。在訓(xùn)練周期內(nèi),該圖顯示了損失值和獎勵值的趨勢,提供了對DQN模型性能的洞察。
plot_loss_reward(total_losses, total_rewards)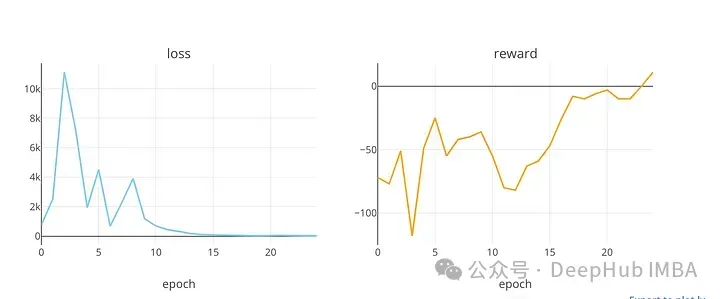
顯示了在訓(xùn)練時期損失和獎勵值的趨勢。在DQN模型(可能用于股票市場預(yù)測)的訓(xùn)練過程中,代碼使用該函數(shù)繪制損失和回報值。
def plot_train_test_by_q(train_env, test_env, Q, algorithm_name):
# train
pobs = train_env.reset()
train_acts = []
train_rewards = []
train_ongoing_profits = []
for _ in range(len(train_env.data)-1):
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data)
train_acts.append(pact)
obs, reward, done, profit = train_env.step(pact)
train_rewards.append(reward)
train_ongoing_profits.append(profit) pobs = obs
train_profits = train_env.profits
# test
pobs = test_env.reset()
test_acts = []
test_rewards = []
test_ongoing_profits = [] for _ in range(len(test_env.data)-1):
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data)
test_acts.append(pact)
deep_hub_obs, reward, done, profit = test_env.step(pact)
test_rewards.append(reward)
test_ongoing_profits.append(profit) pobs = obs
test_profits = test_env.profits
# plot
train_copy = train_env.data.copy()
test_copy = test_env.data.copy()
train_copy['act'] = train_acts + [np.nan]
train_copy['reward'] = train_rewards + [np.nan]
test_copy['act'] = test_acts + [np.nan]
test_copy['reward'] = test_rewards + [np.nan]
train0 = train_copy[train_copy['act'] == 0]
train1 = train_copy[train_copy['act'] == 1]
train2 = train_copy[train_copy['act'] == 2]
test0 = test_copy[test_copy['act'] == 0]
test1 = test_copy[test_copy['act'] == 1]
test2 = test_copy[test_copy['act'] == 2]
act_color0, act_color1, act_color2 = 'gray', 'cyan', 'magenta' data = [
Candlestick(x=train0.index, open=train0['Open'], high=train0['High'], low=train0['Low'], close=train0['Close'], increasing=dict(line=dict(color=act_color0)), decreasing=dict(line=dict(color=act_color0))),
Candlestick(x=train1.index, open=train1['Open'], high=train1['High'], low=train1['Low'], close=train1['Close'], increasing=dict(line=dict(color=act_color1)), decreasing=dict(line=dict(color=act_color1))),
