













Flink SQL 知其所以然之維表 Join 的性能優化之路(上)附源碼
本文轉載自微信公眾號「大數據羊說」,作者antigeneral了呀 。轉載本文請聯系大數據羊說公眾號。
1.序篇
源碼公眾號后臺回復1.13.2 sql lookup join獲取。
廢話不多說,咱們先直接上本文的目錄和結論,小伙伴可以先看結論快速了解博主期望本文能給小伙伴們帶來什么幫助:
- 背景及應用場景介紹:博主期望你能了解到,flink sql 提供了輕松訪問外部存儲的 lookup join(與上節不同,上節說的是流與流的 join)。lookup join 可以簡單理解為使用 flatmap 訪問外部存儲數據然后將維度字段拼接到當前這條數據上面
- 來一個實戰案例:博主以曝光用戶日志流關聯用戶畫像(年齡、性別)維表為例介紹 lookup join 應該達到的關聯的預期效果。
- flink sql lookup join 的解決方案以及原理的介紹:主要介紹 lookup join 的在上述實戰案例的 sql 寫法,博主期望你能了解到,lookup join 是基于處理時間的,并且 lookup join 經常會由于訪問外部存儲的 qps 過高而導致背壓,產出延遲等性能問題。我們可以借鑒在 DataStream api 中的維表 join 優化思路在 flink sql 使用 local cache,異步訪問維表,批量訪問維表三種方式去解決性能問題。
- 總結及展望:官方并沒有提供 批量訪問維表 的能力,因此博主自己實現了一套,具體使用方式和原理實現敬請期待下篇文章。
2.背景及應用場景介紹
維表作為 sql 任務中一種常見表的類型,其本質就是關聯表數據的額外數據屬性,通常在 join 語句中進行使用。比如源數據有人的 id,你現在想要得到人的性別、年齡,那么可以通過用戶 id 去關聯人的性別、年齡,就可以得到更全的數據。
維表 join 在離線數倉中是最常見的一種數據處理方式了,在實時數倉的場景中,flink sql 目前也支持了維表的 join,即 lookup join,生產環境可以用 mysql,redis,hbase 來作為高速維表存儲引擎。
Notes:
在實時數倉中,常用實時維表有兩種更新頻率
實時的更新:維度信息是實時新建的,實時寫入到高速存儲引擎中。然后其他實時任務在做處理時實時的關聯這些維度信息。
周期性的更新:對于一些緩慢變化維度,比如年齡、性別的用戶畫像等,幾萬年都不變化一次的東西??,實時維表的更新可以是小時級別,天級別的。
3.來一個實戰案例
來看看在具體場景下,對應輸入值的輸出值應該長啥樣。
需求指標:使用曝光用戶日志流(show_log)關聯用戶畫像維表(user_profile)關聯到用戶的維度之后,提供給下游計算分性別,年齡段的曝光用戶數使用。此處我們只關心關聯維表這一部分的輸入輸出數據。
來一波輸入數據:
曝光用戶日志流(show_log)數據(數據存儲在 kafka 中):
| log_id | timestamp | user_id |
|---|---|---|
| 1 | 2021-11-01 00:01:03 | a |
| 2 | 2021-11-01 00:03:00 | b |
| 3 | 2021-11-01 00:05:00 | c |
| 4 | 2021-11-01 00:06:00 | b |
| 5 | 2021-11-01 00:07:00 | c |
用戶畫像維表(user_profile)數據(數據存儲在 redis 中):
| user_id(主鍵) | age | sex |
|---|---|---|
| a | 12-18 | 男 |
| b | 18-24 | 女 |
| c | 18-24 | 男 |
注意:redis 中的數據結構存儲是按照 key,value 去存儲的。其中 key 為 user_id,value 為 age,sex 的 json。如下圖所示:
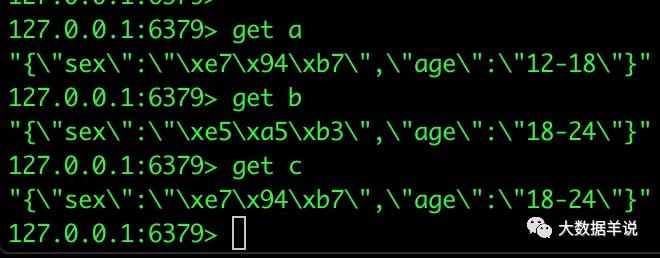
user_profile redis
預期輸出數據如下:
| log_id | timestamp | user_id | age | sex |
|---|---|---|---|---|
| 1 | 2021-11-01 00:01:03 | a | 12-18 | 男 |
| 2 | 2021-11-01 00:03:00 | b | 18-24 | 女 |
| 3 | 2021-11-01 00:05:00 | c | 18-24 | 男 |
| 4 | 2021-11-01 00:06:00 | b | 18-24 | 女 |
