













微軟、浙大研究者提出剪枝框架OTO,無需微調即可獲得輕量級架構
來自微軟、浙江大學等機構的研究者提出了一種 one-shot DNN 剪枝框架,無需微調即可從大型神經網絡中得到輕量級架構,在保持模型高性能的同時還能顯著降低所需算力。
大型神經網絡學習速度很快,性能也往往優于其他較小的模型,但它們對資源的巨大需求限制了其在現實世界的部署。
剪枝是最常見的 DNN 壓縮方法之一,旨在減少冗余結構,給 DNN 模型瘦身的同時提高其可解釋性。然而,現有的剪枝方法通常是啟發式的,而且只針對特定任務,還非常耗時,泛化能力也很差。
在一篇標題為《 Only Train Once: A One-Shot Neural Network Training And Pruning Framework》的論文中,來自微軟、浙江大學等機構的研究者給出了針對上述問題的解決方案,提出了一種 one-shot DNN 剪枝框架。它可以讓開發者無需微調就能從大型神經網絡中得到輕量級架構。這種方法在保持模型高性能的同時顯著降低了其所需的算力。

論文鏈接:https://arxiv.org/pdf/2107.07467.pdf
該研究的主要貢獻概括如下:
- One-Shot 訓練和剪枝。研究者提出了一個名為 OTO(Only-Train-Once)的 one-shot 訓練和剪枝框架。它可以將一個完整的神經網絡壓縮為輕量級網絡,同時保持較高的性能。OTO 大大簡化了現有剪枝方法復雜的多階段訓練 pipeline,適合各種架構和應用,因此具有通用性和有效性。
- Zero-Invariant Group(ZIG)。研究者定義了神經網絡的 zero-invariant group。如果一個框架被劃分為 ZIG,它就允許我們修剪 zero group,同時不影響輸出,這么做的結果是 one-shot 剪枝。這種特性適用于全連接層、殘差塊、多頭注意力等多種流行結構。
- 新的結構化稀疏優化算法。研究者提出了 Half-Space Stochastic Projected Gradient(HSPG),這是一種解決引起正則化問題的結構化稀疏的方法。研究團隊在實踐中展示并分析了 HSPG 在促進 zero group 方面表現出的優勢(相對于標準近端方法)。ZIG 和 HSPG 的設計是網絡無關的,因此 OTO 對于很多應用來說都是通用的。
- 實驗結果。利用本文中提出的方法,研究者可以從頭、同時訓練和壓縮完整模型,無需為了提高推理速度和減少參數而進行微調。在 VGG for CIFAR10、ResNet50 for CIFAR10/ImageNet 和 Bert for SQuAD 等基準上,該方法都實現了 SOTA 結果。
方法及實驗介紹

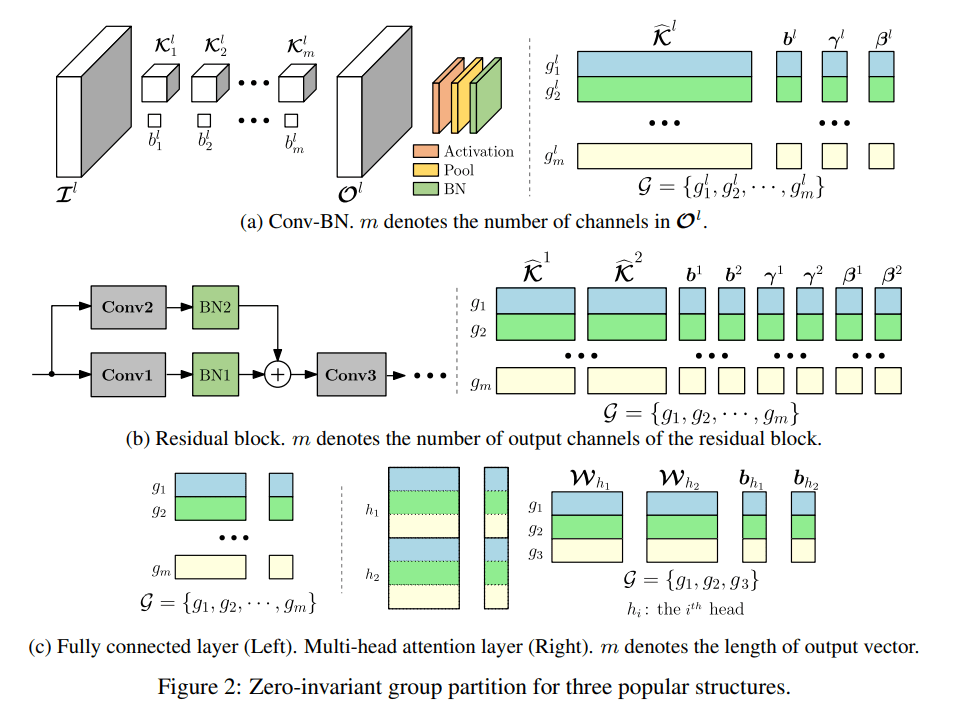
OTO 的結構非常簡單。給定一個完整的模型,首先將可訓練的參數劃分為 ZIG 集,產生了一個結構化稀疏優化問題,通過一個新的隨機優化器 (HSPG) 得出高度組稀疏的解。最后通過剪枝這些 zero group 得到一個壓縮模型。
團隊提出的 HSPG 隨機優化算法是針對非光滑正則化問題而設計的,與經典算法相比,該算法在保持相似收斂性的同時,能夠更有效地增強群體稀疏性搜索。
為了評估 OTO 在未經微調的 one-shot 訓練和剪枝中的性能,研究者在 CNN 的基準壓縮任務進行了實驗,包括 CIFAR10 的 VGG16,CIFAR10 的 ResNet50 和 ImagetNet (ILSVRC2012),研究者比較了 OTO 與其當前各個 SOTA 算法在 Top-1 精度和 Top-5 精度、剩余的 FLOPs 和相應的 baseline 參數。