Candlestick(x=train2.index, open=train2['Open'], high=train2['High'], low=train2['Low'], close=train2['Close'], increasing=dict(line=dict(color=act_color2)), decreasing=dict(line=dict(color=act_color2))),
Candlestick(x=test0.index, open=test0['Open'], high=test0['High'], low=test0['Low'], close=test0['Close'], increasing=dict(line=dict(color=act_color0)), decreasing=dict(line=dict(color=act_color0))),
Candlestick(x=test1.index, open=test1['Open'], high=test1['High'], low=test1['Low'], close=test1['Close'], increasing=dict(line=dict(color=act_color1)), decreasing=dict(line=dict(color=act_color1))),
Candlestick(x=test2.index, open=test2['Open'], high=test2['High'], low=test2['Low'], close=test2['Close'], increasing=dict(line=dict(color=act_color2)), decreasing=dict(line=dict(color=act_color2)))
]
title = '{}: train s-reward {}, profits {}, test s-reward {}, profits {}'.format(
deephub_algorithm_name,
int(sum(train_rewards)),
int(train_profits),
int(sum(test_rewards)),
int(test_profits)
)
layout = {
'title': title,
'showlegend': False,
'shapes': [
{'x0': date_split, 'x1': date_split, 'y0': 0, 'y1': 1, 'xref': 'x', 'yref': 'paper', 'line': {'color': 'rgb(0,0,0)', 'width': 1}}
],
'annotations': [
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'left', 'text': ' test data'},
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'right', 'text': 'train data '}
]
}
figure = Figure(data=data, layout=layout)
iplot(figure)
return train_ongoing_profits, test_ongoing_profitsPlot_train_test_by_q()將訓(xùn)練好的DQN模型在訓(xùn)練和測試數(shù)據(jù)集上的交易行為和性能可視化。
使用訓(xùn)練好的Q-Network,該函數(shù)初始化環(huán)境并迭代訓(xùn)練和測試數(shù)據(jù)。對于這兩個數(shù)據(jù)集,它都會累積行動、獎勵和持續(xù)利潤。
為了分析或比較算法的性能,該函數(shù)返回訓(xùn)練和測試數(shù)據(jù)集的持續(xù)利潤。
train_profits, test_profits = plot_train_test_by_q(Environment(train), Environment(test), dqn, 'DQN')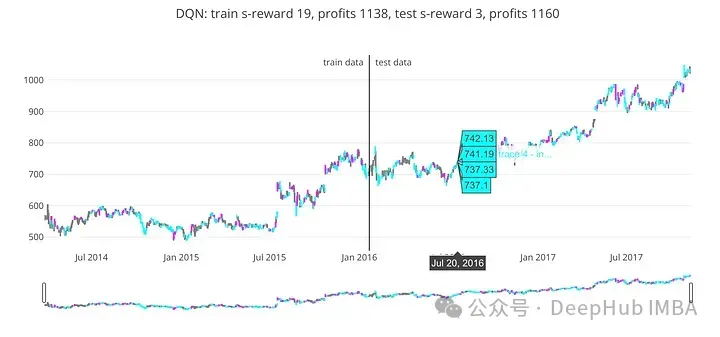
基于DQN模型的預(yù)測,' train_profits '變量接收從訓(xùn)練數(shù)據(jù)中獲得的利潤。' test_profits '接收測試數(shù)據(jù)作為DQN模型預(yù)測的結(jié)果而獲得的利潤。
代碼在訓(xùn)練和測試數(shù)據(jù)上評估訓(xùn)練好的DQN模型,并計算每個數(shù)據(jù)集上獲得的利潤。這種評價可能有助于確定DQN模型的準確性和有效性。
