中國郵政郵科院 X DorisDB:統一OLAP平臺,大幅降低運維成本
郵政科學研究規劃院有限公司(以下簡稱“郵科院”),作為中國郵政集團有限公司的科研智庫單位,專注于戰略規劃、企業管理、工程設計、物流裝備、智能終端、質量檢測、標準化研究等領域,在助力中國郵政戰略轉型和經營發展中發揮著重要支撐作用。
郵科院數據組負責全院大數據體系架構的建設,支撐日常BI運營分析、科研數據產品、物流數據、網點畫像等業務場景。郵科院數據組通過使用DorisDB,統一了實時和離線的分析場景,替換了ClickHouse、Presto、MySQL等系統,解決了原有多套系統帶來的運維和使用復雜性,簡化了數據ETL流程,同時大幅提升OLAP、Adhoc等場景的查詢效率。本文主要介紹郵科院數據組基于新一代極速全場景MPP數據庫DorisDB,在數據服務體系和數據應用場景中的實踐和探索。
“作者:謝翔 郵政科學研究規劃院有限公司寄遞研究所數據組負責人,專注于數倉建設、數據分析等領域研究。”
一、業務背景
隨著科研數據積累越來越大,數據規模和體量也急劇膨脹。科研的原始數據通常來源于研報抽取、日志埋點文件、業務數據庫、三方接口等。過去通常基于CDH/Hadoop等大數據分布式計算框架和數據集成工具,構建離線的數據倉庫,并對數據進行適當的分層、建模、加工和管理,構建各類分析主題。郵科院數據體系中沉淀了諸多研報主題數據,例如:電商流量數據,物流企業財務數據,行業報告相關的數據等。
上層數據應用對查詢的響應延遲和時效性要求高,會將數據通過數據同步工具同步到MySQL、ElasticSearch、Presto、HBase、ClickHouse等數據庫系統中,來支撐上層數據應用的查詢要求。
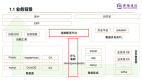
郵科院的大數據總體架構如下圖所示,從下到上可以分為數據接入層、數據計算層、數據服務層和數據應用層。

數據計算層使用科研工作各分析場景下產生的模型/方案/業務的明細數據,進行離線數據計算,對TB級別的明細數據進行調度、聚合、計算,在數倉里沉淀出大量明細表、聚合表和最終的數據報表。
數據計算層生成的各類數據表,會同步到數據服務層,由數據服務層提供接口給數據應用層使用,滿足不同的數據業務需求。
二、業務痛點
數據服務層的愿景是開放數倉能力,建立統一的數據服務出口,針對不同的數據業務分析場景(數據規模、QPS、UDF支持、運維成本等),原有架構在底層使用了不同的查詢引擎:
·大數據量、低QPS:使用Hive、Presto、ClickHouse等基于Hadoop生態的離線批任務計算框架和MPP數據庫來解決。
·小數據量、高QPS:使用MySQL、ElasticSearch、HBase、MongoDB等關系型/非關系型數據庫來解決。
使用多套查詢引擎,我們遇到如下問題和挑戰:
·離線/實時ETL任務過多,處理邏輯大部分為簡單聚合/去重,聚合表數量龐大,導致運營和運維上的成本增加;
·針對中等數據量、中等QPS的查詢場景,如何能兼顧數據規模的同時,有較友好的查詢響應延遲;
·大數據量下插入、更新的實時數據場景無法得到支持,例如:網點畫像、實時數據導入、郵路路徑、研報數據匯總等。
三、OLAP引擎選型
針對如上的問題和挑戰,我們的目標是尋求盡可能少的OLAP引擎,利用在明細表上現場計算來解決ETL任務、數倉表過多問題,同時需要兼顧在數據規模、查詢QPS、響應耗時、查詢場景方面的權衡。
目前市面上OLAP引擎百花齊放,諸如Impala、Druid、ClickHouse、DorisDB。經過一番調研,我們最終選擇了DorisDB。DorisDB是基于MPP架構的分析型數據庫,自帶數據存儲,整合了大數據框架的優勢,支持主鍵更新、支持現代化物化視圖、支持高并發和高吞吐的即席查詢等諸多優點,天然能解決我們上述的問題。

