













跨越速運 x DorisDB:統一查詢引擎,強悍性能帶來極速體驗
跨越速運集團有限公司創建于2007年,目前服務網點超過3000家,覆蓋城市500余個,是中國物流服務行業獨角獸企業。跨越集團大數據中心負責全集團所有數據平臺組件的建設和維護,支撐20余條核心業務線,面向集團5萬多員工的使用。目前,大數據中心已建設數據查詢接口1W+,每天調用次數超過1千萬,TP99在1秒以下。我們利用DorisDB作為通用查詢引擎,有效解決了原架構大量查詢返回時間過長,性能達不到預期的問題。
“作者:張杰 跨越集團大數據運維架構師,負責集團公司大數據平臺的維護和建設”
一、業務背景
1、總體架構
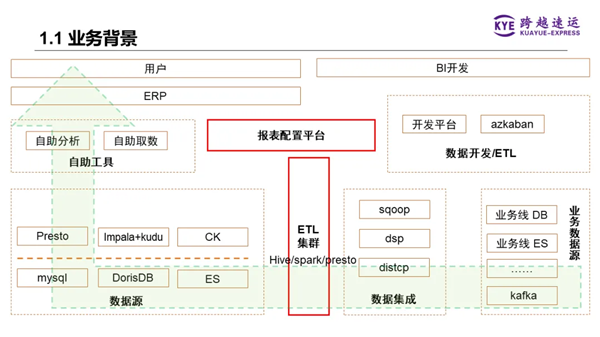
我們原始離線數倉的總體架構如下圖所示,數據從各個業務線的數據庫,比如MySQL等,通過數據集成工具匯聚到ETL集群(即Hadoop集群),再使用Hive、Spark、Presto等批量處理引擎進行數據倉庫的分層處理,然后將DW層和ADS層的數據推送到各種不同的查詢引擎。
在這些查詢引擎之上,有個統一的查詢API網關,應用層的自助分析工具或ERP系統前端通過調用這個API網關,將數據內容呈現給用戶。
二、業務痛點
該系統最大的痛點是查詢性能問題。公司對大數據查詢接口的響應延遲是有考核的,期望99%的查詢請求都能在1秒內返回,比如頁面ERP系統、手機端各類報表APP,用戶會隨時查看數據并進行生產環節調整,過慢的查詢響應會影響用戶體驗,甚至影響業務生產。針對復雜的SQL查詢場景,之前采用的Presto、Impala+Kudu、ClickHouse等系統,是遠遠達不到預期的。另外,針對各種復雜的數據分析業務場景,引入很多不同組件,導致了維護和使用成本非常高。
因此,我們急需一個新的查詢引擎,能統一查詢引擎,解決性能查詢問題,降低使用和維護成本。
三、OLAP引擎選型
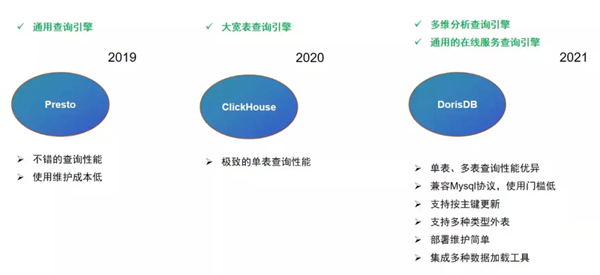
第一階段,在2019年,跨越集團大數據中心使用Presto作為通用的查詢引擎。此階段集團大數據中心數倉層基本用的是Hive,Presto可以直連Hive的特性讓我們無需做過多的改造,就可以直接生成查詢的API。從性能角度考慮,我們也會將數倉中的部分數據拷貝至獨立的Presto集群,和數倉ETL集群進行資源隔離。這套架構運行一年多之后,隨著業務需求越來越復雜,數據量越來越大,該基于Presto構建的集群性能急劇下降。