我們還可以將,將DQN模型的性能與用于股市預(yù)測的“買入并持有”策略進行比較。Matplotlib的' plt '模塊用于生成繪圖。
plt.figure(figsize=(23,8))
plt.plot(data.index,((data['Close']-data['Close'][0])/data['Close'][-1]), label='buy and hold')
plt.plot(train.index, ([0] + train_profits)/data['Close'][-1], label='rl (train)')
plt.plot(test.index, (([0] + test_profits) + train_profits[-1])/data['Close'][-1], label='rl (test)')
plt.ylabel('relative gain')
plt.legend()
plt.show()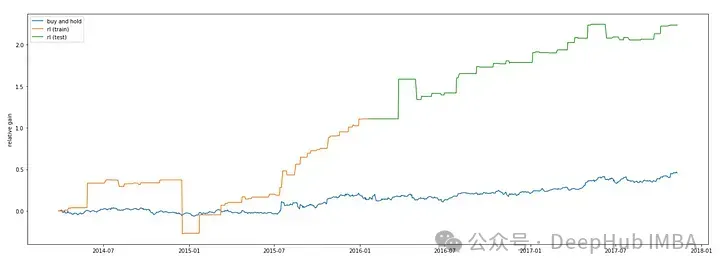
代碼繪制了在訓(xùn)練數(shù)據(jù)上獲得的利潤。在該圖中,x軸表示訓(xùn)練數(shù)據(jù)的指數(shù),y軸表示DQN模型預(yù)測的相對收益。相對收益是通過將利潤除以輸入數(shù)據(jù)中的最后收盤價來計算的。
使用DQN模型,代碼繪制了在測試數(shù)據(jù)上獲得的利潤。x軸表示測試數(shù)據(jù)的指數(shù),y軸表示DQN模型預(yù)測的相對利潤增益。通過將訓(xùn)練利潤相加并除以導(dǎo)入數(shù)據(jù)中的最后收盤價來計算相對收益。該圖的標簽為“rl (test)”。
使用Matplotlib庫的“show”函數(shù)顯示該圖。在訓(xùn)練和測試數(shù)據(jù)上,該圖顯示了“買入并持有”策略和DQN模型預(yù)測的相對利潤增益。將DQN模型與“買入并持有”等簡單策略進行比較,可以深入了解其有效性。
Double DQN
Double Deep Q-Network (DDQN) 是一種用于強化學(xué)習(xí)中的深度學(xué)習(xí)算法,特別是在處理離散動作空間的 Q-Learning 問題時非常有效。DDQN 是對傳統(tǒng) Deep Q-Network (DQN) 的一種改進,旨在解決 DQN 在估計 Q 值時可能存在的過高估計(overestimation)問題。
DDQN 使用一個額外的神經(jīng)網(wǎng)絡(luò)來評估選取最大 Q 值的動作。它不再直接使用目標 Q 網(wǎng)絡(luò)預(yù)測的最大 Q 值來更新當(dāng)前 Q 網(wǎng)絡(luò)的 Q 值,而是使用當(dāng)前 Q 網(wǎng)絡(luò)選擇的動作在目標 Q 網(wǎng)絡(luò)中預(yù)測的 Q 值來更新。這種方法通過減少動作選擇與目標 Q 值計算之間的相關(guān)性,有助于減輕 Q 值的過高估計問題。
def train_ddqn(env, epoch_num=50):
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, output_size)
) def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
y = self.fc3(h)
return y
def reset(self):
self.zerograds()
Q = Q_Network(input_size=env.history_t+1, hidden_size=100, output_size=3)
Q_ast = copy.deepcopy(Q)
optimizer = chainer.optimizers.Adam()
optimizer.setup(Q)
step_max = len(env.data)-1
memory_size = 200
batch_size = 50
epsilon = 1.0
epsilon_decrease = 1e-3
epsilon_min = 0.1
start_reduce_epsilon = 200
train_freq = 10
update_q_freq = 20
gamma = 0.97
show_log_freq = 5 memory = []
total_step = 0
total_rewards = []
total_losses = [] start = time.time()
for epoch in range(epoch_num):
pobs = env.reset()
step = 0