| 5 | 2021-11-01 00:07:00 | c | 18-24 |
flink sql lookup join 登場。下面是官網的鏈接。
https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sql/queries/joins/#lookup-join
4.flink sql lookup join
4.1.lookup join 定義
以上述案例來說,lookup join 其實簡單理解來,就是每來一條數據去 redis 里面摟一次數據。然后把關聯到的維度數據給拼接到當前數據中。
熟悉 DataStream api 的小伙伴萌,簡單來理解,就是 lookup join 的算子就是 DataStream api 中的 flatmap 算子中處理每一條來的數據,針對每一條數據去訪問用戶畫像的 redis。(實際上,flink sql api 中也確實是這樣實現的!sql 生成的 lookup join 代碼就是繼承了 flatmap)
4.2.上述案例解決方案
來看看上述案例的 flink sql lookup join sql 怎么寫:
- CREATE TABLE show_log (
- log_id BIGINT,
- `timestamp` as cast(CURRENT_TIMESTAMP as timestamp(3)),
- user_id STRING,
- proctime AS PROCTIME()
- )
- WITH (
- 'connector' = 'datagen',
- 'rows-per-second' = '10',
- 'fields.user_id.length' = '1',
- 'fields.log_id.min' = '1',
- 'fields.log_id.max' = '10'
- );
- CREATE TABLE user_profile (
- user_id STRING,
- age STRING,
- sex STRING
- ) WITH (
- 'connector' = 'redis',
- 'hostname' = '127.0.0.1',
- 'port' = '6379',
- 'format' = 'json',
- 'lookup.cache.max-rows' = '500',
- 'lookup.cache.ttl' = '3600',
- 'lookup.max-retries' = '1'
- );
- CREATE TABLE sink_table (
- log_id BIGINT,
- `timestamp` TIMESTAMP(3),
- user_id STRING,
- proctime TIMESTAMP(3),
- age STRING,
- sex STRING
- ) WITH (
- 'connector' = 'print'
- );
- -- lookup join 的 query 邏輯
- INSERT INTO sink_table
- SELECT
- s.log_id as log_id
- , s.`timestamp` as `timestamp`
- , s.user_id as user_id
- , s.proctime as proctime
- , u.sex as sex
- , u.age as age
- FROM show_log AS s
- LEFT JOIN user_profile FOR SYSTEM_TIME AS OF s.proctime AS u
- ON s.user_id = u.user_id
這里使用了 for SYSTEM_TIME as of 時態表的語法來作為維表關聯的標識語法。
Notes:
實時的 lookup 維表關聯能使用處理時間去做關聯。
運行結果如下:
| log_id | timestamp | user_id | age | sex |
|---|---|---|---|---|
| 1 | 2021-11-01 00:01:03 | a | 12-18 | 男 |
| 2 | 2021-11-01 00:03:00 | b | 18-24 | 女 |
| 3 | 2021-11-01 00:05:00 | c | 18-24 | 男 |
| 4 | 2021-11-01 00:06:00 | b | 18-24 | 女 |
| 5 | 2021-11-01 00:07:00 | c | 18-24 | 男 |
flink web ui 算子圖如下:
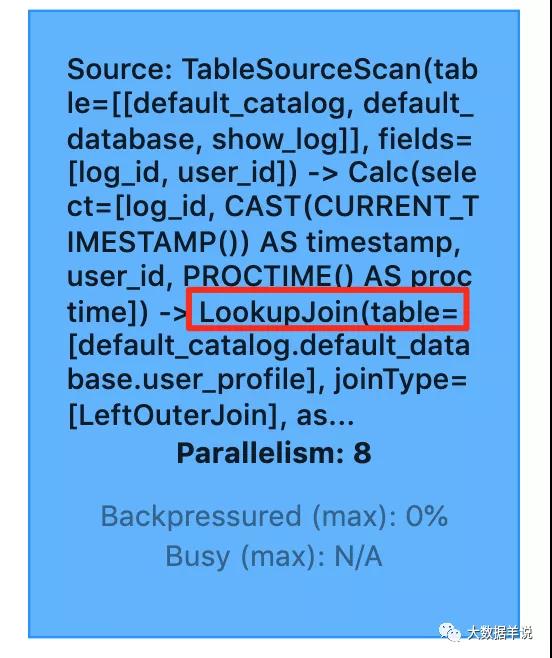
flink web ui
但是!!!但是!!!但是!!!
