如何實現多人協作的在線文檔
由于業務需要,在工作中接觸到了在線文檔、在線Excel。但是在調研階段發現國內相關文章比較匱乏,所以結合工作實踐和自己的一些思考,寫幾篇文章剖析實現在線文檔和在線Excel的一些技術方案。為了避免涉及到公司隱私,所以文章中一些數據結構的設計和非關鍵場景都寫的比較簡略。我們主要從需求分析、方案設計、技術選型等幾個方面介紹如何實現多人協作的在線文檔。
需求分析
我們借鑒領域驅動模型的思路進行需求分析。需求中包含「人」和「文檔」兩個實體。「人」的主要屬性有:用戶ID、用戶名。「文檔」的主要屬性有:文檔ID、文檔內容、創建者、創建時間。人和文檔的關系非常簡單:一個人可以有多個文檔,一個文檔只歸屬某一個人,屬于一對多的關系。
因為文檔內容不能被隨便閱讀和修改,所以還要有權限管理,「權限」是一種值對象。權限的值有:閱讀、編輯。人對文檔可以有閱讀權限或編輯權限。
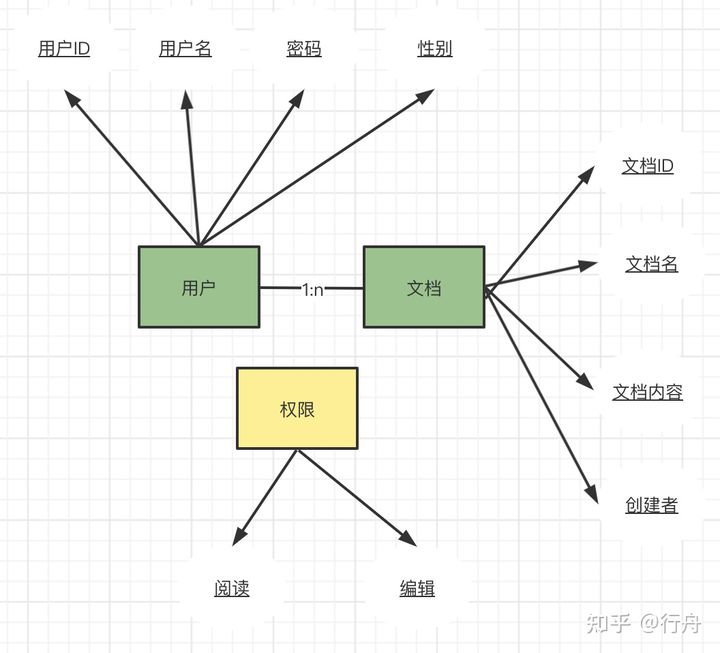
還有一個最關鍵的問題就是「協作」。協作是多個「人」,對一篇文檔同時操作。協作的過程中需要把多個人編輯的內容,經過合并轉換為最終保存的文檔內容。協作的過程中需要讓文檔編輯人員看到當前「一起協作的對象」和協作對象「實時編輯的內容」。
為了實現以上功能我們把系統拆分成五大模塊:人員管理、文檔管理、權限管理、協作和前端文檔編輯器。
方案設計
人員管理
因為人員管理不是本文的重點,所以我們只做一個簡要的設計,主要是為了輔助說明后面的設計。
表結構主要字段有:
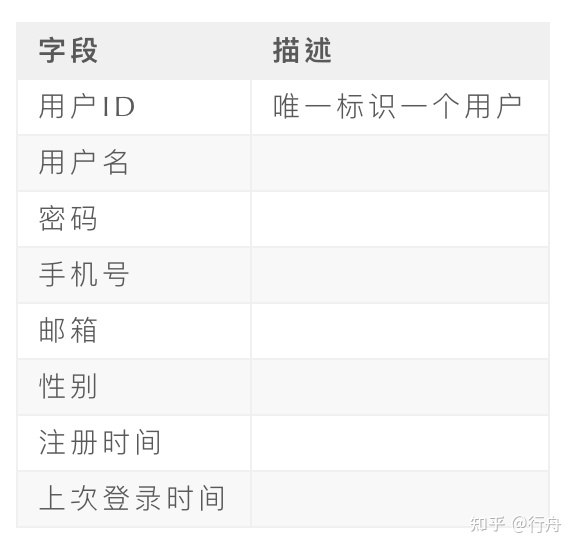
下面介紹下該模塊的主要邏輯。
用戶注冊
- 前端把用戶填寫的用戶名、密碼、手機號等信息加密后發送給服務端。
- 服務端拿到數據,再和生成的唯一用戶ID一起,存入表中。
用戶登錄
- 前端要求用戶輸入用戶名+密碼并發送給服務端,服務端校驗用戶名和密碼的正確性。
- 校驗通過后,根據「用戶名+密碼+密鑰+時間戳」生成有時效性的Token,返回給客戶端。
- 登錄之后前端所有請求都帶著Token信息。服務端根據Token獲取當前登錄用戶信息并判斷請求是否合法。
文檔管理
文檔的表結構設計:
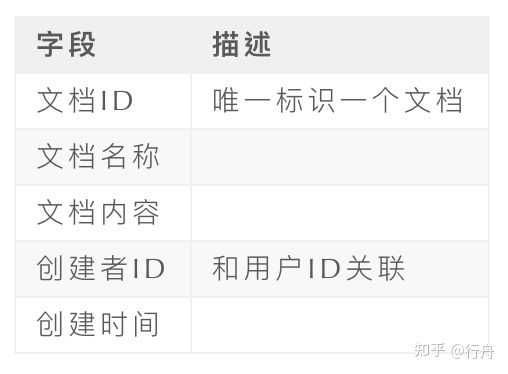
下面介紹下該模塊的主要邏輯。
創建文檔
- 前端發送文檔名稱、文檔內容給服務端
- 服務端生成唯一的文檔ID,從Token中獲取到用戶ID,獲取服務器時間然后把數據一起存入數據庫中
- 服務端返回文檔ID給前端
修改文檔
這里的修改是指修改文檔的內容。我們為了及時保存用戶編輯的內容,需要在用戶編輯過程中實時把數據傳遞給服務端。如果每次都發送全部文檔內容給服務端,雖然服務端的處理邏輯會比較簡單,但是每次請求都有很多冗余數據,浪費大量的帶寬。所以我們最好只發送變化的內容給服務端,讓服務端根據當前文檔內容和變化內容合并生成最新的文檔內容。