done = False
total_reward = 0
total_loss = 0
while not done and step < step_max: # select act
pact = np.random.randint(3)
if np.random.rand() > epsilon:
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data) # act
obs, reward, done, profit = env.step(pact) # add memory
memory.append((pobs, pact, reward, obs, done))
if len(memory) > memory_size:
memory.pop(0) # train or update q
if len(memory) == memory_size:
if total_step % train_freq == 0:
deep_hub_shuffled_memory = np.random.permutation(memory)
memory_idx = range(len(shuffled_memory))
for i in memory_idx[::batch_size]:
batch = np.array(shuffled_memory[i:i+batch_size])
b_pobs = np.array(batch[:, 0].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_pact_deephub = np.array(batch[:, 1].tolist(), dtype=np.int32)
b_reward = np.array(batch[:, 2].tolist(), dtype=np.int32)
b_obs = np.array(batch[:, 3].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_done = np.array(batch[:, 4].tolist(), dtype=np.bool)
q = Q(b_pobs)
""" <<< DQN -> Double DQN
maxq = np.max(Q_ast(b_obs).data, axis=1)
=== """
indices = np.argmax(q.data, axis=1)
maxqs = Q_ast(b_obs).data
""" >>> """
target = copy.deepcopy(q.data)
for j in range(batch_size):
""" <<< DQN -> Double DQN
target[j, b_pact[j]] = b_reward[j]+gamma*maxq[j]*(not b_done[j])
=== """
target[j, b_pact[j]] = b_reward[j]+gamma*maxqs[j, indices[j]]*(not b_done[j])
""" >>> """
Q.reset()
loss = F.mean_squared_error(q, target)
total_loss += loss.data
loss.backward()
optimizer.update()
if total_step % update_q_freq == 0:
Q_ast = copy.deepcopy(Q) # epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease # next step
total_reward += reward
pobs = obs
step += 1
total_step += 1
total_rewards.append(total_reward)
total_losses.append(total_loss)
if (epoch+1) % show_log_freq == 0:
log_reward = sum(total_rewards[((epoch+1)-show_log_freq):])/show_log_freq
log_loss = sum(total_losses[((epoch+1)-show_log_freq):])/show_log_freq
elapsed_time = time.time()-start
print('\t'.join(map(str, [epoch+1, epsilon, total_step, log_reward, log_loss, elapsed_time])))
