超實用的圖像超分辨率重建技術原理與應用
原創【51CTO.com原創稿件】不知道大家有沒有過這種煩惱:在電腦上看到有趣的地方,想要截個圖,奈何分辨率太小,放大后看不清?保存了有趣的圖片/表情包,想要用的時候竟變得模糊?每每遇到這種情況,就像一個800度近視的人,摘下眼鏡,便是恐慌,有木有!Don't worry!今天就來幫你解決這一難題,還您一個高清無碼的世界!
一,什么是圖像超分辨率重建技術
簡單的說,就是將一張(或多張)分辨率較低的圖像,通過一定的技術手段,生成一張分辨率高的圖像。
比如這樣一張表情圖片:
(圖1)
分辨率是 125 x 75,圖片的細節,包括***行字,從遠處看,都容易看不清,如果想看的清楚,我們想到的***個辦法是放大圖片。
我們按像素放大這張圖片:
如果我們在畫圖軟件/word/瀏覽器里面調節顯示比例,去看這幅圖片把每個像素都放大,到400%的尺寸,但是不增加像素數目(也就是說,把一個像素 從原來1x1的寬高,顯示到4x4的寬高下),顯示一張圖片得到的效果是這樣:
(圖2)
如果我們把放大400%后的圖像截圖,生成了一張寬高值都x4的新圖,里面相應的4x4 = 16個像素,代表原來小圖的一個像素,從圖1生成圖2(圖像分辨率寬高變為4倍),就是做了一次超分辨率重建。但是,效果極差!
其實我們期待,圖片放大后,圖像細節(圖形的邊緣輪廓,字體等)能夠清晰,比如下面這個樣子:
(圖3)
如果能從圖1 生成 圖3(圖像分辨率寬高變為4倍),就是一次非常理想的超分辨率重建了。
二,圖像超分辨率重建技術的應用
我們上面說到了一個例子,把一個分辨率低的表情圖片,經過處理,變成了原始4倍寬高的新圖片,這里并沒有看到什么意義,但是在實際中,圖像超分辨率重建技術是非常有用的。
在監控領域
我們經常看到一些影視作品中,警察在監控畫面上,拉近放大看犯罪嫌疑人的臉。這個放大過程,其實并沒有那么簡單,很多攝像頭是不具備光學變焦能力的,即使攝像頭帶有光學變焦能力,但是監控畫面很多情況下是去看之前的錄像,所以光學變焦也沒用,這時通過超分辨率重建技術放大有限區域內的像素,形成清晰的圖像,是非常有意義的
衛星圖像等遙感領域
衛星一般離地幾百km采集地面的各種圖像,圖像上面兩個像素點,在地球上的實際距離,可能是1km(已經算是比較高分辨率)到幾百km(低分辨率),將衛星圖像,做超分辨率重建,將大大提升后續的處理精度
醫學圖像領域
醫學圖像的分辨率,受限于X光機、核磁共振掃描儀等設備的物理能力,通過超分辨率重建技術,增加醫學圖像的分辨率,將給醫生診斷提供更大幫助
其它通用圖像處理領域
- (低分辨率)老照片,老圖像重建
- 低分辨率)視頻重建
- 圖像壓縮傳輸
傳輸時采取低分辨率視頻,顯示時通過超分辨率重建顯示原始分辨率
三,傳統的圖像超分辨率重建技術簡介
基于插值的技術
什么是插值?給個小白版本的解釋,我們用一張非常小的圖來說明:一張圖像的分辨率 3 x 2,我們要把它變成 6 x 4
原圖每個像素點的亮度值是:

我們建立一個6 x 4的圖像,把這6個已經知道的點,放在他們大概應該在新圖的位置:
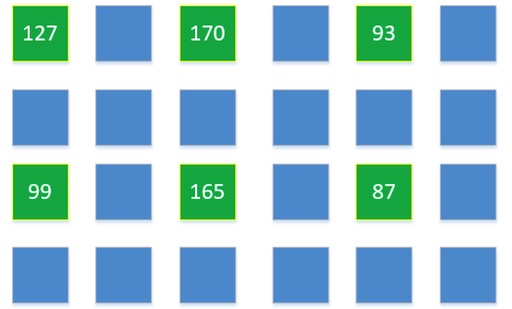
已經知道6x4新圖中6個已知的點(綠色),下面需要求剩余18個點(藍色)的值。
通過某個點周圍若干個已知點的值,以及周圍點和此點的位置關系,根據一定的公式,算出此點的值,就是插值法。
如何把原圖像的點擺放在新圖中(確定具體坐標);未知的點計算時,需要周圍多少個點參與,公式如何。不同的方案選擇,就是不同的插值算法。圖像處理中,常用的插值算法有:最鄰近元法,雙線性內插法,三次內插法等等。
但是實際上,通過這些插值算法,提升的圖像細節有限,所以使用較少。通常,通過多幅圖像之間的插值算法來重建是一個手段。另外,在視頻超分辨重建中,通過在兩個相鄰幀間插值添加新幀的手段,可以提升視頻幀率,減少畫面頓挫感。
