谷歌發(fā)布最新零樣本學習看圖說話模型,多類型任務直接上手
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
谷歌新推出了弱監(jiān)督看圖說話模型SimVLM,能夠輕松實現(xiàn)零樣本學習(zero-shot)任務遷移。
從文字描述圖像到回答圖片相關問題,模型無需微調(diào)也能樣樣精通。

對于一般的視覺語言預訓練(VLP)模型,訓練數(shù)據(jù)集中要求包含大量精準標簽。而模型的任務遷移,則需要針對特定任務重新進行數(shù)據(jù)集的標簽標注。
總結(jié)下來,就是標注數(shù)據(jù)集不僅耗時耗力,還不能多任務通用。
能不能開發(fā)出一種又簡單又萬能的VLP模型呢?
谷歌新開發(fā)的這款模型使用了弱監(jiān)督學習進行模型訓練,通過利用大量的弱對齊圖像-文本對進行建模,簡化了VLP的訓練流程,大大降低了訓練的復雜性。
SimVLM使用前綴語言建模的單一目標進行端到端訓練,并直接將原始圖像作為輸入。這些設置允許模型對大規(guī)模的弱標記數(shù)據(jù)集進行利用,從而能夠更好地實現(xiàn)零樣本學習泛化效果。
SimVLM模型是如何實現(xiàn)的?
SimVLM模型的預訓練過程采用了前綴語言建模(PrefixLM)的單一目標,接受序列的前綴作為輸入,通過模型解碼器來預測其延續(xù)的內(nèi)容。
對于數(shù)據(jù)集中的圖像-文本對,圖像序列可視作其文本描述的前綴。
這種方法可以簡化訓練過程,最大限度地提高模型在適應不同任務設置方面的靈活性和通用性。
模型的主干網(wǎng)絡,則使用了在語言和視覺任務上均表現(xiàn)突出的Transformer架構(gòu)。
對輸入的原始圖像數(shù)據(jù)提取上下文patch,這里采用了ResNet卷積網(wǎng)絡。
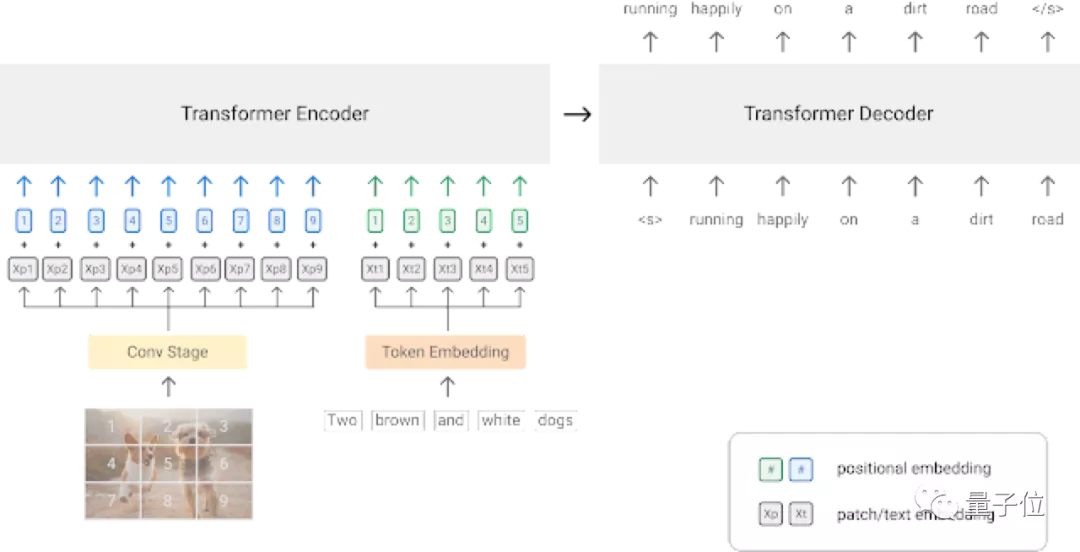
如上圖所示:視覺模態(tài)中,圖片被分割成多個patch,然后壓縮為一維序列。文本模態(tài)語句則被映射到了一個表征向量中。
本模型使用了包含大約1.8B噪聲的圖像-文本對ALIGN訓練集進行預訓練,以此來實現(xiàn)更好的零樣本學習泛化能力。
為了補償訓練集中的噪聲影響,訓練模型另外還使用了共800G的Colossal Clean Crawled Corpus (C4)數(shù)據(jù)集。
SimVLM模型基礎性能如何?
模型的預訓練完成后,需要在多模式任務中對模型進行微調(diào),以測試性能。
這里用到的多模式任務有:VQA、NLVR2、SNLI-VE、COCO Caption、NoCaps和Multi30K En-De。
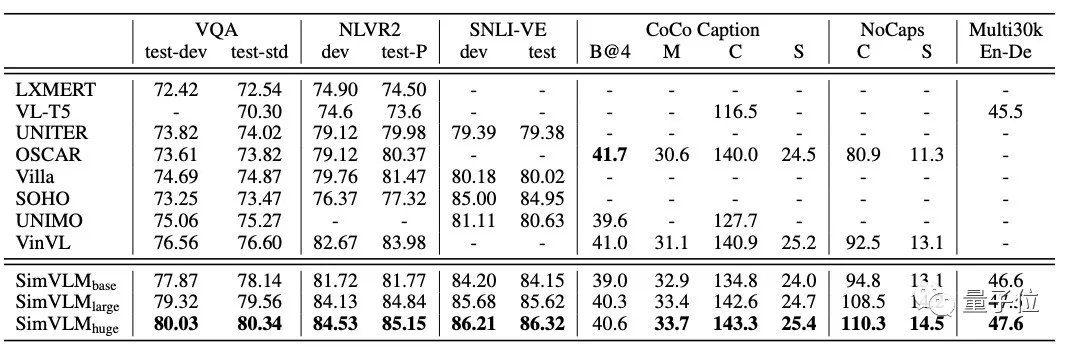
將SimVLM模型與現(xiàn)有的功能完善的模型進行比較,測試結(jié)果如上表所示,參與評估的SimVLM模型還包括了三種不同規(guī)模:8600萬參數(shù)、3.07億參數(shù)和6.32億參數(shù)。
跨模式任務的測試結(jié)果中,SimVLM模型的性能表現(xiàn)最好(數(shù)據(jù)越大越好),除了CoCo Caption的B@4指標,在其他任務上都取得了新的SOTA結(jié)果,充分證明了該模型的先進性。
SimVLM模型零樣本泛化
SimVLM模型在跨模式任務測試中可以取得不錯的性能表現(xiàn),那么它能否順利執(zhí)行零樣本跨模態(tài)轉(zhuǎn)移呢?
預訓練的SimVLM模型僅對文本數(shù)據(jù)進行微調(diào)或完全不進行微調(diào),通過圖像字幕、多語言字幕、開放式VQA和視覺文本生成等任務,對模型進行測試。
測試結(jié)果如下圖所示:

給定圖像和文本提示,預訓練模型無需微調(diào)即可預測圖像的內(nèi)容。

除此之外,未進行過微調(diào)的模型在德語字幕生成、數(shù)據(jù)集外的答案生成、基于圖像內(nèi)容的文字描述、開放式視覺問題回答等應用上均有不錯的表現(xiàn)。
為了量化SimVLM的零樣本學習性能,這里采用了預訓練的固化模型在COCO Caption和NoCaps上進行解碼,然后與監(jiān)督標準基線(Sup.)進行比較。
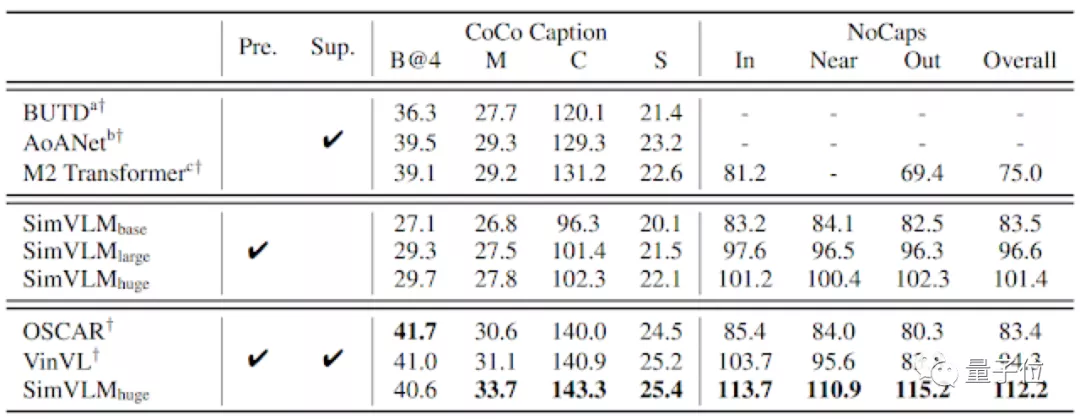
從結(jié)果對比上來看,即使沒有監(jiān)督微調(diào),SimVLM也可以達到有監(jiān)督的訓練質(zhì)量水平。
作者介紹
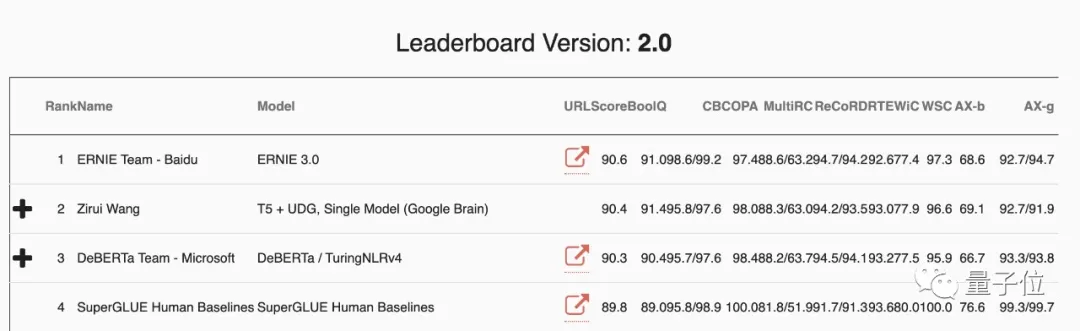
本研究的第一作者是谷歌學生研究員王子瑞,現(xiàn)就讀于卡內(nèi)基梅隆大學,曾以第一作者身份在ICLR、EMNLP、CVPR等頂會上發(fā)表了多篇論文。
截止到2020年12月20日,他在SuperGLUE數(shù)據(jù)集上獲得了第一個超過人類得分的SOTA性能(分數(shù)超過90),目前則被百度團隊趕超,位居第二。
這一次開發(fā)的SimVLM也在6個視覺語言基準測試中達到了單模型SOTA性能,并實現(xiàn)了基于文本引導的零樣本學習泛化能力。