start = time.time()
return Q, total_losses, total_rewards上面代碼定義了一個函數(shù)train_ddqn(),該函數(shù)訓(xùn)練Double Deep Q-Network (DDQN)來解決交易環(huán)境。
ddqn, total_losses, total_rewards = train_ddqn(Environment(train), epoch_num=50)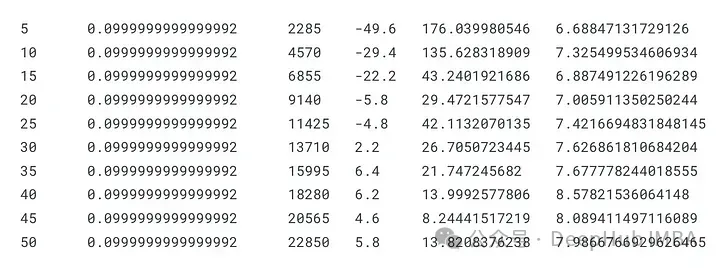
plot_loss_reward(total_losses, total_rewards)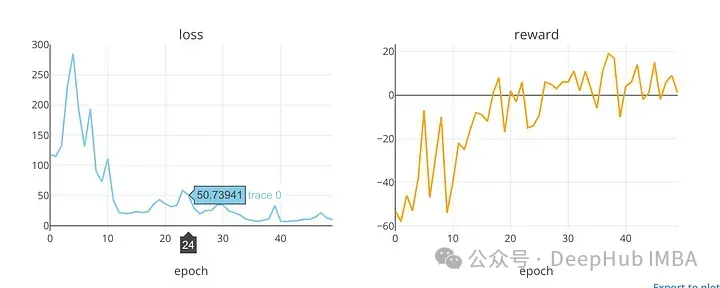
可視化了在訓(xùn)練時期的損失和獎勵值的趨勢。在DDQN模型(可能用于預(yù)測股票市場價格)的訓(xùn)練過程中,該函數(shù)繪制損失和回報值。
train_profits, test_profits = plot_train_test_by_q(Environment(train), Environment(test), ddqn, 'Double DQN')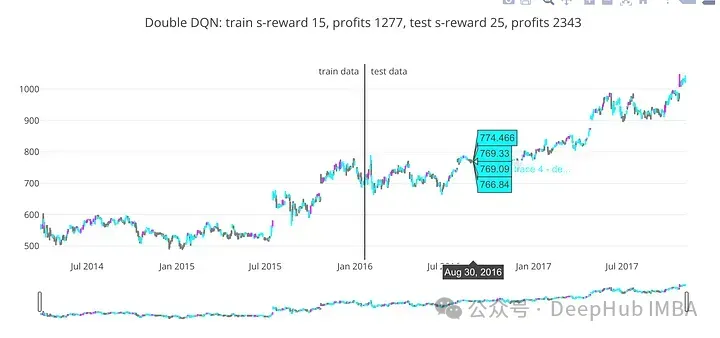
在訓(xùn)練和測試數(shù)據(jù)上評估訓(xùn)練后的DDQN模型的性能,為每個數(shù)據(jù)集獲得利潤。對于股票市場預(yù)測或其他需要強化學(xué)習(xí)的決策任務(wù),此評估的結(jié)果可能有用。
plt.figure(figsize=(23,8))
plt.plot(data.index,((data['Close']-data['Close'][0])/data['Close'][-1]), label='buy and hold')
plt.plot(train.index, ([0] + train_profits)/data['Close'][-1], label='rl (train)')
plt.plot(test.index, (([0] + test_profits) + train_profits[-1])/data['Close'][-1], label='rl (test)')
plt.ylabel('relative gain')
plt.legend()
plt.show()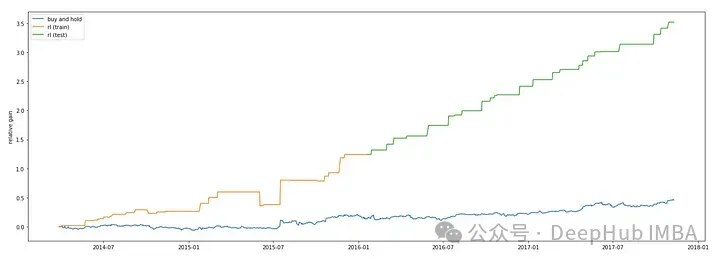
可以看到Double DQN要更高一些。這和Double Deep Q-Network的介紹: (DDQN)通過使用兩個神經(jīng)網(wǎng)絡(luò)來分別估計當(dāng)前策略選擇的動作和目標 Q 值的最大動作,有效解決了傳統(tǒng) DQN 中的 Q 值過高估計問題,提高了在離散動作空間下的強化學(xué)習(xí)性能和穩(wěn)定性。是相吻合的
Dueling Double DQN
Dueling Double Deep Q-Network (Dueling DDQN) 是一種結(jié)合了兩種技術(shù)的強化學(xué)習(xí)算法:Dueling網(wǎng)絡(luò)結(jié)構(gòu)和Double DQN。它旨在進一步提高 Q-Learning 的效率和穩(wěn)定性,特別是在處理離散動作空間的問題時非常有效。
def train_dddqn(env, epoch_num=50): """ <<< Double DQN -> Dueling Double DQN
class Q_Network(chainer.Chain): def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, output_size)
) def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
y = self.fc3(h)
return y def reset(self):
self.zerograds()
=== """
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, hidden_size//2),
fc4 = L.Linear(hidden_size, hidden_size//2),
state_value = L.Linear(hidden_size//2, 1),
advantage_value = L.Linear(hidden_size//2, output_size)
)
