GPT-3解數學題準確率升至92.5%!微軟提出MathPrompter,無需微調即可打造「理科」語言模型
大型語言模型最為人詬病的缺點,除了一本正經地胡言亂語以外,估計就是「不會算數」了。

比如一個需要多步推理的復雜數學問題,語言模型通常都無法給出正確答案,即便有「思維鏈」技術的加持,往往中間步驟也會出錯。
與文科類的自然語言理解任務不同,數學問題通常只有一個正確答案,在不那么開放的答案范圍下,使得生成準確解的任務對大型語言模型來說更具挑戰性。
并且,在數學問題上,現有的語言模型通常不會對自己的答案提供置信度(confidence),讓用戶無從判斷生成答案的可信度。
為了解決這個問題,微軟研究院提出了MathPrompter技術,可以提高 LLM 在算術問題上的性能,同時增加對預測的依賴。
論文鏈接:https://arxiv.org/abs/2303.05398
MathPrompter 使用 Zero-shot 思維鏈提示技術生成多個代數表達式或 Python 函數,以不同方式解決同一個數學問題,從而提高輸出結果的可信度。
相比其他基于提示的 CoT 方法,MathPrompter還會檢查中間步驟的有效性。
基于175B 參數 GPT,使用MathPrompter方法將MultiArith 數據集的準確率從78.7%提升到了92.5%!
專攻數學的Prompt
近幾年,自然語言處理的發展很大程度上要歸功于大型語言模型(LLMs)在規模上的不斷擴展,其展現出了驚人的zero-shot和few-shot能力,也促成了prompting技術的發展,用戶只需要在prompt中給LLM輸入幾個簡單的樣例即可對新任務進行預測。
prompt對于單步的任務來說可以說相當成功,但在需要多步驟推理的任務中,提示技術的性能仍然不夠。
人類在解決一個復雜問題時,會將其進行分解,并嘗試一步步地解決,「思維鏈」(CoT)提示技術就是將這種直覺擴展到LLMs中,在一系列需要推理的NLP任務中都得到了性能改進。
這篇論文主要研究「用于解決數學推理任務」的Zero-shot-CoT方法,之前的工作已經在MultiArith數據集上得到了顯著的準確率改進,從17.7% 提升到了 78.7%,但仍然存在兩個關鍵的不足之處:
1、雖然模型所遵循的思維鏈改進了結果,但卻沒有檢查思維鏈提示所遵循的每個步驟的有效性;
2、沒有對LLM預測結果提供置信度(confidence)。
MathPrompter
為了在一定程度上解決這些差距,研究人員從「人類解決數學題的方式」中得到啟發,將復雜問題分解為更簡單的多步驟程序,并利用多種方式在每一個步驟中對方法進行驗證。

由于LLM是生成式模型,要確保生成的答案是準確的,特別是對于數學推理任務,就變得非常棘手。
研究人員觀察學生解決算術問題的過程,總結出了學生為驗證其解決方案而采取的幾個步驟:
遵循已知結果(Compliance with known results),通過將解決方案與已知結果進行比較,可以評估其準確性并進行必要的調整;當問題是一個具有成熟解決方案的標準問題時,這一點尤其有用。
多重驗證 Multi-verification,通過從多個角度切入問題并比較結果,有助于確認解決方案的有效性,確保其既合理又準確。
交叉檢查 Cross-checking,解決問題的過程與最終的答案同樣必要;驗證過程中的中間步驟的正確性可以清楚地了解解決方案背后的思維過程。
計算驗證 Compute verification,利用計算器或電腦進行算術計算可以幫助驗證最終答案的準確性
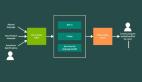
具體來說,給定一個問題Q,

在一家餐廳,每份成人餐的價格是5美元,兒童免費用餐。如果有15個人進來,其中8個是孩子,那么這群人要花多少錢吃飯?
1. 生成代數模板 Generating Algebraic template
首先將問題轉化為代數形式,通過使用鍵值映射將數字項替換為變量,然后得到修改后的問題Qt

2. 數學提示 Math-prompts
基于上述多重驗證和交叉檢查的思維過程所提供的直覺上,使用兩種不同的方法生成Qt的分析解決方案,即代數方式和Pythonic方式,給LLM提供以下提示,為Qt生成額外的上下文。

提示可以是「推導出一個代數表達式」或「編寫一個Python函數」
LLM模型在響應提示后可以輸出如下表達式。

上述生成的分析方案為用戶提供了關于LLM的「中間思維過程」的提示,加入額外的提示可以提高結果的準確性和一致性,反過來會提高MathPrompter生成更精確和有效的解決方案的能力。
3. 計算驗證 Compute verification
使用Qt中輸入變量的多個隨機鍵值映射來評估上一步生成的表達式,使用Python的eval()方法對這些表達式進行評估。
然后比較輸出結果,看是否能在答案中找到一個共識(consensus),也可以提供更高的置信度,即答案是正確且可靠的。

一旦表達式在輸出上達成一致,就使用輸入Q中的變量值來計算最終的答案。
4. 統計學意義 Statistical significance
為了確保在各種表達式的輸出中達成共識,在實驗中將步驟2和3重復大約5次,并報告觀察到的出現最頻繁的答案值。
在沒有明確共識的情況下,重復步驟2、3、4。
實驗結果
在MultiArith數據集上對MathPrompter進行評估,其中的數學問題專門用來測試機器學習模型進行復雜算術運算和推理的能力,要求應用多種算術運算和邏輯推理才能成功地解決。

在MultiArith數據集上的準確率結果顯示,MathPrompter的表現優于所有的Zero-shot和Zero-shot-CoT基線,將準確率從78.7% 提升到 92.5%
可以看到,基于175B參數GPT3 DaVinci的MathPrompter模型的性能與540B參數模型以及SOTA的Few-shot-CoT方法相當。

從上表可以看到,MathPrompter的設計可以彌補諸如「生成的答案有時會有一步之差」的問題,可以通過多次運行模型并報告共識結果來避免。
此外,推理步驟可能過于冗長的問題,可以由Pythonic或Algebraic方法可以解決這個問題,通常需要較少的token
此外,推理步驟可能是正確的,但最終的計算結果卻不正確,MathPrompter通過使用Python的eval()方法函數來解決這個問題。
在大部分情況下,MathPrompter都能生成正確的中間和最終答案,不過也有少數情況,如表中的最后一個問題,代數和Pythonic的輸出都是一致的,但卻有錯誤。