flink 官方并沒有提供 redis 的維表 connector 實現。
沒錯,博主自己實現了一套。關于 redis 維表的 connector 實現,直接參考下面的文章。都是可以從 github 上找到源碼拿來用的!
flink sql 知其所以然(二)| 自定義 redis 數據維表(附源碼)
4.3.關于維表使用的一些注意事項
同一條數據關聯到的維度數據可能不同:實時數倉中常用的實時維表都是在不斷的變化中的,當前流表數據關聯完維表數據后,如果同一個 key 的維表的數據發生了變化,已關聯到的維表的結果數據不會再同步更新。舉個例子,維表中 user_id 為 1 的數據在 08:00 時 age 由 12-18 變為了 18-24,那么當我們的任務在 08:01 failover 之后從 07:59 開始回溯數據時,原本應該關聯到 12-18 的數據會關聯到 18-24 的 age 數據。這是有可能會影響數據質量的。所以小伙伴萌在評估你們的實時任務時要考慮到這一點。
會發生實時的新建及更新的維表博主建議小伙伴萌應該建立起數據延遲的監控機制,防止出現流表數據先于維表數據到達,導致關聯不到維表數據
4.4.再說說維表常見的性能問題及優化思路
所有的維表性能問題都可以總結為:高 qps 下訪問維表存儲引擎產生的任務背壓,數據產出延遲問題。
舉個例子:
- 在沒有使用維表的情況下:一條數據從輸入 flink 任務到輸出 flink 任務的時延假如為 0.1 ms,那么并行度為 1 的任務的吞吐可以達到 1 query / 0.1 ms = 1w qps。
- 在使用維表之后:每條數據訪問維表的外部存儲的時長為 2 ms,那么一條數據從輸入 flink 任務到輸出 flink 任務的時延就會變成 2.1 ms,那么同樣并行度為 1 的任務的吞吐只能達到 1 query / 2.1 ms = 476 qps。兩者的吞吐量相差 21 倍。
這就是為什么維表 join 的算子會產生背壓,任務產出會延遲。
那么當然,解決方案也是有很多的。拋開 flink sql 想一下,如果我們使用 DataStream api,甚至是在做一個后端應用,需要訪問外部存儲時,常用的優化方案有哪些?這里列舉一下:
按照 redis 維表的 key 分桶 + local cache:通過按照 key 分桶的方式,讓大多數據的維表關聯的數據訪問走之前訪問過得 local cache 即可。這樣就可以把訪問外部存儲 2.1 ms 處理一個 query 變為訪問內存的 0.1 ms 處理一個 query 的時長。
異步訪問外存:DataStream api 有異步算子,可以利用線程池去同時多次請求維表外部存儲。這樣就可以把 2.1 ms 處理 1 個 query 變為 2.1 ms 處理 10 個 query。吞吐可變優化到 10 / 2.1 ms = 4761 qps。
批量訪問外存:除了異步訪問之外,我們還可以批量訪問外部存儲。舉一個例子:在訪問 redis 維表的 1 query 占用 2.1 ms 時長中,其中可能有 2 ms 都是在網絡請求上面的耗時 ,其中只有 0.1 ms 是 redis server 處理請求的時長。那么我們就可以使用 redis 提供的 pipeline 能力,在客戶端(也就是 flink 任務 lookup join 算子中),攢一批數據,使用 pipeline 去同時訪問 redis sever。這樣就可以把 2.1 ms 處理 1 個 query 變為 7ms(2ms + 50 * 0.1ms) 處理 50 個 query。吞吐可變為 50 query / 7 ms = 7143 qps。博主這里測試了下使用 redis pipeline 和未使用的時長消耗對比。如下圖所示。

redis pipeline