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
hs = F.relu(self.fc3(h))
ha = F.relu(self.fc4(h))
state_value = self.state_value(hs)
advantage_value = self.advantage_value(ha)
advantage_mean = (F.sum(advantage_value, axis=1)/float(self.output_size)).reshape(-1, 1)
q_value = F.concat([state_value for _ in range(self.output_size)], axis=1) + (advantage_value - F.concat([advantage_mean for _ in range(self.output_size)], axis=1))
return q_value
def reset(self):
self.zerograds()
""" >>> """
Q = Q_Network(input_size=env.history_t+1, hidden_size=100, output_size=3)
Q_ast = copy.deepcopy(Q)
optimizer = chainer.optimizers.Adam()
optimizer.setup(Q) step_max = len(env.data)-1
memory_size = 200
batch_size = 50
epsilon = 1.0
epsilon_decrease = 1e-3
epsilon_min = 0.1
start_reduce_epsilon = 200
train_freq = 10
update_q_freq = 20
gamma = 0.97
show_log_freq = 5 memory = []
total_step = 0
total_rewards = []
total_losses = []
start = time.time()
for epoch in range(epoch_num):
pobs = env.reset()
step = 0
done = False
total_reward = 0
total_loss = 0
while not done and step < step_max: # select act
pact = np.random.randint(3)
if np.random.rand() > epsilon:
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data) # act
obs, reward, done, profit = env.step(pact) # add memory
memory.append((pobs, pact, reward, obs, done))
if len(memory) > memory_size:
memory.pop(0) # train or update q
if len(memory) == memory_size:
if total_step % train_freq == 0:
shuffled_memory = np.random.permutation(memory)
memory_idx = range(len(shuffled_memory))
for i in memory_idx[::batch_size]:
deephub_batch = np.array(shuffled_memory[i:i+batch_size])
b_pobs = np.array(batch[:, 0].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_pact = np.array(batch[:, 1].tolist(), dtype=np.int32)
b_reward = np.array(batch[:, 2].tolist(), dtype=np.int32)
b_obs = np.array(batch[:, 3].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_done = np.array(batch[:, 4].tolist(), dtype=np.bool) q = Q(b_pobs)
""" <<< DQN -> Double DQN
maxq = np.max(Q_ast(b_obs).data, axis=1)
=== """