第二階段,為解決Presto集群性能不足的缺陷,我們基于ClickHouse開始構建新的通用查詢引擎。2020年我們使用ClickHouse構建了大量大寬表,將此前需要多層關聯的查詢逐步遷移到ClickHouse集群。通過這種方式,我們確實解決了此前面臨的性能問題。但與此同時,我們需要建設越來越多的大寬表,操作繁瑣運維困難。并且這種數據模型無法隨業務需求變化而快速改變,靈活性差。
第三階段,我們在2021年開始尋找其他能滿足我們需求的OLAP引擎,此時我們發現了DorisDB這個產品。首先關注到DorisDB的單表、多表關聯查詢的性能都非常優秀,能夠滿足我們對查詢延時的需求;DorisDB支持MySQL協議,讓我們開發同事在開發接口的時候學習和使用門檻非常低。另外,DorisDB還具備支持按主鍵更新、支持多種類型外表、部署運維簡單以及支持豐富的數據導入方式等特性。這些都是我們所需要的。
因此,我們開始逐步將以往的分析業務遷移到DorisDB集群上,將DorisDB作為大數據中心的通用查詢引擎。
四、DorisDB在跨越集團的應用
1、在線場景應用
當前我們每天在線數據接口的查詢請求量已經超過千萬。在引入DorisDB前,我們用了8到9種查詢引擎來支撐各種在線業務場景。大數據量的明細點查場景使用ElasticSearch作為支撐;對于查詢維度固定、可以提前預計算的報表場景,會使用MySQL;對于SQL查詢復雜,如果多表Join、子查詢嵌套的查詢場景,會使用Presto;實時更新的場景,則會使用Impala+Kudu的組合來支撐。

引入DorisDB后,目前已替換掉Presto和Impala+Kudu支撐的場景。ElasticSearch、MySQL以及ClickHouse,后續也可能會根據業務場景實際情況逐步替換為DorisDB。
下面詳細介紹一個實際在線場景的典型案例。如上圖,我們在原Presto系統上有一個包含200個字段的寬表聚合查詢。由于業務需求比較復雜,SQL語句有600多行。我們曾希望從業務邏輯上進行優化,但是并不容易,不能因為系統能力問題就一味要求業務方來遷就。現在我們使用10個節點相同配置的DorisDB替換原15臺相同配置服務器的Presto集群后,在沒有做什么業務邏輯變化的情況下,使用DorisDB明細模型,憑借DorisDB本身的高性能將查詢延時從5.7秒降低為1秒,性能是原Presto集群的近6倍。
2、OLAP場景應用
跨越集團的OLAP多維分析平臺是我們自研的一套BI系統。用戶可以根據自己業務場景選擇字段以及關聯條件等,以拖拉拽的方式生成數據的表格或圖表。最早我們支撐OLAP多維分析的后端引擎是Presto,在這類場景下的性能確實不盡如人意。因為性能問題,我們也沒辦法將這個工具推廣給更多的用戶使用。我們將后端查詢引擎替換為DorisDB后,性能提升非常明顯。我們將OLAP多維分析平臺向整個集團推廣,受到了越來越多的用戶好評。
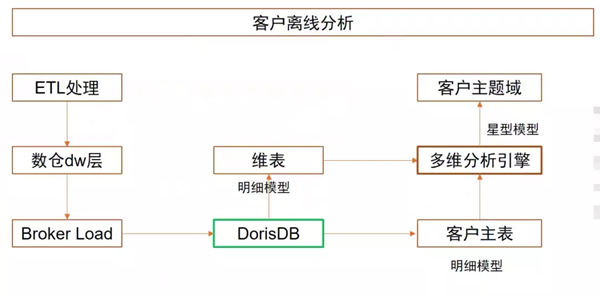
