僅需2張圖,AI便可生成完整運動過程
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
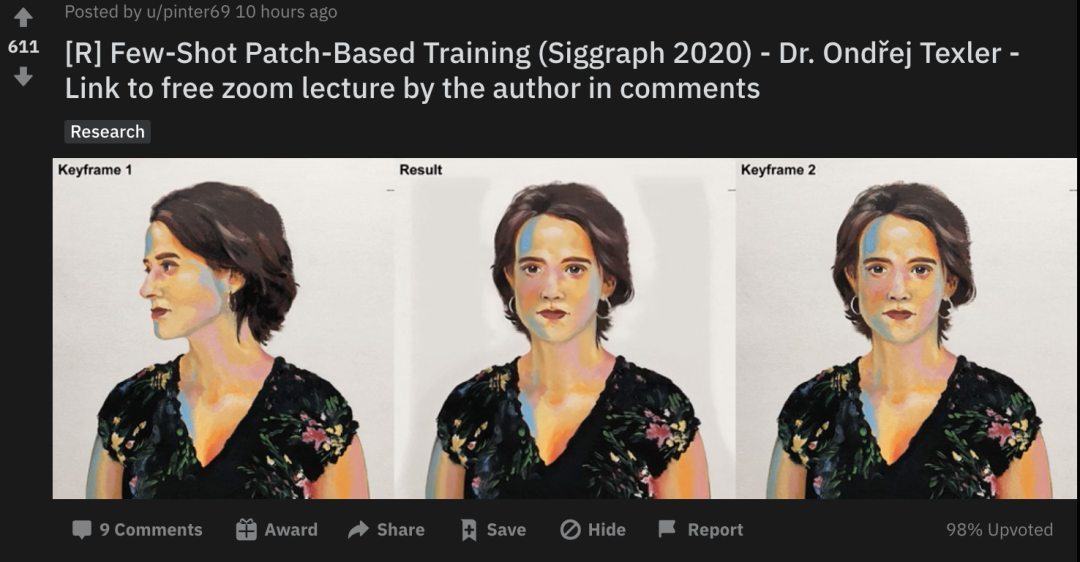
先給一張側臉(關鍵幀1):

再給一張正臉(關鍵幀2):

然后僅僅根據這兩張圖片,AI處理了一下,便能生成整個運動過程:

而且不只是簡單的那種,連在運動過程中的眨眼動作也“照顧”得很到位。
效果一出,便在Reddit上引發了不少熱議:
僅需2個關鍵幀,如何實現完整運動?
不需要冗長的訓練過程。
不需要大量的訓練數據集。
這是論文作者對本次工作提出的兩大亮點。
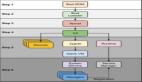
具體而言,這項工作就是基于關鍵幀將視頻風格化。
先輸入一個視頻序列 I ,它由N個幀組織,每一幀都有一個掩膜Mi來劃分感興趣的區域。
與此前方法不同的是,這種風格遷移是以隨機順序進行的,不需要等待順序靠前的幀先完成風格化,也不需要對來自不同關鍵幀的風格化內容進行顯式合并。
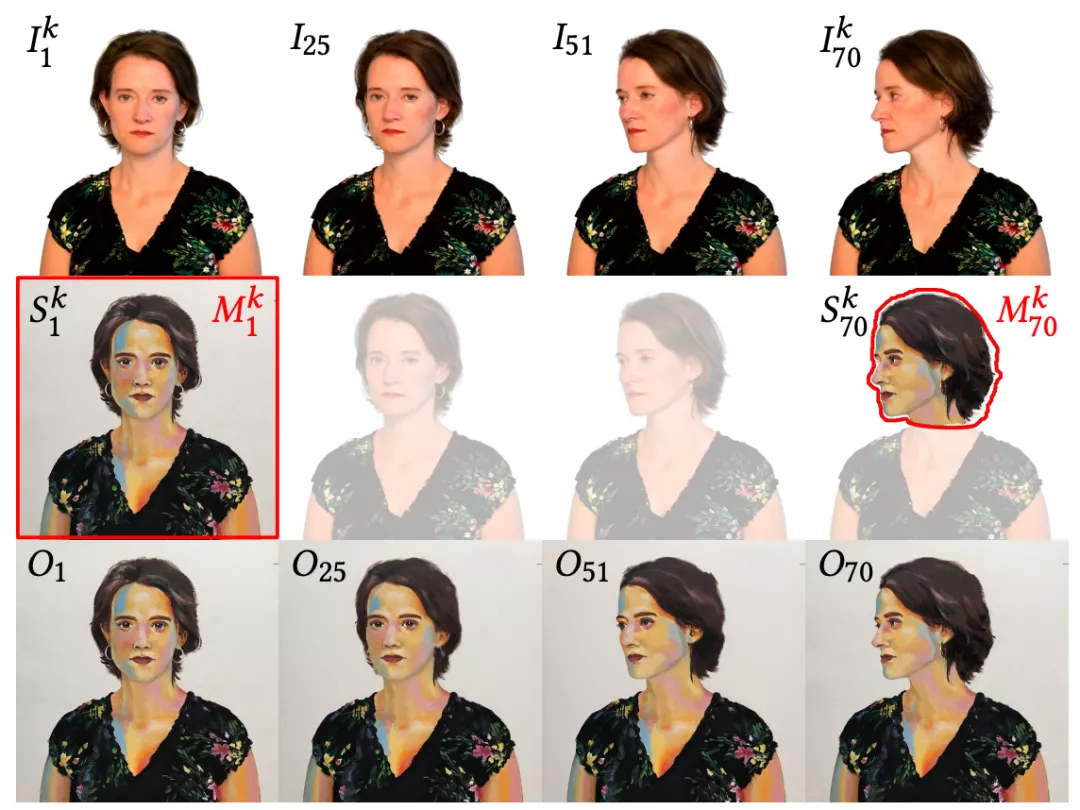
也就是說,該方法實際上是一種翻譯過濾器,可以快速從幾個異構的手繪示例 Sk 中學習風格,并將其“翻譯”給視頻序列 I 中的任何一幀。