indices = np.argmax(q.data, axis=1)
maxqs = Q_ast(b_obs).data
""" >>> """
target = copy.deepcopy(q.data)
for j in range(batch_size):
""" <<< DQN -> Double DQN
target[j, b_pact[j]] = b_reward[j]+gamma*maxq[j]*(not b_done[j])
=== """
target[j, b_pact[j]] = b_reward[j]+gamma*maxqs[j, indices[j]]*(not b_done[j])
""" >>> """
Q.reset()
loss = F.mean_squared_error(q, target)
total_loss += loss.data
loss.backward()
optimizer.update()
if total_step % update_q_freq == 0:
Q_ast = copy.deepcopy(Q) # epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease # next step
total_reward += reward
pobs = obs
step += 1
total_step += 1
total_rewards.append(total_reward)
total_losses.append(total_loss)
if (epoch+1) % show_log_freq == 0:
log_reward = sum(total_rewards[((epoch+1)-show_log_freq):])/show_log_freq
log_loss = sum(total_losses[((epoch+1)-show_log_freq):])/show_log_freq
elapsed_time = time.time()-start
print('\t'.join(map(str, [epoch+1, epsilon, total_step, log_reward, log_loss, elapsed_time])))
start = time.time()
return Q, total_losses, total_rewards在call方法中,前兩層在兩個流之間共享,然后分成兩個獨立的流。狀態(tài)價值流有一個輸出單個值的額外線性層(state_value),而優(yōu)勢價值流有一個為每個動作輸出值的額外線性層(advantage_value)。最終的q值由狀態(tài)值和優(yōu)勢值結(jié)合計算,并減去平均優(yōu)勢值以保持穩(wěn)定性。代碼的其余部分與Double DQN實現(xiàn)非常相似。
dddqn, total_losses, total_rewards = train_dddqn(Environment(train), epoch_num=25)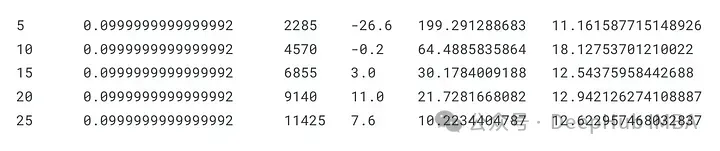
plot_loss_reward(total_losses, total_rewards)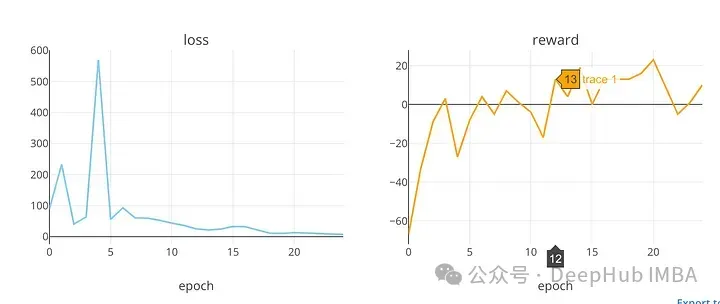
train_profits, test_profits = plot_train_test_by_q(Environment(train), Environment(test), dddqn, 'Dueling Double DQN')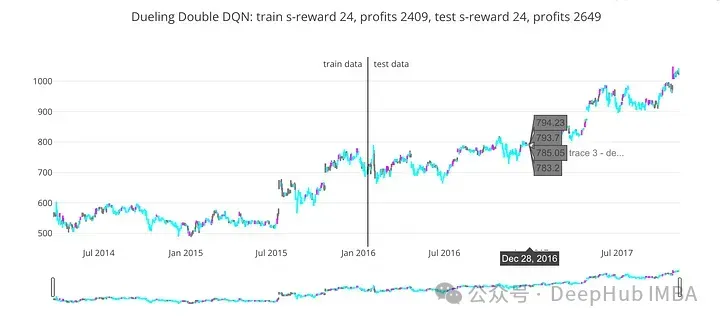
plt.figure(figsize=(23,8))
plt.plot(data.index,((data['Close']-data['Close'][0])/data['Close'][-1]), label='buy and hold')
plt.plot(train.index, ([0] + train_profits)/data['Close'][-1], label='rl (train)')
plt.plot(test.index, (([0] + test_profits) + train_profits[-1])/data['Close'][-1], label='rl (test)')
plt.plot(test.index, (([0] + test_profits) - data['Close'][0] + data['Close'][len(train_profits)])/data['Close'][-1], label='rl (test)')
