這個模型腦補能力比GAN更強,ETH超分辨率模型SRFlow
近日,來自蘇黎世聯邦理工學院計算機視覺實驗室的研究者提出了一種超分辨率模型 SRFlow。該模型具備比 GAN 更強的腦補能力,能夠根據低分辨率輸入學習輸出的條件分布。該論文已被 ECCV 2020 收錄。
超分辨率是一個不適定問題(ill-posed problem),它允許對給定的低分辨率圖像做出多種預測。這一基礎事實很大程度上被很多當前最優的深度學習方法所忽略,這些方法將重建和對抗損失結合起來,訓練確定性映射(deterministic mapping)。
近日,來自蘇黎世聯邦理工學院計算機視覺實驗室的研究者提出了一種新的超分辨率模型 SRFlow。該模型是一種基于歸一化流的超分辨率方法,具備比 GAN 更強的腦補能力,能夠基于低分辨率輸入學習輸出的條件分布。

論文地址:https://arxiv.org/pdf/2006.14200.pdf
項目地址:https://github.com/andreas128/SRFlow?
研究者使用單個損失函數,即負對數似然(negative log-likelihood)對模型進行訓練。SRFlow 直接解釋了超分辨率問題的不適定性,并學習預測不同逼真度的高分辨率圖像。此外,研究者利用 SRFlow 學到的強大圖像后驗來設計靈活的圖像處理技術,能夠通過傳輸其他圖像的內容來增強超分辨率圖像。
該研究展示了基于人臉圖像以及其他超分辨率圖像實驗,結果表明 SRFlow 在 PSNR 和感知質量度量上都優于當前最優的 GAN 方法,同時 SRFlow 允許探索超分辨率解空間,以實現生成圖像的多樣性。
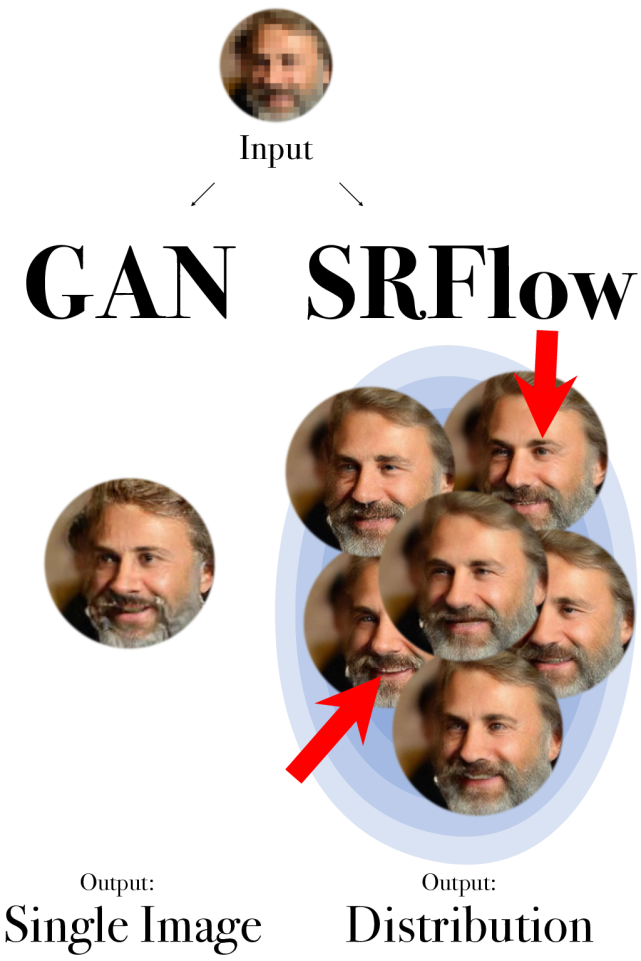
下圖展示了基于 GAN 的 ProgFSR 與基于歸一化流的 SRFlow 的對比結果:
SRFlow 方法簡介
研究者將超分辨率公式化為:給定低分辨率(LR)輸入圖像,學習高分辨率(HR)圖像的條件概率分布問題。該方法旨在通過捕獲基于自然圖像流形的所有可能超分辨率(SR)圖像,來明確地解決超分辨率問題的不適定性。
為此,研究者設計了條件歸一化流架構,使用基于對數似然的訓練來學習豐富的分布。
用于超分辨率的條件歸一化流
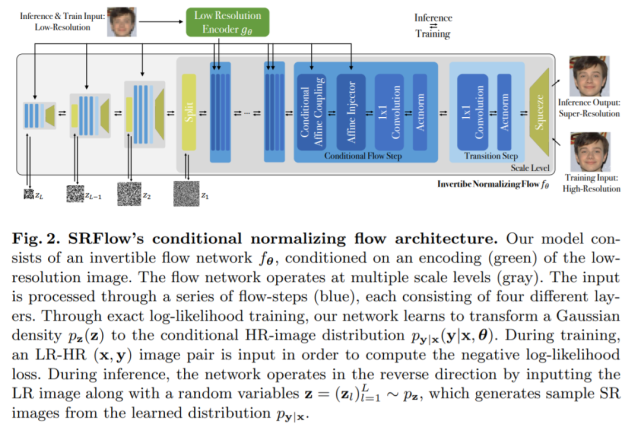
超分辨率的目標是通過生成缺失的高頻細節,來預測給定低分辨率圖像 x 的更高分辨率版本 y。大多數當前方法學習確定性映射 x→y,而該研究旨在獲取與 LR 圖像 x 對應的自然 HR 圖像 y 的全條件分布。
這是一個頗具挑戰性的問題,因為該模型必須捕獲多種可能的 HR 圖像,而不僅僅是預測單個 SR 輸出。該研究的目的是在給定大量 LR-HR 訓練對的情況下,以純數據驅動的方式訓練分布的參數 θ。
條件流層
流層(flow-layer)f^n_θ 的設計需格外精細,以確保 well-conditioned inverse 和易于處理的雅可比行列式。[10,11] 首次解決了該挑戰,最近也有很多研究者對此感興趣 [5,14,21]。
該研究從無條件 Glow 架構 [21] 開始,該架構本身基于 RealNVP [11]。這些架構使用的流層可以以直接的方式設置為有條件的 [3,49]。研究者對其進行了概述,并介紹了該研究提出的 Affine Injector 層。
架構
SRFlow 的架構如圖 2 所示:
應用和圖像處理
研究者將 SRFlow 網絡用于多項應用和圖像處理任務,該研究的技術利用了 SRFlow 網絡的兩個關鍵優勢,而這是基于 GAN 的超分辨率的方法 [47] 所不具備的。
首先,該研究的網絡對 HR 圖像空間內的分布建模,而不僅僅是預測單個圖像。因此,它通過捕獲多個可能的 HR 預測而具有極大的靈活性。這就允許使用其它指導信息或隨機采樣來探索不同的預測。
其次,該流網絡 f_θ(y; x) 是完全可逆的編碼器 - 解碼器。因此,任何 HR 圖像都可以被編碼成到潛在空間(latent space)中,并精確地重構為。這種雙射的對應關系允許在潛在空間和圖像空間中靈活操作。
隨機超分辨率
給定 LR 圖像 x,我們可以通過采樣不同的 SR 預測,探索 SRFlow 學習到的分布。正如基于流的模型的觀察結果那樣,方差較小的采樣可以實現最佳結果 [21]。因此,研究者使用具有方差 τ(也稱為溫度)的高斯分布。當 τ = 0.8 時,結果如下圖 3 所示:

