CSS偏移反爬蟲的原理和破解方法
本文轉載自微信公眾號「志斌的python筆記」,作者志斌。轉載本文請聯系志斌的python筆記公眾號。
大家好,我是志斌~
前幾天在爬取某網站的時候遇到了CSS偏移反爬蟲,它是一種利用CSS樣式將亂序的文字排版成人類正常閱讀順序的反爬蟲。今天志斌就來跟大家分享一下這類反爬蟲應該如何繞過。
01原理
在搭建網頁的時候,我們需要用CSS來控制各類字符的位置,也正是如此,我們可以利用CSS來將瀏覽器中顯示的文字,在HTML中以亂序的方式存儲,從而來限制爬蟲。如下圖,我們發現瀏覽器中實際顯示的是1226,但是HTML中顯示的是1262。
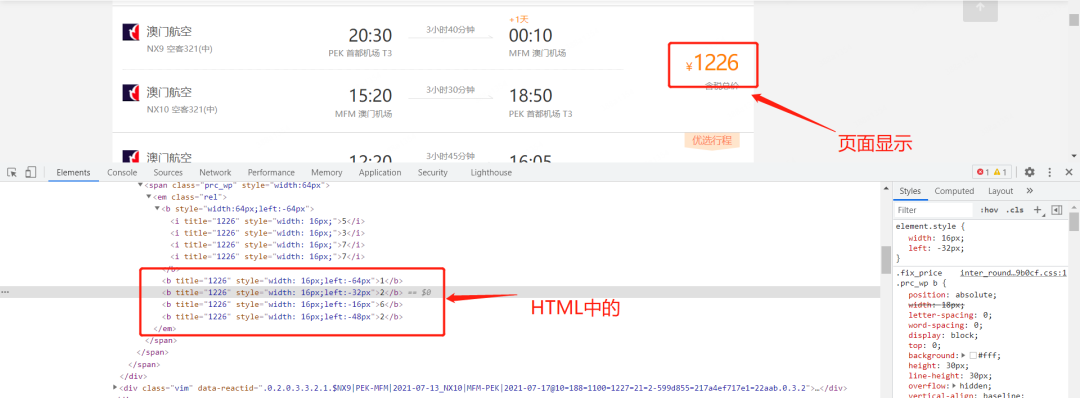
接下來,我們通過一個例子來了解繞過CSS偏移反爬蟲的方法。
02繞過
從下圖中我們看出機票價格的數據被包裹在一個標簽中,標簽大小是64px。如下圖所示:
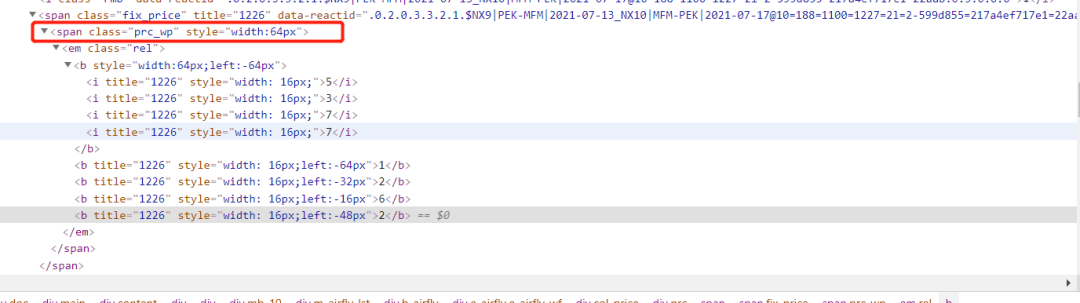
進一步對網頁進行觀察發現,標簽中有五個標簽,它們每一對標簽都有特定的樣式。如下圖所示:
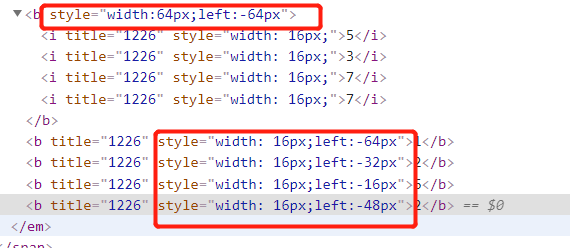
我們用這些CSS樣式來進行分析的話,我們發現,第一對標簽中的四對標簽剛好占滿了標簽的位置。如下圖所示:
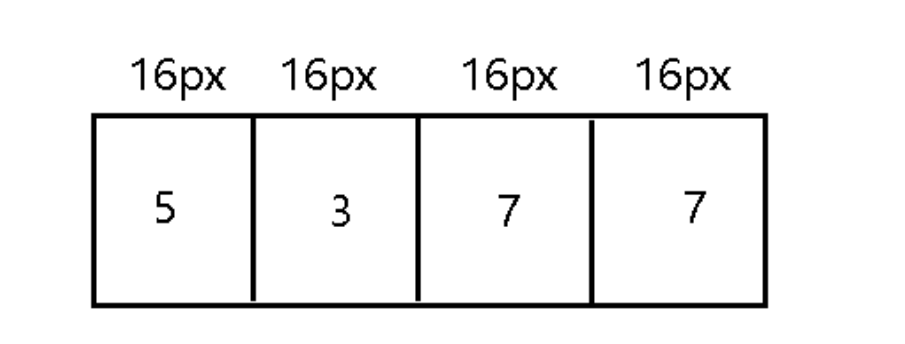
瀏覽器中,本應顯示的是5377,因為第二、三、四、五對標簽中有值,所以我們還需要看一下他們的位置。
第二對的<b>標簽的位置樣式是left:-64px,所以第二對<b>標簽中的1就會覆蓋第一對<b>標簽中第一對<i>標簽中的5;第三對的<b>標簽的位置樣式是left:-32px,第三對<b>標簽中的2會覆蓋第一對<b>標簽中第三對<i>標簽中的7。依次類推,第四對<b>標簽中的6會覆蓋第一對<b>標簽中第四對<i>標簽中的7,第五對<b>標簽中的2會覆蓋第一對<b>標簽中第二對<i>標簽中的3。
通過上面的分析,我們發現,CSS偏移反爬蟲其實就是讓幾個數據由CSS控制位置,來對原數據進行覆蓋,從而實現反爬效果。
那么當我們遇到這類反爬蟲的時候,首先就需要對頁面的CSS進行觀察分析,找到偏移量的計算規律,然后提取出每個標簽中left的值,根據規律來排列出真實的數據。
當然,會有讀者說,我們找到了規律,但是不會提取標簽中的數據怎么辦?不用擔心,在之前的文章中,志斌介紹過如和用BS4提取數據的方式,其中就有提取標簽數據的方法,有不懂的小伙伴,可以看看這篇文章學會BS4,輕松解決數據提取!。
03小結
1. CSS偏移反爬蟲實質上是通過CSS樣式來控制數據在頁面中顯示的位置,從而將亂序的數據以正常的形式展示給用戶。
2. 破解這種反爬蟲的難度并不大,主要是找到位置偏移的計算方法,而且代碼書寫可能較為繁瑣,讀者們可以提前寫好流程圖,然后在進行書寫。
3. 目前這種反爬蟲方法主要是針對于數字數據的反爬。
4. 本文旨在學習與研究CSS偏移反爬蟲,請大家不要用于非法用途。