plt.ylabel('relative gain')
plt.legend()
plt.show()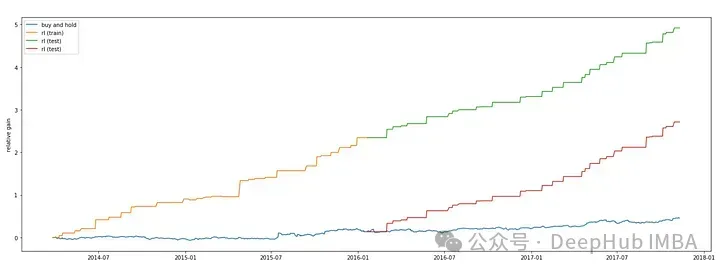
Dueling Double Deep Q-Network (Dueling DDQN) 是一種結(jié)合了 Dueling 網(wǎng)絡(luò)結(jié)構(gòu)和 Double DQN 的強化學(xué)習(xí)算法。它通過將 Q 函數(shù)分解為狀態(tài)值函數(shù)和優(yōu)勢函數(shù)來提高效率,同時利用 Double DQN 的思想來減少 Q 值的過高估計,從而在處理離散動作空間下的強化學(xué)習(xí)問題中表現(xiàn)出色。
總結(jié)
讓我們對傳統(tǒng)的 Deep Q-Network (DQN), Double DQN, Dueling DQN 和 Dueling Double DQN 進行對比總結(jié),看看它們各自的特點和優(yōu)劣勢。
1、Deep Q-Network (DQN)
特點
- 使用深度神經(jīng)網(wǎng)絡(luò)來估計 Q 函數(shù),從而學(xué)習(xí)到每個狀態(tài)下每個動作的價值。
- 使用經(jīng)驗回放和固定 Q 目標網(wǎng)絡(luò)來提高穩(wěn)定性和收斂性。
優(yōu)點
- 引入深度學(xué)習(xí)提高了 Q 函數(shù)的表示能力,能夠處理復(fù)雜的狀態(tài)和動作空間。
- 經(jīng)驗回放和固定 Q 目標網(wǎng)絡(luò)有助于穩(wěn)定訓(xùn)練過程,減少樣本間的相關(guān)性。
缺點
- 存在 Q 值的過高估計問題,尤其是在動作空間較大時更為明顯,這可能導(dǎo)致訓(xùn)練不穩(wěn)定和性能下降。
2、Double Deep Q-Network (Double DQN)
特點
- 解決了 DQN 中 Q 值過高估計的問題。
- 引入一個額外的目標 Q 網(wǎng)絡(luò)來計算目標 Q 值,減少更新時的相關(guān)性。
優(yōu)點
- 減少了 Q 值的過高估計,提高了訓(xùn)練的穩(wěn)定性和收斂性。
缺點
- 算法結(jié)構(gòu)相對簡單,對于某些復(fù)雜問題可能需要更高的表示能力。
3、Dueling Double Deep Q-Network (Dueling DDQN)
特點
- 結(jié)合了 Dueling 網(wǎng)絡(luò)結(jié)構(gòu)和 Double DQN 的優(yōu)勢。
- 使用 Dueling 網(wǎng)絡(luò)結(jié)構(gòu)來分解 Q 函數(shù),提高了效率和學(xué)習(xí)表示能力。
使用 Double DQN 的思想來減少 Q 值的過高估計問題。
優(yōu)點
- 綜合了兩種技術(shù)的優(yōu)勢,能夠在更廣泛的問題空間中表現(xiàn)出色。
- 提高了訓(xùn)練的穩(wěn)定性和效率,有助于更快地收斂到較好的策略。
缺點
- 算法實現(xiàn)和調(diào)優(yōu)可能比單一 DQN 及其改進版更復(fù)雜。
總結(jié)比較
- 效果和穩(wěn)定性:Dueling DDQN 在處理動作空間較大的問題時表現(xiàn)出更高的效率和穩(wěn)定性,因為它們能夠更有效地分離狀態(tài)值和動作優(yōu)勢。
- 過高估計問題:Dueling DDQN 解決了傳統(tǒng) DQN 中 Q 值過高估計的問題,其中 Double DQN 通過目標網(wǎng)絡(luò)降低相關(guān)性,而 Dueling 結(jié)構(gòu)則通過優(yōu)勢函數(shù)減少過高估計。
- 復(fù)雜性:Dueling DDQN 相對于傳統(tǒng) DQN 和 Double DQN 更復(fù)雜,需要更多的實現(xiàn)和理解成本,但也帶來了更好的性能。
傳統(tǒng) DQN 適用于簡單的強化學(xué)習(xí)任務(wù),而 Double DQN、Dueling DDQN 則適用于更復(fù)雜和具有挑戰(zhàn)性的問題,根據(jù)問題的特性選擇合適的算法可以有效提升訓(xùn)練效率和性能。
最后我們也看到,深度強化學(xué)習(xí)預(yù)測股票是可行的,因為他不再預(yù)測具體的股票價格,而是針對收益預(yù)測買進,賣出和持有,我們這里只是使用了股票本身的數(shù)據(jù),如果有更多的外生數(shù)據(jù)那么強化學(xué)習(xí)應(yīng)該可以模擬更準確的人工操作。