博主認為上述優化效果中,最好用的是 1 + 3,2 相比 3 還是一條一條發請求,性能會差一些。
既然 DataStream 可以這樣做,flink sql 必須必的也可以借鑒上面的這些優化方案。具體怎么操作呢?看下文騷操作
4.5.lookup join 的具體性能優化方案
按照 redis 維表的 key 分桶 + local cache:sql 中如果要做分桶,得先做 group by,但是如果做了 group by 的聚合,就只能在 udaf 中做訪問 redis 處理,并且 udaf 產出的結果只能是一條,所以這種實現起來非常復雜。我們選擇不做 keyby 分桶。但是我們可以直接使用 local cache 去做本地緩存,雖然【直接緩存】的效果比【先按照 key 分桶再做緩存】的效果差,但是也能一定程度上減少訪問 redis 壓力。在博主實現的 redis connector 中,內置了 local cache 的實現,小伙伴萌可以參考下面這部篇文章進行配置。
異步訪問外存:目前博主實現的 redis connector 不支持異步訪問,但是官方實現的 hbase connector 支持這個功能,參考下面鏈接文章的,點開之后搜索 lookup.async。https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/hbase/
批量訪問外存:這玩意官方必然沒有實現啊,但是,但是,但是,經過博主周末兩天的瘋狂 debug,改了改源碼,搞定了基于 redis 的批量訪問外存優化的功能。
4.6.基于 redis connector 的批量訪問機制優化
先描述一下大概是個什么東西,具體怎么用。
你只需要在 StreamTableEnvironment 中的 table config 配置上 is.dim.batch.mode 為 true,sql 不用做任何改動的情況下,flink lookup join 算子會自動優化,優化效果如下:
lookup join 算子的每個 task 上,每攢夠 30 條數據 or 每隔五秒(處理時間) 去觸發一次批量訪問 redis 的請求,使用的是 jedis client 的 pipeline 功能訪問 redis server。實測性能有很大提升。
關于這個批量訪問機制的優化介紹和使用方式介紹,小伙伴們先別急,下篇文章會詳細介紹到。
5.總結與展望
源碼公眾號后臺回復1.13.2 sql lookup join獲取。
本文主要介紹了 flink sql lookup join 的使用方式,并介紹了一些經常出現的性能問題以及優化思路,總結如下:
背景及應用場景介紹:博主期望你能了解到,flink sql 提供了輕松訪問外部存儲的 lookup join(與上節不同,上節說的是流與流的 join)。lookup join 可以簡單理解為使用 flatmap 訪問外部存儲數據然后將維度字段拼接到當前這條數據上面
來一個實戰案例:博主以曝光用戶日志流關聯用戶畫像(年齡、性別)維表為例介紹 lookup join 應該達到的關聯的預期效果。
flink sql lookup join 的解決方案以及原理的介紹:主要介紹 lookup join 的在上述實戰案例的 sql 寫法,博主期望你能了解到,lookup join 是基于處理時間的,并且 lookup join 經常會由于訪問外部存儲的 qps 過高而導致背壓,產出延遲等性能問題。我們可以借鑒在 DataStream api 中的維表 join 優化思路在 flink sql 使用 local cache,異步訪問維表,批量訪問維表三種方式去解決性能問題。
總結及展望:官方并沒有提供 批量訪問維表 的能力,因此博主自己實現了一套,具體使用方式和原理實現敬請期待下篇文章。























