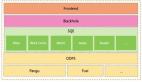
Hologres 揭秘:如何支持超高 QPS 在線服務(點查)場景
傳統的 OLAP 系統在業務中往往扮演著比較靜態的角色,以通過分析海量的數據得到業務的洞察(比如說預計算好的視圖、模型等),從這些海量數據分析到的結果再通過另外一個系統提供在線數據服務(比如HBase、Redis、MySQL等)。這里的服務(Serving)和分析(Analytical)是個割裂的過程。與此不同的是,實際的業務決策過程往往是一個持續優化的在線過程。服務的過程會產生大量的新數據,我們需要對這些新數據進行復雜的分析。分析產生的洞察實時反饋到服務,讓業務的決策更實時,從而創造更大的商業價值。
Hologres定位是一站式實時數倉,融合分析能力(Analytical)與在線服務(Serving)為一體,減少數據的割裂和移動。本文的內容將會針對Hologres的服務能力(核心為點查能力),介紹Hologres到底具備哪些服務能力,以及背后的實現原理。
通常我們所說的點查場景是指Key/Value查詢的場景,廣泛用于在線服務。由于點查場景的廣泛需求,市場上存在多種KV數據庫定位于支持高吞吐、低延時的點查場景,例如被大家廣而熟知的HBase,它通過自定義的一套API來提供點查的能力,在許多業務場景都能夠獲得較好的效果。但是HBase在實際使用中也會存在一定的缺點,這也使得很多業務從HBase遷移至Hologres,主要有以下幾點:
當數據規模大到一定程度的時候,HBase在性能方面將會有所下降,無法滿足大規模的點查計算,同時在穩定性上也變得不如人意,需要有經驗的運維支持
HBase提供的是自定義API,上手有一定的成本。Hologres直接通過SQL提供高吞吐、低延時的點查服務。相比于其它KV系統提供自定義API,SQL接口無疑更加的簡單易用。
HBase采用Schema Free設計,沒有數據類型,對于檢查數據質量,修正數據質量也帶來了復雜度,查錯難,修正難。Hologres具備與Postgres兼容的幾乎所有主流數據類型,可以通過Insert/Select/Update/Delete標準SQL語句對數據進行查看、更新。
在Hologres中的點查場景是指行存表基于主鍵(PK)的查詢。
- --建行存表BEGIN;CREATE TABLE public.holotest ( "a" text NOT NULL, "b" text NOT NULL, "c" text NOT NULL, "d" text NOT NULL, "e" text NOT NULL,PRIMARY KEY (a,b));CALL SET_TABLE_PROPERTY('public.holotest', 'orientation', 'row');CALL SET_TABLE_PROPERTY('public.holotest', 'time_to_live_in_seconds', '3153600000');COMMIT;-- Hologres通過SQL進行點查select * from table where pk = ?; -- 一次查詢單個點select * from table where pk in (?, ?, ?, ?, ?); -- 一次查詢多個點
點查場景技術實現難點
正常情況下,一條SQL語句的執行,需要經過SQL Parser進行解析成AST(抽象語法樹),再由Query Optimizer處理生成Plan(可執行計劃),最終通過執行Plan拿到計算結果。而要想通過SQL做到高吞吐、低延時、穩定的點查服務,則必須要克服如下困難:
在不破壞PostgreSQL生態的情況下,SQL接口如何做到高QPS?
如何做低甚至避免SQL解析與優化器的開銷
一套高效的Client SDK如何與后端存儲進行交互?
如何在低消耗的情況下,做到高并發的交互
如何減少消息傳遞過程中的開銷
如何感知后端的壓力、配合做到最好的吞吐與延遲
后端存儲如何在高性能的情況下更加穩定?