LR 一致性風格遷移
對 LR 圖像 x 進行超分辨處理時,SRFlow 允許遷移現有 HR 圖像的風格。
下圖 4 展示了圖像中面部特征、發色和眼睛顏色的風格遷移:

潛在空間歸一化
研究者利用 SRFlow 網絡 f_θ 的可逆性和學得的超分辨率后驗,開發了更先進的圖像處理技術。該方法的核心思想是將包含所需內容的任意 HR 圖像映射到潛在空間,在該空間中對潛在統計量(latent statistics)進行歸一化,使其與給定 LR 圖像中的低頻信息一致。令 x 為低分辨率圖像,為任意高分辨率圖像(不一定與 LR 圖像 x 一致)。該研究的目標是獲得 HR 圖像 y,其包含的圖像內容,并與 LR 圖像 x 一致。
圖像內容遷移
該研究旨在通過傳輸其他圖像的內容來操縱 HR 圖像。令 x 為 LR 圖像,y 為對應的 HR 圖像。如要處理超分辨率圖像,則是 x 的 SR 樣本。但,我們也可以通過將 x 設置為 y 的 down-scaled 版本,來操縱現有的 HR 圖像 y。研究人員將其他圖像的內容直接嵌入 y 的圖像空間,進而操縱 y,如下圖 5 所示:

