













字體反爬蟲的原理和破解方法
大家好,我是志斌~
之前給大家介紹了一種SVG映射反爬蟲,今天在給大家介紹另外一種通過映射關系來進行反爬蟲的方式。
不知道大家有沒有遇到過這種情況,在寫爬蟲程序之前我們需要對目標數據進行觀察,但是在我們觀察時發現目標數據在網頁中是以這種奇怪的方式出現的。
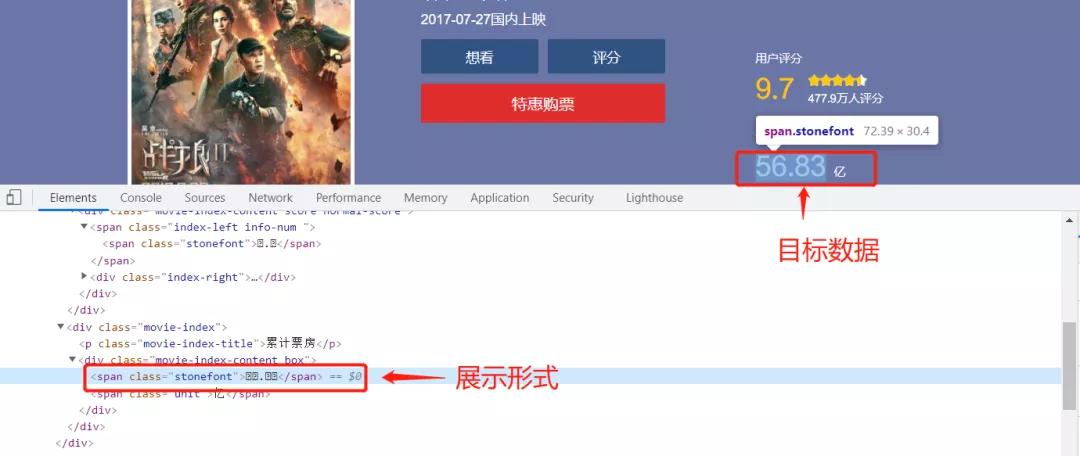
這種反爬蟲就是字體反爬蟲,今天志斌就來跟大家分享一下如何繞過這類反爬蟲。
一、原理
在之前,網站開發者在設計網頁時只能使用公用的字體來展示網頁中的數據。
但是,隨著CSS樣式的深入開發,網站開發者可以將自己的字體放到服務器中。當用戶在訪問Web界面時,對應的字體就會被瀏覽器自動下載到用戶的計算機中,然后通過CSS樣式進行調用。
之后,通過一種映射關系,使得網頁中的源數據變為真正的數據進行展示。
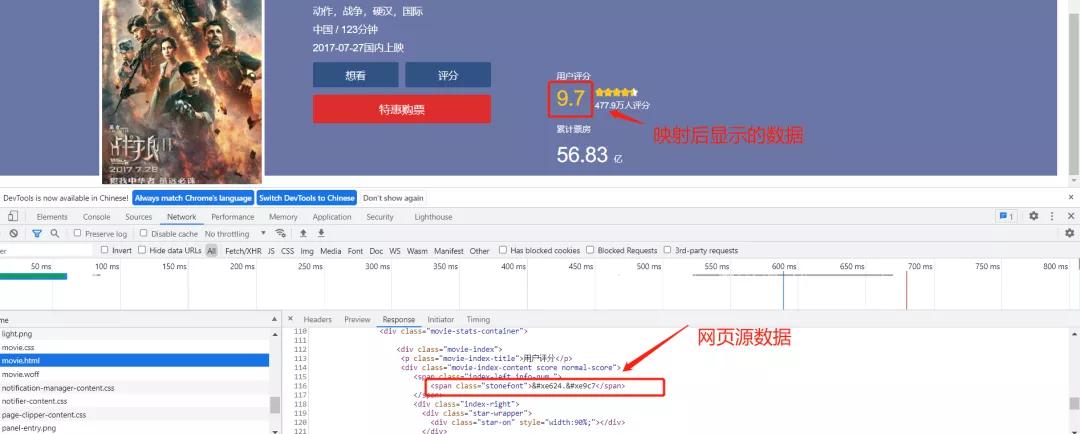
通過這種方式,使得這樣就使得網站開發者進行網頁設計時,只需要使用特殊字符進行占位即可,不需要將真正的數據放到頁面中去。這樣,爬蟲程序如果不知道這種映射關系的話,就無法從字體中獲取正確的數據,從而實現反爬蟲。
二、破解
破解這類字體反爬蟲有以下幾步。
1.下載字體woff文件
從上面我們知道,字體是在服務器上進行存儲,并通過瀏覽器下載到我們的電腦上的,那么我們就可以在網站上找到加載的字體文件,下載下來。

下載下來之后,打開它進行觀察,這里給大家分享一個再點字體編譯器網站,使用它可以很方便打開woff文件。網址:http://font.qqe2.com/index-en.html。
打開字體文件之后,我們發現,每個數字都對應一個字符串,如7對應的是$E9C7。

2.尋找映射關系
通過對源網頁中的占位數據和字體進行比對,我們發現將源數據中的&#x替換成$,然后將字符串首字母大寫,就變成了字體對應的字符串了。

3.構建映射算法
在上面我們已經找到了字體之間映射關系,那么我們現在就可以開始用Python來構建映射算法,從而使得爬蟲可以獲取一個正確的數據。
構建代碼如下:
- data = {
- '' : 7,
- '' : 1,
- '' : 2,
- '' : 6,
- '' : 9,
- '' : 5,
- '' : 3,
- '' : 0,
- '' : 4,
- '' : 8,
- }
之后,我們即可對網頁進行爬取,然后將對應的源數據與data進行比如,從而獲得正確數據。
三、小結
1. 本文詳細介紹了如何破解字體反爬蟲,由于這種反爬蟲是使用CSS進行加載和映射的,所以即使使用一些自動化軟件或者渲染工具也無法獲得真正的數據。
2. 這類反爬蟲的破解只需要將woff文件中的字體與頁面數據之間的對應關系找到,構建好即可。
3. 找到woff文件進行下載是關鍵。
4. 有興趣的讀者可以找志斌要一下網站自己嘗試一下。
5. 本文僅供學習參考,不做它用。

