這個圖像轉換框架基于 U-net 實現。并且,研究人員采用基于圖像塊 (patch-based)的訓練方式和抑制視頻閃爍的解決方案,解決了少樣本訓練和時間一致性的問題。
而為了避免過擬合,研究人員采用了基于圖像塊的訓練策略。
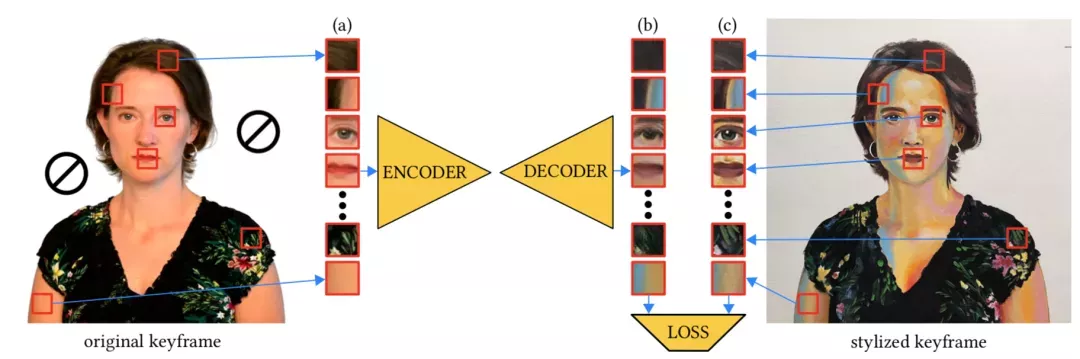
從原始關鍵幀(Ik)中隨機抽取一組圖像塊(a),在網絡中生成它們的風格化對應塊(b)。
然后,計算這些風格化對應塊(b)相對于從風格化關鍵幀(Sk)中取樣對應圖像塊的損失,并對誤差進行反向傳播。
這樣的訓練方案不限于任何特定的損失函數。本項研究中,采用的是L1損失、對抗性損失和VGG損失的組合。
另一個問題便是超參數的優化。
這是因為不當的超參數可能會導致推理質量低下。
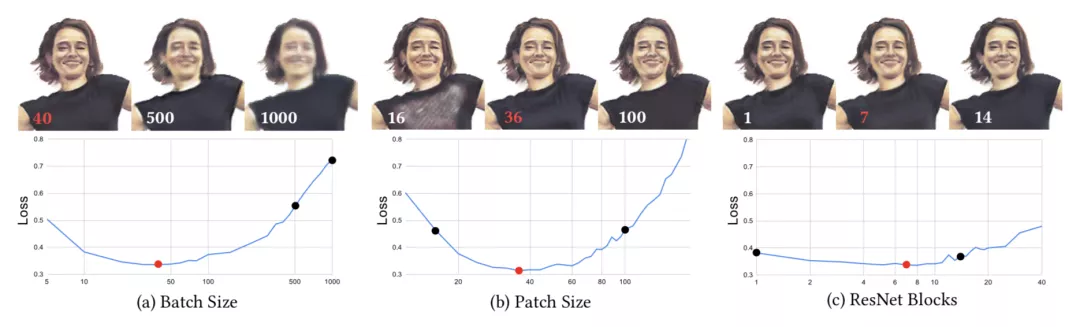
研究人員使用網格搜索法,對超參數的4維空間進行采樣:Wp——訓練圖像塊的大小;Nb——一個batch中塊的數量;α——學習率;Nr——ResNet塊的數量。
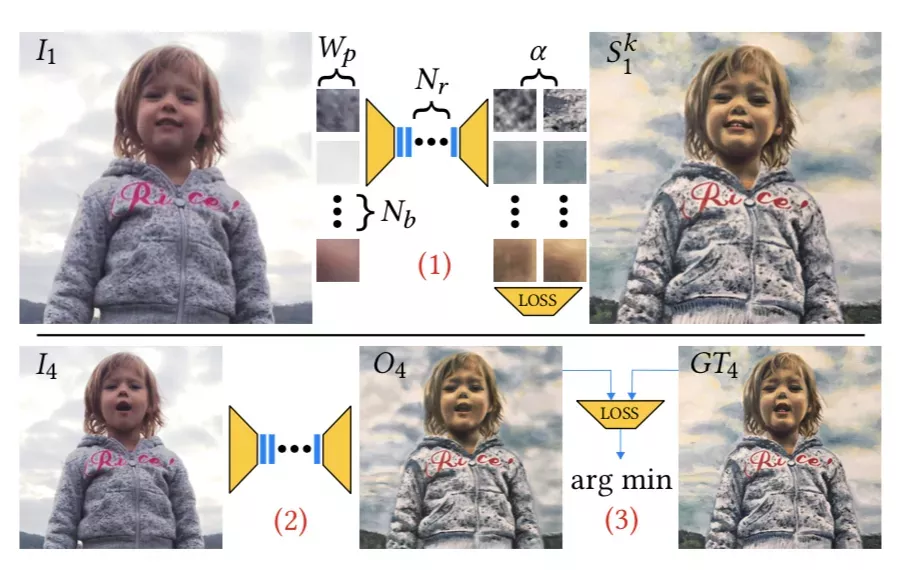
對于每一個超參數設置:
(1)執行給定時間訓練;