如何發送變化的內容呢?我們可以把用戶對文檔內容的操作分成三類:「新增、修改、刪除」。新增就是給文檔添加內容,修改就是修改文檔的某一段內容,刪除就是刪除了文檔的某一段內容。對這三類操作我們可以使用Json形式來表示:
- {
- op:"", // 操作 add:新增,update:修改, delete:刪除
- start:"", // 開始位置下標
- end: "", // 結束位置下標
- text:"", // 修改內容
- }
這樣修改文檔的流程就是
- 前端生成修改數據發送給服務端
- 服務端從數據庫中獲取文檔內容,然后根據用戶的行為合并操作,最后保存到數據庫中。
用戶在編輯一篇文章時,往往需要很多次數據傳輸。Json的數據格式雖然能很好的表達語意,但是每次傳輸也需要發送較多的字節,浪費帶寬;而且Json的序列化和反序列化過程也相對低效。我們可以采用Google的Protobuf協議來代替,它是基于二進制的傳輸協議,在傳輸內容大小和解析速度上都強于Json。
- message Doc {
- enum Op{
- add:0;
- update:1;
- delete:2;
- }
- required Op op = 0;
- required int32 start = 1;
- required int32 end = 5;
- string text = "修改內容"
- }
這里協議比較簡單,自己按照規則拼接字符串也是可以的。考慮到后續功能的可擴展性,還是建議采用Protobuf協議。
修改文檔的流程還有順序問題,我們假設用戶的操作是這樣的:
- 用戶先刪除了5個字“12345”
- 添加了5個字“一二三四五”
- 又修改了其中的前兩個字是“你好”
正常順序下最后的結果是:「你好三四五」。但是如果服務端的執行順序變成了3、1、2,那最后的結果變成了:「一二三四五」。這顯然是不符合預期的。所以我們要保證服務端順序處理前端發過來的請求。
保證順序執行有幾個方案:
- 前端請求由異步變成同步
- 前端每次請求都生成連續遞增的ID,服務端判斷如果遞增ID不連續了,就短暫的等待
- 把對同一個文檔的操作代理到同一個服務器,服務端單進程接收請求,并把數據存入有序隊列。隊列的消費端正常消費就可以了。
方案一在請求多的時候,處理效率太低會影響用戶體驗,可以直接排除掉。方案二主要依賴客戶端生成遞增ID,是比較不錯的方案。方案三依賴單進程和有序隊列保證順序。雖然單進程在并發量高的情況下很難抗壓,但是如果根據文檔ID去做負載均衡也可以比較好的控制流量,畢竟對一個文檔的修改QPS也高不到哪去。
當然也可以把方案二和方案三結合使用。
查看文檔
- 前端發送要查看的文檔ID給服務端
- 服務端根據文檔ID返回文檔內容
刪除文檔
- 前端發送要刪除的文檔ID給服務端
- 服務端根據文檔ID刪除對應文檔
權限管理
當前需求的權限場景特別適合「ABAC」的權限模型。
用戶屬性:只要是正常登錄用戶即可
環境屬性:普通的文檔內容
操作屬性:文檔的讀和寫
對象屬性:文檔
所以,我們存儲權限信息的表結構主要字段有:
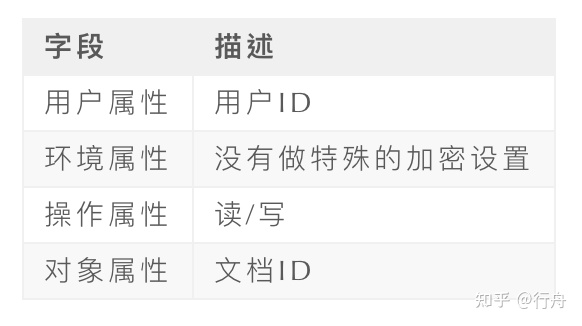