四、DorisDB應用實踐
DorisDB已經投入生產環境,主要作為離線/實時數據的OLAP數據庫使用。離線數據主要存儲于HDFS中,通過DataX任務批量同步數據到DorisDB;另一部分實時數據主要存儲于Kafka中,使用DorisDB的routine load功能實時將數據從kafka寫入到DorisDB。
在沒有引入DorisDB之前,我們使用的底層引擎是MySQL、Presto on HDFS和ClickHouse等系統,對明細表/聚合表進行查詢。這幾種方式都存在著不少問題:
·MySQL處理上億規模的數據,無論使用分庫分表、分區表、集群化部署的PolarDB方案,都會存在慢查詢、數據庫扛不住、運維困難的窘境;
·Presto on HDFS的方案更偏向于分析型數據業務,雖然能存儲海量的數據,計算能力不錯,唯一致命的在于無法滿足在線業務的高吞吐QPS,查詢比較難做到毫秒級。
·ClickHouse對Join支持較弱,通常使用大寬表建模,不夠靈活,另外運維也比較復雜。
·在引入DorisDB替換MySQL、Presto和ClickHouse后,DorisDB帶來的業務效果如下:
·支撐了在線報表查詢+數據分析業務,服務于對內運營+對外行業分析的數據產品,報表業務查詢大部分耗時在毫秒級別,分析型業務查詢大部分耗時在秒級別;
·支持10億規模的明細表查詢,月、季、年等維度統計數據現場算聚合統計、精準去重等,查詢耗時都能控制在500ms以內;
·千萬級別的多表的Join和union查詢,經過Colocate Join特性優化,查詢響應在秒級。
另外,我們還將DorisDB應用到實時數據分析場景,DorisDB在實時數據分析主要有如下優勢:
·實時寫入性能:目前DorisDB支持HTTP方式的Stream Load,可以自定義的分鐘級別微批寫入,以及Routine Load功能,可以將Kafka的數據實時同步到DorisDB中,滿足當前實時數據分析業務;
·統一離線和實時分析:實時數據和離線數據更好的在DorisDB中進行融合,靈活支撐應用,數據存儲策略通過DorisDB動態分區的功能進行自動管理;
·SQL Online Serving:高效的SQL即席查詢能力,能夠兼容業界標準的SQL規范,支撐業務靈活復雜的訪問,提高取數開發的效率。
五、總結和規劃
郵科院數據組引入DorisDB生產集群,解決了數據服務層單表億級別規模、高QPS數據場景下引擎的空白,直接開放明細表準實時查詢的能力,給各項目組上層數據業務和BI系統提供了更多的選擇和自由度,同時將大大減少數倉中大量ETL任務、聚合表、報表,降低了數倉ETL的運維壓力和維護成本,DorisDB綜合性價比較原有的MySQL、Presto、ClickHouse等同類產品提升數倍以上。
未來,郵科院在DorisDB的應用和實踐上還有不少規劃:
·除了unique和duplicate數據模型,未來會將符合的數據場景遷移至aggregation模型,并使用物化視圖,進一步降低數倉開發維護成本,降低查詢延遲;
·DorisDB on ES的功能也值得我們深挖和探索,解決原生ES集群無法支持跨索引Join的能力;
·更多數據應用層的場景接入DorisDB,例如網點畫像服務、郵路路徑分析等,將進一步拓展DorisDB在實時數據寫入、批量數據更新場景中的應用;
·與科研數據分析平臺、數倉平臺深度打通,完善數據整體架構,作為數據團隊的基礎設施去保障穩定性和服務;
·考慮使用多云架構,自主可控的數倉架構可以靈活的在多云間切換遷移,降低單一云廠商的依賴,控制成本提高可用性。
·......
最后的最后,感謝DorisDB技術團隊給予的熱情、靠譜的答疑解惑和技術支持!!!