OLAP多維分析主要是離線分析為主,以客戶離線分析場景為例,數據經過ETL處理后,生成對應的DW層或ADS層數據,再通過Broker Load將數據按天導入DorisDB中。我們使用星型模型構建客戶主題域,客戶主表以明細模型在DorisDB中建表,同樣以明細模型創建維表。這樣用戶就可以在前端對客戶主題域的各種指標、各種維度進行拖拉拽,生成對應的表格和圖表。
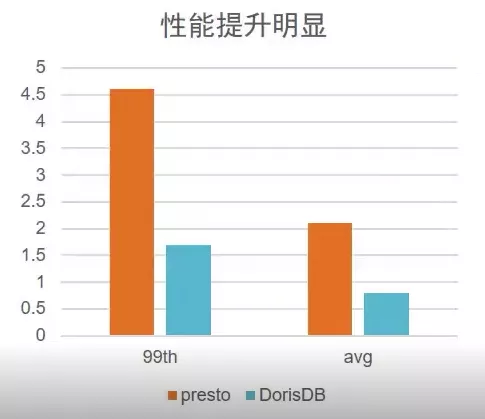
在客戶離線分析場景下,我們DorisDB上線前后業務邏輯沒有進行太多調整前提下,TP99從4.5秒下降到1.7秒,性能是原來的三倍(后續我們將嘗試開啟CBO優化器,預計會有更大性能提升)。絕大多數場景都能實現1s內返回,大大提升了用戶的體驗。
利用DorisDB的實時分析能力,我們還構建了實時OLAP多維分析。以運單實時分析場景為例,原本我們是用Hive每兩小時跑批的方式來實現的,將固定維度數據算好,結果寫入Presto上提供查詢,邏輯類似于離線數倉,并不能稱為真正的實時。引入DorisDB后,我們調整數據流轉邏輯,通過監聽Binlog將數據寫入Kafka,再通過Rontine Load的方式消費Kafka,將數據實時寫入DorisDB中。我們使用更新模型建立實時運單主表,將運單ID設置成主鍵,這樣每一筆運單更新后,都能實時更新到運單主表中。和離線分析場景一樣,使用星型模型構建運單主題域。
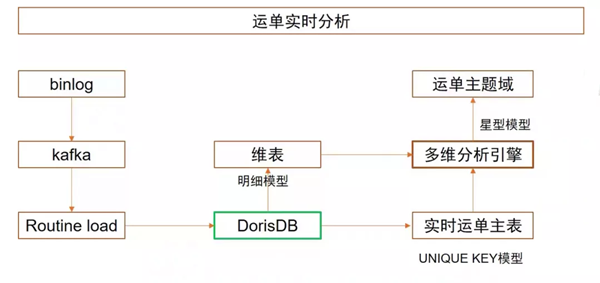
通過這樣的調整,以往每兩小時更新數據的運單主題域,現在可以實現秒級更新,成為名副其實的實時分析。另外此前需要依賴預計算,維度都是固定的,很多分析上功能受限。經改造后,除了大幅提升“實時”體驗外,在分析靈活性上的提升也非常明顯。實時體驗和靈活分析也成為OLAP多維分析平臺工具在實際服務中最大的亮點。
五、后續規劃
1、為了避免部分慢查詢影響整體的集群性能,后續會搭建多套DorisDB集群,按業務場景進行物理資源隔離。
2、DorisDB查詢Hive外表的功能,經內部測試比Presto查詢Hive的性能要好,后續會將原本Presto查詢Hive的場景無縫遷移到DorisDB上。
3、目前我們在DorisDB上寫入了很多實時數據,這些數據需要進行聚合等處理,我們正在嘗試使用調度工具,在DorisDB上進行5分鐘級、10分鐘級的輕量ETL處理。
4、開啟DorisDB的CBO優化器,進一步提升查詢性能。
最后,感謝鼎石為我們提供DorisDB這么好的產品,滿足了我們對性能強、功能全的查詢引擎產品的要求;感謝鼎石一直以來提供的技術支持,解決了我們在使用中遇到的各類問題。

