如何最大化利用cpu資源
如何減少各種內存的分配與拷貝、避免熱點key等問題對系統帶來的不穩定性
如何減少冷數據IO的影響
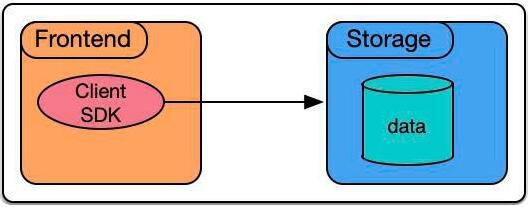
在克服上述3大類困難后,整體的工作方式就可以非常的簡潔:在接入層(FrontEnd)上直接通過Client SDK與后端存儲通信。
下面將會介紹Hologres是如何克服以上3大困難,從而實現高吞吐低延時的點查。
降低、避免SQL解析與優化器的開銷
Query Optimizer進行Short Cut
由于點查的Query足夠簡單,Hologres的Query Optimizer進行了相應的short cut,點查Query并不會進入Opimizer的完整流程。Query進入FrontEnd后它會交由Fixed Planner進行處理,并由其生成對于的Fixed Plan(點查的物理Plan),Fixed Planner非常輕,無需經過任何的等價變換、邏輯優化、物理優化等步驟,僅僅是基于AST樹進行了一些簡單的分析并構建出對應的Fixed Plan,從而盡量規避掉優化器的開銷。
Prepared Statement
盡管Query Optimizer對點查Query進行了short cut,但是Query進入到FrontEnd后的解析開銷依然存在、Query Optimizer的開銷也沒有完全避免。
Hologres兼容Postgres,Postgres的前、后端通信協議有extended協議與simple協議兩種:
simple協議:是一次性交互的協議,Client每次會直接發送待執行的SQL給Server,Server收到SQL后直接進行解析、執行,并將結果返回給Client。simple協議里Server無可避免的至少需要對收到的SQL進行解析才能理解其語義。
extended協議:Client與Server的交互分多階段完成,整體大致可以分成兩大階段。
第一階段:Client在Server端定義了一個帶名字的Statement,并且生成了該Statement所對應的generic plan(不與特定的參數綁定的通用plan)。
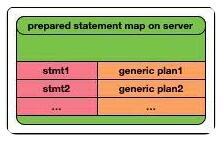
第二階段:用戶通過發送具體的參數來執行第一階段中定義的Statement。第二階段可以重復執行多次,每次通過帶上第一階段中所定義的Statement名字,以及執行所需要的參數,使用第一階段生成的generic plan進行執行。由于第二階段可以通過Statement名字和附帶的參數來反復執行第一個階段所準備好的generic plan,因此第二個段在Frontend的開銷幾乎等同于0。
為此Hologres基于Postgres的extended協議,支持了Prepared Statement,做到了點查Query在Frontend上的開銷接近于0。
高性能的內部通信
BHClient是Hologres實現的一套用于與后端存儲直接通信的高效Private Client SDK,主要有以下幾個優勢:
1)Reactor模型、全程無鎖的異步操作
BHClient工作方式類似reactor模型,每個目標shard對應一個eventloop,以“死循環”的方式處理該shard上的請求。由于HOS對調度執行單元的抽象,即使是shard很多的情況下,這種工作方式的基礎消耗也足夠低。
2)高效的數據交換協議binary row
通過自定義一套內部的數據通信協議binary row來減少整個交互鏈路上的內存的分配與拷貝。
3)反壓與湊批
BHClient可以感知后端的壓力,進行自適應的反壓與湊批,在不影響原有Latency的情況下提升系統吞吐。
穩定可靠的后端存儲
1)LSM(Log Structured Merge Tree)
Hologres的行存表采取LSM進行存儲,相比于傳統的B+樹,LSM能夠提供更高的寫吞吐,因為它不會出現任何的隨機寫,Append Only的操作保證了其只會順序的寫盤。
一個行存tablet上會存在一個memtable,和多個immutable memtable。
數據更新都會寫入到memtable中,當memtable寫滿后會轉變為immtable memtable,immutable memtable會Flush成Key有序的SST(Sorted String Table)文件,SST文件一旦生成則不能修改,因此不會發生隨機寫的操作。
SST文件在文件系統里面按層組織,除了level 0上的SST文件間無序,且存在overlap外,其它level上的SST文件間有序,且無overlap。因此查詢的時候,對于level 0上的文件需要逐個遍歷,而其它level的文件可以二分查找。底層的SST文件通過Compaction成新的SST文件去到更高層,因此低層的數據要比高層的新,所以一旦在某層上找到了滿足條件的key則無需往更高層去查詢。
2)基于C++純異步的開發
采用LSM對數據進行組織存儲的系統并不僅僅只有Hologres,LSM在谷歌的"BigTable"論文中被提出后,很多的系統都對其進行了借鑒采用,例如HBase。Hologres采用C++進行開發,相較于Java,native語言使得我們能夠追求到更極致的性能。同時基于HOS(Hologres Operation System)提供的異步接口進行純異步開發,HOS通過抽象ExecutionContext來自我管理CPU的調度執行,能夠最大化的利用硬件資源、達到吞吐最大化。
3)IO優化與豐富的Cache機制
Hologres實現了非常豐富的Cache機制row cache、block cache、iterator cache、meta cache等,來加速熱數據的查找、減少IO訪問、避免新內存分配。當無可避免的需要發生IO時,Hologres會對并發IO進行合并、通過wait/notice機制確保只訪問一次IO,減少IO處理量。通過生成文件級別的詞典及壓縮,減少文件物理存儲成本及IO訪問。
總結
Hologres致力于一站式實時數倉,除了具備處理復雜OLAP分析場景的能力之外,還支持超高QPS在線點查服務,通過使用標準的Postgres SDK接口,就能通過SQL獲得低延時、高吞吐的在線服務能力,簡化學習成本,提升開發效率。