要隱私還是要智能?無監督學習能帶來二者的統一嗎?
大數據文摘出品
來源:venturebeat
編譯:馬莉、楚陽
獲取用戶數據的方式即將被改變,數據“多即是好”的時代終將過去,用盡可能少的數據構建性能更好的模型才是大勢所趨。
在目前視數據為賺錢的致勝法寶之一的商業環境中,這個論斷聽上去不大靠譜,然而,這是企業應該做出的改變,而且事實上這并沒有聽上去那么冒險。
喂給模型的數據越多,它并非會越智能,因此,減少數據并不一定意味著模型性能的下降。
數據越多,問題越多
如果用戶數據的多少是決定企業競爭力強弱的因素,那么它會鼓勵企業家們尋找各種渠道來獲取更多的用戶數據,而這本身會帶來災難性后果。
眼下,數據泄露和損毀以及個人信息暴露的新聞到處都是,由身份盜竊和金融詐騙引起的事故令人痛心和惋惜,我們目睹著由無力保護用戶數據而導致的企業名譽受損、監管蒙羞以及由此而引起的用戶的強烈抵制態度。
數據隱私只是瘋狂獲取數據所帶來的問題之一,大規模的收集和管理數據本身會耗費巨大成本:計算成本、存儲成本、運營成本以及更多。我們正處于大數據和人工智能時代,但如果數據量要和人工智能同步成長,那么這些成本還將繼續飛漲。
企業恨不得知道有關客戶的一切數據,然而,沒有人會愿意自己的行為數據被記錄和分析,企業獲取得越多,客戶暴露得越多,這些數據一旦失竊,那最后的贏家將是偷數據的賊而非企業。
相比依賴數據,更要整合數據
如果我們可以更靈活地使用手頭收集來的數據,對其進行深入的分析和挖掘,就會發現其實并不需要原本想象的那么多的數據。
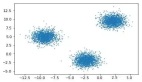
其中,關鍵一步就是實現從對個體數據的收集和依賴轉向對整合數據的分析和處理。比如,與其一個個的分析用戶IP,不如直接分析IP前綴來區分不同網絡分布下的用戶群體,同樣可以提升模型的性能。
這樣做的好處在于,我們可以使用群體特征來淡化個體特征從而起到了保護用戶個體隱私的效果。乍一聽可能怪怪的,但我們確實能用更少的數據訓練出更好的模型。
再比如,我們可以構建這樣一個特征,這個特征記錄了某個平臺上的交易總金額,而單個訂單的交易金額則被四舍五入到某一特定的閾值金額下,由此,我們便無須精確地知道個體用戶的交易金額。
另外,通過分析用戶群體的數量和行為,我們可以發掘用戶模式并預測其未來的趨勢,也就是說,我們可以在不必深入分析單個用戶的情況下獲取更有價值的信息。而且,派生數據可以產生派生信息,比如,通過分析IP范圍來推斷用戶工作在正常還是異常移動模式從而確定用戶是否在旅游而無需其酒店或航班信息。
這種技術標志著重大革新,我們的努力使我們更好地遵循著大數據時代的道德標準。
相比個人,無監督學習更關注群體
從群體數據中獲得的信息越多,需要加給個體的關注就越少,無監督學習使之成為可能。
如果沒有無監督學習,機器學習模型會逐個分析用戶數據以預測其行為,這不僅過多地暴露了個體用戶信息而且會到導致學習任務極其繁重。
當使用無監督學習時,模型會以群體視野審視用戶數據,通過分析群體用戶的數量和行為找出其內在聯系和用戶行為模式從而使模型具有更好的泛化性能。在這個過程中,我們只需要少量個體用戶數據用以劃分用戶群體,然后只需預測用戶群體的行為即可。
同時,企業需要主動建立起防御機制以保護用戶數據,黑客的惡意攻擊應該被提前檢測到以防止數據泄露。僅需要少量的數據就可以對群體用戶數據進行整體性分析以偵測欺詐和惡意攻擊的賬號。事實上,企業其實已經獲取到了足夠的數據,只是沒有深度挖掘而已。
全球范圍內的監管機制的進步表明,用戶數據將更私密且更透明,對于數據收集的管制也在不斷提高。然而,這并不意味著模型性能的下降,通過對數據做整體性分析并利用無監督學習和優秀的AI技術,我們可以在獲得高性能模型的同時保護好用戶隱私。
收集和管理數據的方式日新月異,無監督學習的優勢也因此而更加突出,尤其是在和監督學習比較時。監督學習模型需要大量數據,而大量數據會牽扯很多問題。但無監督學習并不需要大量的訓練數據,因此在一定程度上保護了用戶數據隱私,意義非凡。而且,有標簽的訓練數據本身可能存在偏見,這進一步突顯了無監督學習的優勢:通過在非結構化數據中尋找規律以確定分類,無監督學習不僅表現得客觀公正多了而且補償了以前模型中的不足。
金融從業人員立即意識到了無監督學習所能帶來的價值,因此目前,已經有銀行和支付機構主動地嘗試這些新的機器學習模型。事實上,無論是隱私侵犯、改善安全機制還是增加驗證程序都會給用戶帶來麻煩。而無監督學習使得企業可以給客戶提供良好的用戶體驗而略去不必要的麻煩。數字經濟時代,在風險管控、用戶體驗和數據道德之間取得平衡對企業來說是至關重要的。
今天,我們正在跨入倫理與智能共存的嶄新時代。
鏈接:https://venturebeat.com/2019/11/03/can-data-privacy-and-data-intelligence-coexist/
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】