基于重建的方法
以下都是一些傳統的基于重建超分辨率算法,涉及到概率論,集合論等相關領域,這里只列出,不做介紹:
- 凸集投影法(POCS)
- 貝葉斯分析方法
- 迭代反投影法(IBP)
- ***后驗概率方法
- 正規化法
- 混合方法
基于重建的方法通常基于多幀圖像,需要結合先驗知識(通常為平滑性)。
基于學習的方法(非深度學習)
以下為傳統的基于學習的超分辨率方法,這里只列出,不做介紹:
- Example-based方法
- 鄰域嵌入方法
- 支持向量回歸方法
- 虛幻臉
- 稀疏表示法
這些方法,都屬于機器學習領域,但是沒有使用深度學習方法。
四,基于深度學習的圖像超分辨率重建技術
深度學習介紹
深度學習是機器學習的一個分支,所以首先介紹下機器學習:
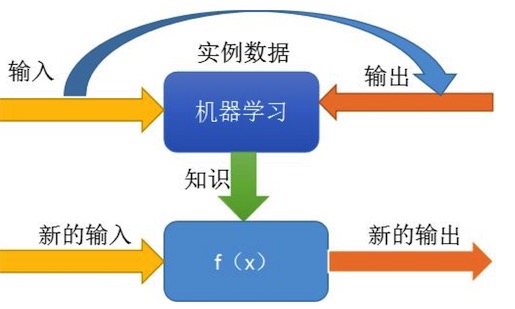
我們給機器(計算機上的程序)已知的輸入、輸出,讓它去找規律出來(知識發現),然后我們讓它根據找到的規律,用新的輸入算出新的輸出來,并對這個輸出結果做評價,如果合適就正向鼓勵,如果結果不合適,就告訴機器這樣不對,讓它重新找規律。
其實這個過程在模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。機器學習的本質就是讓機器根據已有的數據,去分析出一個模型來表示隱藏在這些數據背后的規律(函數)。深度學習就是利用人工神經網絡模型進行機器學習的方法。
人工神經網絡是,人為的構造出一些處理節點(模擬腦神經元),每個節點有個函數,處理幾個輸入,生成若干輸出,每個節點與其它節點組合,綜合成一個模型(函數)。
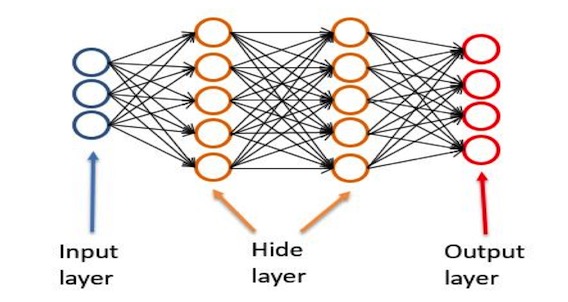
從左到右分別是輸出層, 隱藏層,輸出層。輸入層負責接受輸入,輸出層負責輸出結果,隱藏層負責中間的計算過程。
隱藏層的每一個節點,就是一個處理函數。隱藏層的結構,也就是層數,節點數,還有每個節點的函數將決定整個神經網絡的處理結果。
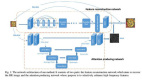
通過深度學習進行圖像超分辨率重建的原理
既然深度學習可以通過數據加訓練找到一個模型,去描述其背后的規律,那么我們就把它應用在圖像超分辨率重建領域來。
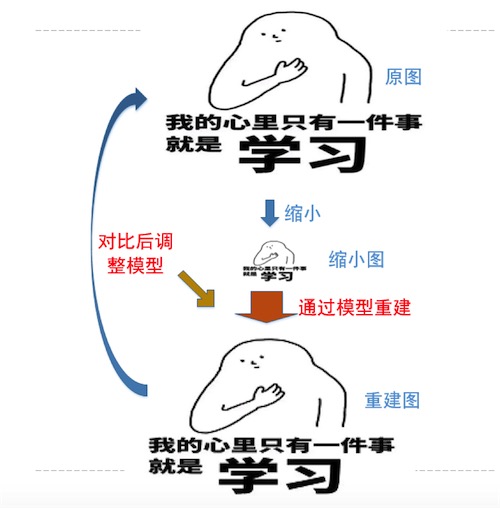
過程如下:
- 首先我們找到一組原始圖像P1;
- 將這組圖片降低分辨率為一組圖像P2;
- 通過人工神經網絡,將P2超分辨率重建為P3(P3和P1分辨率一樣)
- 通過PSNR等方法比較P1與P3,驗證超分辨率重建的效果,根據效果調節人工神經網絡中的節點模型和參數
- 反復執行,直到第四步比較的結果滿意
過程如下圖:
對于神經網絡模型選擇、參數選擇的不同,形成不同的方案,下面將分別進行簡單介紹。
基于深度學習進行圖像超分辨率重建的方案
基于深度學習的方案目前有很多種,這里列出部分,并對其中***個和***一個稍作介紹,感興趣的同學可以自行搜索詳細介紹、代碼、相關訓練集,也可使用自己生成的訓練集。
SRCNN
(Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014)
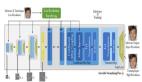
SRCNN是深度學習用在超分辨率重建上的開山之作。SRCNN的網絡結構非常簡單,僅僅用了三個卷積層,網絡結構如下圖所示。
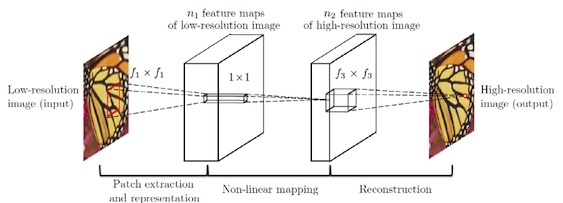
SRCNN首先使用雙三次(bicubic)插值將低分辨率圖像放大成目標尺寸,接著通過三層卷積網絡擬合非線性映射,***輸出高分辨率圖像結果。作者將三層卷積的結構解釋成三個步驟:圖像塊的提取和特征表示,特征非線性映射和最終的重建。