圖像恢復
研究者將學得的圖像后驗應用于圖像恢復任務,進而其能力。注意,此處研究者采用了相同的 SRFlow 網絡,該網絡僅針對超分辨率進行訓練。研究者探索了對圖像中的高頻信息產生主要影響的因素,如噪聲和壓縮偽影。
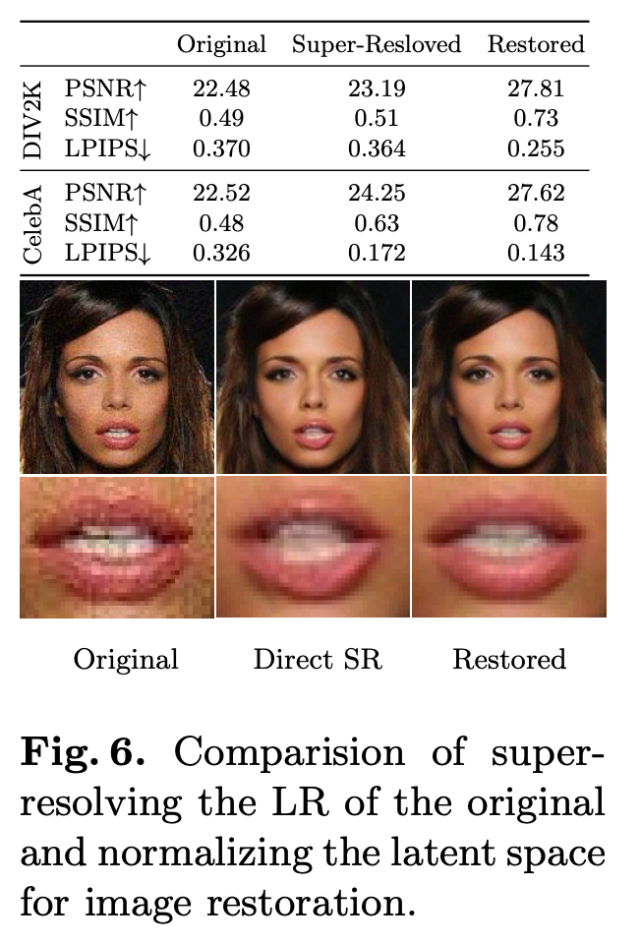
實驗
研究者將其提出的方法與當前 SOTA 方法進行了對比,并執行了控制變量分析。
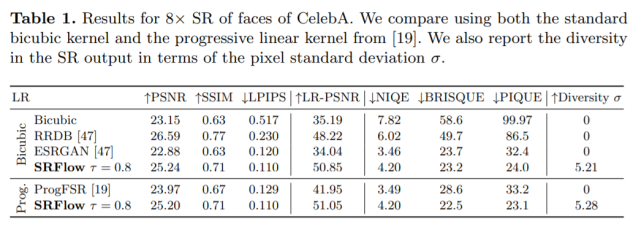
人臉超分辨率
該研究基于 CelebA 測試集中的 5000 張圖像,評估了 SRFlow 在人臉超分辨率圖像任務中的性能,并與 bicubic、RRDB [47]、ESRGAN [47] 和 ProgFSR [19] 進行了對比。

通用超分辨率
研究者在 DIV2K 驗證集上評估了 SRFlow 在通用超分辨率任務中的性能,并與 Bicubic、EDSR 、RRDB、ESRGAN 和 RankSRGAN 進行了對比。
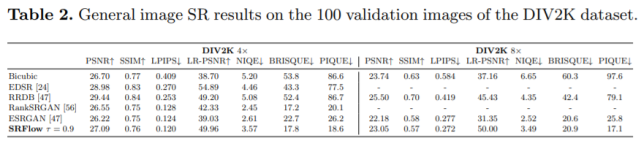
與基于 GAN 的方法 [47,56] 相比,SRFlow 實現了明顯更好的 PSNR、LPIPS 和 LR-PSNR 結果,并在 PIQUE 和 BRISQUE 方面也得到了出色的結果。
圖 8 中的可視化結果表明,EDSR 和 RRDB 的感知效果較差,這些結果幾乎不會產生高頻細節。相比之下,與 ESRGAN 相比,SRFlow 能夠生成豐富的細節,實現了良好的感知效果。
如第一行所示,ESRGAN 生成的圖像在多個位置存在嚴重的褪色偽影(discolored artifact)和振鈴效應(ringing pattern)。而 SRFlow 能夠生成更加穩定和一致的結果。

控制變量研究
此外,為了研究深度和寬度這兩個因素的影響,研究者進行了控制變量實驗。圖 9 顯示了在 CelebA 數據集上的結果:

如何根據任務需求搭配恰當類型的數據庫?
在AWS推出的白皮書《進入專用數據庫時代》中,介紹了8種數據庫類型:關系、鍵值、文檔、內存中、關系圖、時間序列、分類賬、領域寬列,并逐一分析了每種類型的優勢、挑戰與主要使用案例。