













圖片偽裝反爬蟲的原理和破解方法
作者: 志斌
圖片偽裝反爬蟲的本質(zhì)就是用圖片替換了原來的內(nèi)容,從而讓爬蟲程序無法正常獲取,我們只要將里面的內(nèi)容識別、提取出來就可以破解這種反爬蟲。

本文轉(zhuǎn)載自微信公眾號「志斌的python筆記」,作者志斌 。轉(zhuǎn)載本文請聯(lián)系志斌的python筆記公眾號。
大家好,我是志斌~
今天志斌來給大家分享一下如何破解文本混淆反爬蟲中的圖片偽裝反爬蟲~
01定義
現(xiàn)在許多大型網(wǎng)站的反爬蟲方式是將圖片與文字混合在一起,放到頁面上進行展示。這種混合展示的方式并不會影響用戶的正常閱讀,但是卻可以限制爬蟲程序獲取這些內(nèi)容。如下圖:
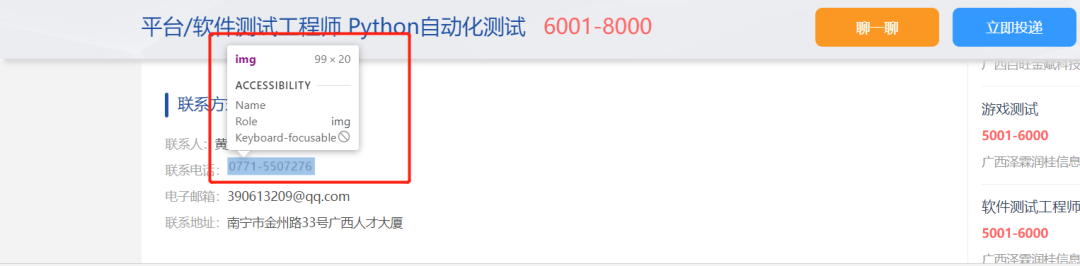
02原理
這種反爬蟲的原理十分簡單,就是將本應(yīng)是普通文本內(nèi)容的部分在前端頁面中用圖片來進行替換,從而達到“魚目混珠“的效果。
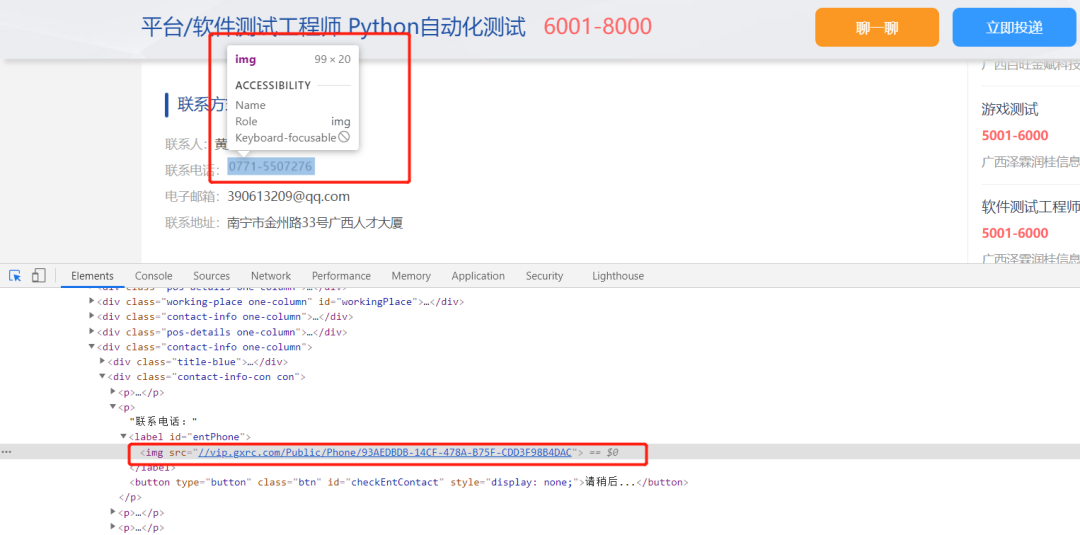
03破解
因為這種反爬蟲方式是將內(nèi)容進行替換,所以我們無法進行繞過,只能破解它來獲取我們想要的內(nèi)容。
破解的方法也比較簡單,我們只需要將圖片下載下來然后對里面的內(nèi)容進行提取即可。提取圖片中的文字有很多方式,我用的是百度AI來進行提取。代碼如下:
- from aip import AipOcr
- APP_ID = '你的APPID'
- API_KEY = 'API Key'
- SECRET_KEY = '你的Secret Key'
- client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
- with open(img,'rb') as f:
- image = f.read()
- word = client.basicGeneral(image)
在之前的文章中我分享過一個用百度api進行提取圖片中內(nèi)容的方式,有興趣的讀者可以看看這篇文章20行代碼教你如何批量提取圖片中文字。
04小結(jié)
1. 圖片偽裝反爬蟲的本質(zhì)就是用圖片替換了原來的內(nèi)容,從而讓爬蟲程序無法正常獲取,我們只要將里面的內(nèi)容識別、提取出來就可以破解這種反爬蟲。
2. 破解這種反爬蟲的難度并不大,但是代碼書寫可能較為繁瑣,讀者們可以提前寫好流程圖,然后在進行書寫。
3. 目前這種反爬蟲方法已經(jīng)被各類大型網(wǎng)站所應(yīng)用,所以大家要掌握這種反爬蟲的繞過方法。
4. 本文旨在學(xué)習(xí)與研究圖片偽裝反爬蟲,請大家不要用于非法用途。
責(zé)任編輯:武曉燕
來源:
志斌的python筆記

















