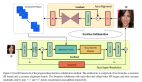
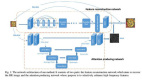
深度學習在單圖像超分辨率上的應用:SRCNN、Perceptual loss、SRResNet
單圖像超分辨率技術涉及到增加小圖像的大小,同時盡可能地防止其質量下降。這一技術有著廣泛用途,包括衛星和航天圖像分析、醫療圖像處理、壓縮圖像/視頻增強及其他應用。我們將在本文借助三個深度學習模型解決這個問題,并討論其局限性和可能的發展方向。
我們通過網頁應用程序的形式部署開發結果,允許在自定義圖像上測試文中的大多數方法,同樣你也可以查看我們的實例:http://104.155.157.132:3000/。
單圖像超分辨率:問題陳述
我們的目標是采用一個低分辨率圖像,產生一個相應的高分辨率圖像的評估。單圖像超分辨率是一個逆問題:多個高分辨率圖像可以從同一個低分辨率圖像中生成。比如,假設我們有一個包含垂直或水平條的 2×2 像素子圖像(圖 1)。不管條的朝向是什么,這四個像素將對應于分辨率降低 4 倍的圖像中的一個像素。通過現實中的真實圖像,一個人需要解決大量相似問題,使得該任務難以解決。

圖 1:從左到右依次是真值 HR 圖像、相應的 LR 圖像和一個訓練用來最小化 MSE 損失的模型的預測。
首先,讓我們先了解一個評估和對比模型的量化質量檢測方法。對于每個已實現的模型,我們會計算一個通常用于測量有損壓縮編解碼器重建質量的指標,稱之為峰值信噪比(PSNR/Peak Signal to Noise Ratio)。這一指標是超分辨率研究中使用的事實標準。它可以測量失真圖像與原始高質量圖像的偏離程度。在本文中,PSNR 是原始圖像與其評估版本(噪聲強度)之間圖像(信號強度)可能的最大像素值與最大均方誤差(MSE)的對數比率。
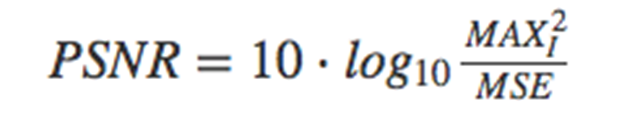
PSNR 值越大,重建效果越好,因此 PSNR 的最大值化自然會最小化目標函數 MSE。我們在三個模型中的兩個上使用了該方法。在我們的實驗中,我們訓練模型把輸入圖像的分辨率提升四倍(就寬度和高度而言)。在這一因素之上,哪怕提升小圖像的分辨率也變的很困難。比如,一張分辨率提升了八倍的圖像,其像素數量擴大了 64 倍,因此需要另外的原始格式的 64 倍內存存儲它,而這是在訓練之中完成的。我們已經在文獻常用的 Set5、Set14 和 BSD100 基準上測試了模型。這些文獻中引用了在這些數據集上進行測試的模型的結果,使得我們可以對比我們的結果和之前作者的結果。
這些模型已在 PyTorch 做了實現(http://pytorch.org/)。
為什么選擇深度學習?
提高圖像分辨率的最常用技術之一是插值(interpolation)。盡管易于實現,這一方法在視覺質量方面依然有諸多不足,比如很多細節(比如尖銳的邊緣)無法保留。



圖 2:最常見的插值方法產生的模糊圖像。自上而下依次是最近鄰插值、雙線性插值和雙立方插值。該圖像的分辨率提升了四倍。
更復雜的方法則利用給定圖像的內部相似性或者使用低分辨率圖像數據集及其對應的高質量圖像,有效地學習二者之間的映射。在基于實例的 SR 算法中,稀疏編碼方法是最為流行的方法之一。
這一方法需要找到一個詞典,允許我們把低分辨率圖像映射到一個中間的稀疏表征。此外,HR 詞典已被學習,允許我們存儲一個高分辨率圖像的評估。該流程通常涉及若干個步驟,且無法全部優化。理想情況下,我們希望把這些步驟合而為一,其中所有部分皆可優化。這種效果可以通過神經網絡來達到,網絡架構受到稀疏編碼的啟發。
更多信息請參見:http://www.irisa.fr/prive/kadi/Gribonval/SuperResolution.pdf。
SRCNN
SRCNN 是超越傳統方法的首個深度學習方法。它是一個卷積神經網絡,包含 3 個卷積層:圖像塊提取與表征、非線性映射和最后的重建。
圖像在饋送至網絡之前需要通過雙立方插值進行上采樣,接著它被轉化為 YCbCr 色彩空間,盡管該網絡只使用亮度通道(Y)。然后,網絡的輸出合并已插值的 CbCr 通道,輸出最終彩色圖像。我們選擇這一步驟是因為我們感興趣的不是顏色變化(存儲在 CbCr 通道中的信息)而只是其亮度(Y 通道);根本原因在于相較于色差,人類視覺對亮度變化更為敏感。
我們發現 SRCNN 很難訓練。它對超參數的變化非常敏感,論文中展示的設置(前兩層的學習率為 10-4,最后兩層的學習率為 10-5,使用 SGD 優化器)導致 PyTorch 實現輸出次優結果。我們觀察到在不同的學習率下,輸出結果有一些小的改變。最后我們發現,使性能出現大幅提升的是設置是:每層的學習率為 10-5,使用 Adam 優化器。最終網絡在 1.4 萬張 32×32 的子圖上進行訓練,圖像和原始論文中的圖像來自同樣的數據集(91 張圖像)。