下面介紹下該模塊的主要邏輯。
開通權限
- 前端發送文檔ID和權限類型(讀/寫)給服務端
- 服務端根據文檔ID和Token中的用戶ID,在權限表中添加記錄,并返回成功
刪除權限
- 前端發送文檔ID和權限類型(讀/寫)給服務端
- 服務端根據文檔ID和Token中的用戶ID,在權限表中刪除記錄,并返回成功
校驗權限
我們可以實現一個中間鍵,當用戶請求某文檔內容時,判斷其是否為創建者。如果不是再從權限表中查詢用戶是否有權限查看或者編輯權限。修改文檔內容時也是同樣的邏輯,就不再贅述了。
協作
合并沖突
當多個人同時修改一個文檔時,處理內容沖突的幾種方式:
- 文檔加鎖:當有人修改文檔時,對整個文檔加寫鎖,別人都只能看不可編輯。雖然實現簡單,不過協作的體驗會特別差。
- diff+patch的合并算法:diff+patch是常用的文檔內容比較和合并算法,Linux本身就提供了diff和patch命令支持文件的比較和合并。git也使用了diff+patch方法來合并文件,當無法解決沖突時,會把沖突拋給用戶手動合并。
- OT算法:相比diff+patch來講OT算法往往能帶來更好的合并結果。不過OT算法的實現也更復雜一些。目前Google文檔、騰訊文檔、石墨文檔等都是采用了OT算法。我們后面單獨寫文章來聊一聊diff+patch和OT算法。
協作通知
為了更好的協作,文檔編輯者需要看到同時編輯文檔的人,還需要看到別人修改的內容,來減少沖突,達到協作的目的。
大家打開文檔編輯頁面的時間是不同步的,為了讓大家「互相看到」,而且互相看到對方「修改的內容」,就需要服務端主動給客戶端推送消息。此場景下采用長鏈接的方案是比較合適的。
前文也提到過,文檔修改頻繁的時候,發送數據的頻次會很高,如果是HTTP請求會導致每次請求都攜帶頭信息,建立連接等開銷,所以修改文檔內容的數據上報也可以采用長鏈接。同時,服務端維護一個「協作列表」來存放所有正在被編輯的文檔和每個文檔的在線用戶,可以類比為一個聊天室。
文檔修改者加入
- 前端打開一個文檔時,發送請求給服務端,服務端檢查協作列表中是否有當前文檔。
- 如果有則把當前用戶加入此文檔修改者列表;如果沒有就把當前文檔加入協作列表,同時把當前用戶ID寫入其中。
- 服務端通過長鏈接給文檔列表中的所有其他用戶推送消息,告知大家有用戶加入協作。
文檔修改者退出邏輯和加入基本相同就不再贅述了。
「修改內容」
- 前端把修改數據發送給服務端
- 服務端暫存多個用戶的操作,并根據OT算法把用戶操作合并,最后和數據庫存儲的文檔內容合并
- 把合并完的文檔內容保存到數據庫中
- 服務端根據文檔ID,讀取協作列表中的用戶,給所有用戶發送合并結果
- 客戶端把合并結果與本地文檔內容合并
文檔編輯器
「編輯功能」
文檔編輯器需要支持,文檔內容編輯、文字樣式調整、插入圖片、插入鏈接等一系列功能。 實現內容可編輯的方案有textarea標簽和contenteditable屬性可以選擇。但是textarea標簽對其他需求的實現很難支持,而且不方便控制。所以我們選用contenteditable=true來實現文檔內容的編輯。
