此Python破解反爬蟲實例,曾幫助過我成長,你也會對它表示感謝!
作者:空手憶歲月
通過用JS在本地生成隨機字符串的反爬蟲機制,在利用Python寫爬蟲的時候經常會遇到的一個問題。希望通過講解,能為大家提供一種思路。以后再碰到這種問題的時候知道該如何解決
通過用JS在本地生成隨機字符串的反爬蟲機制,在利用Python寫爬蟲的時候經常會遇到的一個問題。希望通過講解,能為大家提供一種思路。以后再碰到這種問題的時候知道該如何解決。(如果缺乏學習資料的同學,文末已經給你提供!)
破解有道翻譯反爬蟲機制
web端的有道翻譯,在之前是直接可以爬的。也就是說只要獲取到了他的接口,你就可以肆無忌憚的使用他的接口進行翻譯而不需要支付任何費用。那么自從有道翻譯推出他的API服務的時候,就對這個接口做一個反爬蟲機制。這個反爬蟲機制在爬蟲領域算是一個非常經典的技術手段。那么他的反爬蟲機制原理是什么?如何破解?接下來帶大家一探究竟。
一、正常的爬蟲流程:

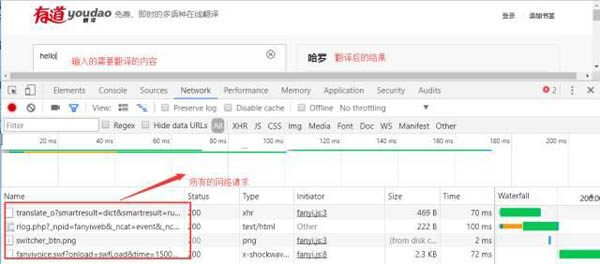
在上圖,我們可以看到發送了很多的網絡請求,這里我們點擊***個網絡請求進行查看:


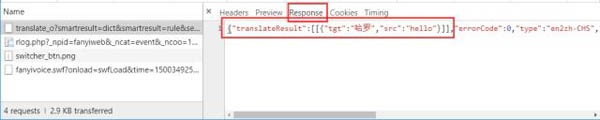

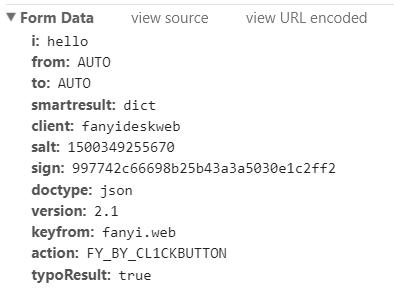
對其中幾個比較重要的數據進行解釋:

其他的數據類型暫時就不怎么重要了,都是固定寫法,我們后面寫代碼的時候直接鞋子就可以了。到現在為止,我們就可以寫一個簡單的爬蟲,去調用有道翻譯的接口了。這里我們使用的網絡請求庫是Python3自帶的urllib,相關代碼如下:


二、破解反爬蟲機制:

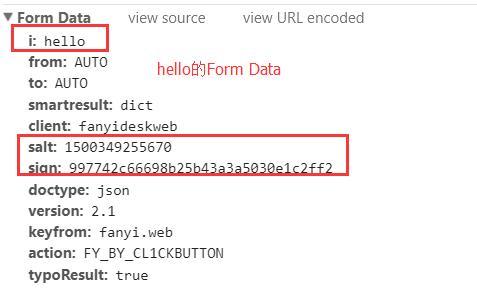



然后把格式化后的代碼,復制下來,用sublime或者pycharm打開都可以,然后搜索salt,可以找到相關的代碼:
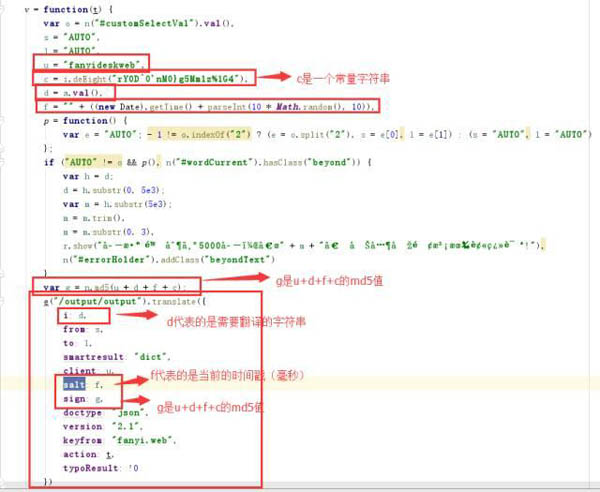

知道salt和sign的生成原理后,我們就可以寫Python代碼,來對接他的接口了,以下是相關代碼:

責任編輯:龐桂玉
來源:
今日頭條