表 1:CIFAR10 中的 VGG16 及 VGG16-BN 模型表現。
在 CIFAR10 的 VGG16 實驗中,OTO 將浮點數減少了 83.7%,將參數量減少了 97.5%,性能表現令人印象深刻。
在 CIFAR10 的 ResNet50 實驗中,OTO 在沒有量化的情況下優于 SOTA 神經網絡壓縮框架 AMC 和 ANNC,僅使用了 12.8% 的 FLOPs 和 8.8% 的參數。

表 2:CIFAR10 的 ResNet50 實驗。
在 ResNet50 的 ImageNet 實驗中,OTO 減少了 64.5% 的參數,實現了 65.5% 的浮點數減少,與 baseline 的 Top-1/5 精度相比只有 1.4%/0.8% 的差距 。
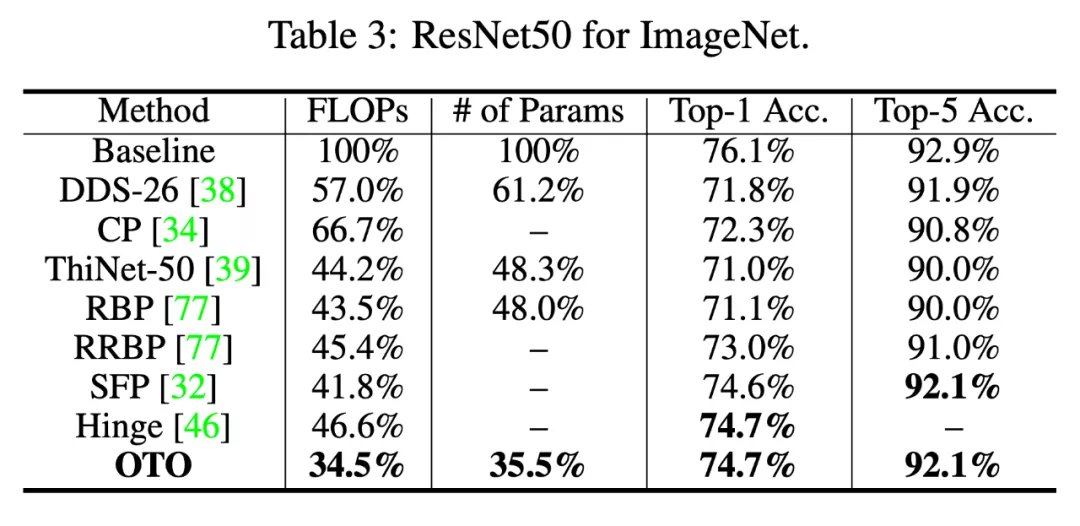
表 3:ResNet50 的 ImageNet。
總體而言,OTO 在所有的壓縮基準實驗中獲得了 SOTA 結果,展現了模型的巨大潛力。研究者表示,未來的研究將關注合并量化和各種任務的應用上。

