「上報功能」
文檔修改時,內容的上報,需要文檔編輯器處理好。不能用戶每輸入一個字符就上報一次,這樣頻繁的發送數據會給服務端帶來很大壓力,也是沒有必要的。所以客戶端的上報需要做防抖處理。上報的過程中有可能會因為網絡閃斷等原因導致上報失敗,此時需要重試。
服務可能因為長時間的網絡中斷或者服務器異常導致數據上報失敗。此時前端可以先把用戶修改存儲在瀏覽器本地的LocalStorage中,不過需要注意瀏覽器本地緩存通常有5M的大小限制。本地存儲除了在網絡異常時發揮作用,在實現Ctrl+Z操作時,也可以起到記錄之前操作的作用。
「長鏈接」
需要有一個單獨的模塊管理長鏈接,統一處理上報的接口和服務端下發的數據,做好數據的封裝和解析;并及時的反饋給用戶連接成功、數據保存成功、連接異常等信息。
「大文檔的加載」
對于大文檔的加載,我們需要做異步處理。根據滾動條滾動的位置,在服務端異步的獲取更多數據。
「其他功能」
前端編輯器的其他模塊我們可以根據其功能范圍拆分:比如控制文字大小、顏色的功能模塊;控制文字對齊方式的模塊;控制插入內容的模塊;支持Ctrl+C、Ctrl+V、Ctrl+Z的模塊等等。拆分好之后根據功能實現就可以了,這里就不一一分析了。
技術選型
「存儲」
存儲方面,當前場景使用關系型數據庫比較合適。我們可以根據文檔和用戶的數量級選擇合適的數據庫。通常千萬級別的數據量選擇MySQL就可以了,如果數據更多的話我們可以選擇TIDB或者MySQL分庫分表的方案。
當然采用MongoDB和PG也都可以滿足需求,我們可以結合公司的DBA運維能力自行選擇。
補充一下,如果考慮文檔內容的搜索,只選擇一種存儲結構是不夠的。需要單獨為文檔建立索引,可以選擇使用ES集群為文檔創建全文索引。而且索引的創建和MySQL的增刪改比起來是比較耗時的操作,所以創建索引往往放在異步流程中。而且用戶創建一個文檔也很少立馬就對它搜索。
「長鏈接」
當前常用的長鏈接方案主要有“HTTP/2 + SSE”和WebSocket兩種,WebSocket更成熟一些,優先選擇。
「消息隊列」
建議采用RocketMQ,因為
- RocketMQ支持同步/異步刷盤,支持同步/異步寫副本,消息的可靠性更有保障。
- RocketMQ支持順序消息。
當然寫入性能方面要比Kafka弱一些。但是在線文檔的場景里,消息的可靠性和順序更加重要。
架構設計
基于上面的分析,我們設計的部署架構圖如下
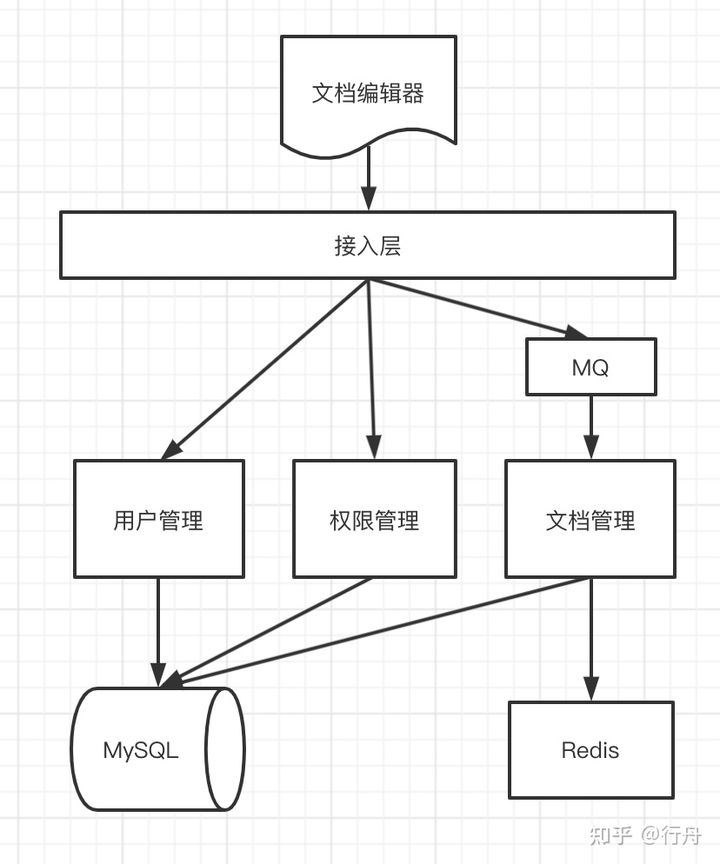
其中,接入層負責用戶的鑒權和長鏈接保持;其他各模塊負責各自的功能。文檔修改的隊列我們采用MQ發送,文檔管理模塊消費。Redis我們用來存放多人協作時的文檔和用戶對應關系。當然數據量不大時MQ也可以使用Redis臨時代替。
總結
以上就是我對多人協作在線文檔的分析和設計方案,其中包含了前后端交互流程、文檔的存儲和服務的部署方案。為了突出主要問題和邏輯,文中很多設計和技術點都是點到為止,給大家造成困擾的地方大家可以自行搜索下關鍵字或者留言交流。