圖 3:左上:雙立方插值,右上:SRCNN,左下:感知損失,右下:SRResNet。SRCNN、感知損失和 SRResNet 圖像由對應的模型輸出。
感知損失(Perceptual loss)
盡管 SRCNN 優于標準方法,但還有很多地方有待改善。如前所述,該網絡不穩定,你可能會想優化 MSE 是不是最佳選擇。
很明顯,通過最小化 MSE 獲取的圖像過于平滑。(MSE 輸出圖像的方式類似于高分辨率圖像,導致低分辨率圖像,[圖 1])。MSE 無法捕捉模型輸出和真值圖像之間的感知區別。想象一對圖像,第二個復制了第一個,但是改變了幾個像素。對人類來說,復制品和原版幾乎無法分辨,但是即使是如此細微的改變也能使 PSNR 顯著下降。
如何保存給定圖像的可感知內容?神經風格遷移中也出現了類似的問題,感知損失是一個可能的解決方案。它可以優化 MSE,但不使用模型輸出,你可以使用從預訓練卷積神經網絡中提取的高級圖像特征表示(詳見 https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py#L81)。這種方法的基礎在于圖像分類網絡(如 VGG)把物體細節的信息存儲在特征圖中。我們想讓自己提升后的圖像中的物體盡可能地逼真。
除了改變損失函數,網絡架構也需要重新建模。該模型比 SRCNN 深,使用殘差塊,在低分辨率圖像上進行大部分處理(加速訓練和推斷)。提升也發生在網絡內部。在這篇論文中(https://arxiv.org/abs/1603.08155),作者使用轉置卷積(transposed convolution,又叫解卷積,deconvolution),3×3 卷積核,步幅為 2。該模型輸出的「假」圖像看起來與棋盤格濾鏡效果類似。為了降低這種影響,我們還嘗試了 4×4 卷積的解卷積,以及最近鄰插值與 3×3 的卷積層,步幅為 1。最后,后者得到了最好的結果,但是仍然沒有完全移除「假」圖像。
與論文中描述的過程類似,我們的訓練流程包括從 MS‑COCO 近一萬張圖像中抽取的一些 288×288 隨機圖像組成的數據集。我們將學習率設置為 10-3,使用 Adam 優化器。與上面引用的論文不同,我們跳過了后處理(直方圖匹配),因為該步驟無法提供任何改進。
SRResNet
為了最大化 PSNR 性能,我們決定實現 SRResNet 網絡,它在標準基準上達到了當前最佳的結果。原論文(https://arxiv.org/abs/1609.04802)提到一種擴展方式,允許修復更高頻的細節。
和上文描述的殘差網絡一樣,SRResNet 的殘差塊架構基于這篇文章(http://torch.ch/blog/2016/02/04/resnets.html)。存在兩個小的更改:一個是 SRResNet 使用 Parametric ReLU 而不是 ReLU,ReLU 引入一個可學習參數幫助它適應性地學習部分負系數;另一個區別是 SRResNet 使用了圖像上采樣方法,SRResNet 使用了子像素卷積層。詳見:https://arxiv.org/abs/1609.07009。
SRResNet 生成的圖像和論文中呈現的結果幾乎無法區分。訓練用了兩天時間,訓練過程中,我們使用了學習率為 10-4 的 Adam 優化器。使用的數據集包括來自 MS‑COCO 的 96×96 隨機圖像,與感知損失網絡類似。
未來工作
還有一些適用于單圖像超分辨率的有潛力的深度學習方法,但由于時間限制,我們沒有一一測試。
這篇近期論文(https://arxiv.org/abs/1707.02921)提到使用修改后的 SRResNet 架構獲得了非常好的 PSNR 結果。作者移除殘差網絡中的批歸一化,把殘差層的數量從 16 增加到 32。然后把網絡在 NVIDIA Titan Xs 上訓練七天。我們通過更快的迭代和更高效的超參數調整,把 SRResNet 訓練了兩天就得到了結果,但是無法實現上述想法。
我們的感知損失實驗證明 PSNR 可能不是一個評估超分辨率網絡的合適指標。我們認為,需要在不同類型的感知損失上進行更多研究。我們查看了一些論文,但是只看到網絡輸出的 VGG 特征圖表示和真值之間的簡單 MSE。現在尚不清楚為什么 MSE(每像素損失)在這種情況中是一個好的選擇。
另一個有潛力的方向是生成對抗網絡。這篇論文(https://arxiv.org/abs/1609.04802)使用 SRResNet 作為 SRGAN 架構的一部分,從而擴展了 SRResNet。該網絡生成的圖像包含高頻細節,比如動物的皮毛。盡管這些圖像看起來更加逼真,但是 PSNR 的評估數據并不是很好。



圖 4:從上到下:SRResNet 實現生成的圖像、SRResNet 擴展生成的圖像,以及原始圖像
結論
本文中,我們描述了用于單圖像超分辨率的三種不同的卷積神經網絡實驗,下圖總結了實驗結果。

圖 5:本文討論模型的優缺點
使用 PSNR 在標準基準數據集上進行度量時,即使簡單的三層 SRCNN 也能夠打敗大部分非機器學習方法。我們對感知損失的測試證明,該指標不適合評估我們的模型性能,因為:我們能夠輸出美觀的圖像,但使用 PSNR 進行評估時,竟然比雙立方插值算法輸出的圖像差。最后,我們重新實現了 SRResNet,在基準數據集上重新輸出當前最優的結果。