(2)對不可見幀進行推理;
(3)計算推理出的幀(O4)和真實值(GT4)之間的損失。
而目標就是將這個損失最小化。
團隊介紹
這項研究一作為Ondřej Texler,布拉格捷克理工大學計算機圖形與交互系的博士生。
而除了此次的工作之外,先前他和團隊也曾做過許多有意思的工作。
例如一邊畫著手繪畫,一邊讓它動起來。
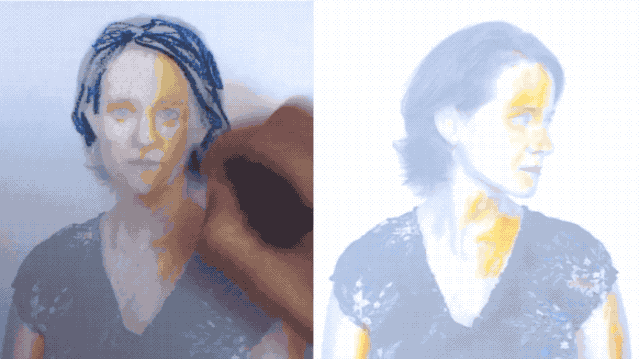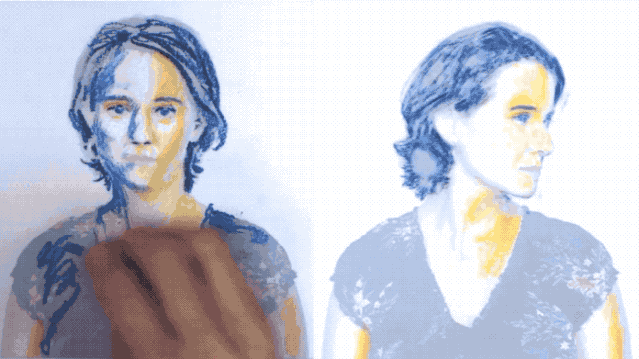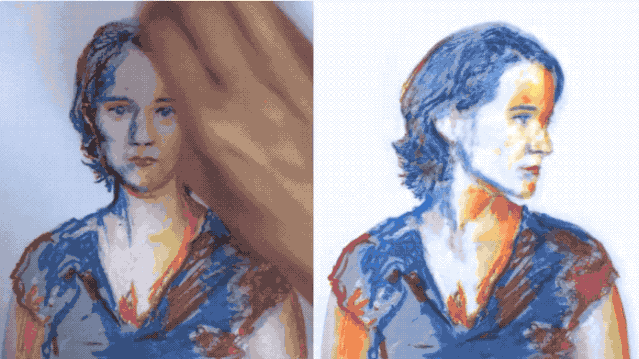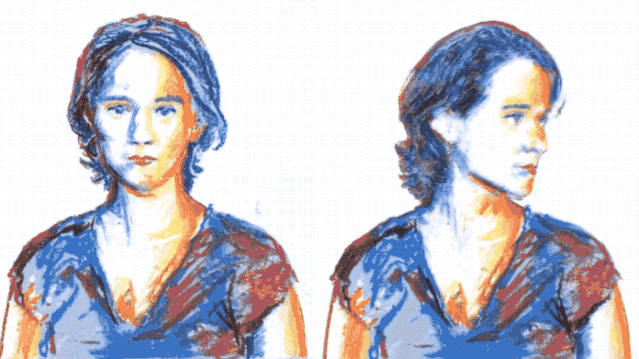
再例如給一張卡通圖片,便可讓視頻中的你頂著這張圖“聲情并茂”。

想了解更多有趣的研究,可戳下方鏈接。
參考鏈接:
[1]https://www.reddit.com/r/MachineLearning/comments/n3b1m6/r_fewshot_patchbased_training_siggraph_2020_dr/
[2]https://ondrejtexler.github.io/patch-based_training/index.html