三個卷積層使用的卷積核的大小分為為9x9,,1x1和5x5,前兩個的輸出特征個數分別為64和32。用Timofte數據集(包含91幅圖像)和ImageNet大數據集進行訓練。使用均方誤差(Mean Squared Error, MSE)作為損失函數,有利于獲得較高的PSNR。
FSRCNN
(Accelerating the Super-Resolution Convolutional Neural Network, ECCV2016)
ESPCN
(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, CVPR2016)
VDSR
(Accurate Image Super-Resolution Using Very Deep Convolutional Networks, CVPR2016)
DRCN
(Deeply-Recursive Convolutional Network for Image Super-Resolution, CVPR2016)
RED
(Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections, NIPS2016)
DRRN
(Image Super-Resolution via Deep Recursive Residual Network, CVPR2017)
LapSRN
(Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution, CVPR2017)
SRDenseNet
(Image Super-Resolution Using Dense Skip Connections, ICCV2017)
DenseNet是CVPR2017的best papaer獲獎論文
SRGAN(SRResNet)
(Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, CVPR2017)
在這篇文章中,將生成對抗網絡(Generative Adversarial Network, GAN)用在了解決超分辨率問題上
EDSR
(Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW2017)
EDSR是NTIRE2017超分辨率挑戰賽上獲得冠軍的方案。如論文中所說,EDSR最有意義的模型性能提升是去除掉了SRResNet多余的模塊,從而可以擴大模型的尺寸來提升結果質量。EDSR的網絡結構如下圖所示。
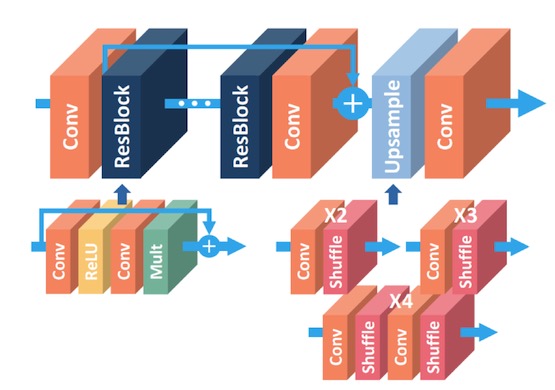
可以看到,EDSR在結構上與SRResNet相比,就是把批規范化處理(batch normalization, BN)操作給去掉了。文章中說,原始的ResNet最一開始是被提出來解決高層的計算機視覺問題,比如分類和檢測,直接把ResNet的結構應用到像超分辨率這樣的低層計算機視覺問題,顯然不是***的。由于批規范化層消耗了與它前面的卷積層相同大小的內存,在去掉這一步操作后,相同的計算資源下,EDSR就可以堆疊更多的網絡層或者使每層提取更多的特征,從而得到更好的性能表現。EDSR用L1范數樣式的損失函數來優化網絡模型。在訓練時先訓練低倍數的上采樣模型,接著用訓練低倍數上采樣模型得到的參數來初始化高倍數的上采樣模型,這樣能減少高倍數上采樣模型的訓練時間,同時訓練結果也更好。
【作者簡介】曾小偉,現任PP云技術副總監,圖像編解碼、高性能計算出身,輔修AI(NLP方向),10年以上流媒體服務端開發及架構設計經驗。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】