自從ChatGPT公開發布以來,人們幾乎沒有一天不討論LLM(大型語言模型)、RAG(檢索增強生成:Retrieval Augmented Generation)和向量數據庫的新內容。技術世界充斥著LLM的可能性,LLM被視為將改變我們生活的最新技術:對一些人來說是最好的,對另一些人來說則是最壞的。除此之外,檢索增強生成(RAG)已經成為一種動態解決方案,以適應不斷變化的知識環境。但是,在幕后還有一個至關重要的角色:向量索引和數據庫。
雖然LLM、RAG和向量數據庫已經被廣泛并深入討論過,但是支持這些創新的(向量)索引卻鮮為人知。在本文中,我們將揭開向量索引概念的神秘面紗,以幫助您了解索引如何使得在大量集合中查找信息變得輕而易舉。
1、什么是索引?
我們都遇到過這樣的情況:你和你的朋友要在她家見面;但是,她事先提供給你的唯一信息是“我住在大都會區”。當您到達上述大都會區時,卻遇到如下圖所示的尷尬:

Yim在Unsplash上的照片
好吧,如果沒有任何幫助,找到她的位置需要一段時間!不過,如果入口處有一張導航地圖就好了……
這正是索引的意義所在:如何快速找到人員(或數據)所在的位置。
提示:黃頁(https://www.yellowpages.com/)就是一個索引,它可以幫助你根據人們的名字找到他們的家。
索引是一種數據結構,用于提高數據檢索操作對數據的速度。換句話說,這就是你如何組織信息,以便快速找到你想要的東西。
人們通常使用鍵對數據進行索引。數據的存儲順序基于鍵,而且可以使用多個鍵進行索引。例如,在前面的黃頁網站中,第一個鍵是姓氏,第二個鍵是名字。
索引不一定存儲全部數據。它只關注用于在整個數據中快速定位和訪問特定數據片段的關鍵部分。
書籍后面的索引就是一個很好的例子:它顯示了在哪里可以找到使用相應單詞的頁面;因此,它將每個單詞映射到頁碼,而不是句子本身。
索引“隱藏”于搜索引擎和數據庫背后:它們在提高數據檢索操作的效率和速度方面發揮著至關重要的作用。
因此,如何組織數據的選擇就顯得至關重要,這要取決于上下文。
例如,在黃頁的例子中,如果索引是按電話號碼組織的,但是你只知道他們的名字,那么找到他們的地址將非常困難!
信息就在那里;你最終會找到它,但所需的時間會阻止你進行這樣的嘗試。另一方面,使用黃頁,只需瀏覽一眼頁面,就可以準確地知道是需要向后看還是向前看!字典順序允許您進行大致的對數搜索。這就是為什么索引的選擇是至關重要的。
一般來說,索引有一個非常精確的目的:它可以被設計為執行數據的快速插入或檢索,或者執行更奇特的查詢,如范圍查詢(“檢索今年5月1日至8月15日之間的所有數據”)。要優化的操作的選擇將決定索引的外觀。
在線事務處理(OLTP)和在線分析處理(OLAP)數據庫之間的主要區別在于它們想要優化的操作的選擇:OLTP側重于行上的操作(如更新條目),而另一個側重于列上的操作。這兩種類型的數據庫不會使用相同的索引,因為它們不針對相同的操作。
(1)索引和數據結構之間的區別是什么?
數據結構(https://w.wiki/7ma9)是一種在計算機中組織和存儲數據的方式,以便能夠有效地訪問和操作數據。這樣解釋,有時很難看出索引和數據結構之間的區別,那么到底它們之間的區別是什么呢?
簡言之,索引主要用于插入、搜索、排序或篩選數據,但是數據結構則更為通用。索引是使用數據結構構建的,但通常不存儲數據本身。
如果你考慮一個電影數據庫,那么每當索引更新時,你不想在大文件中移動:你存儲的是指向文件的指針,而不是文件本身。指針可以看作磁盤上文件的地址。
現在,您對索引應該有了大致的了解,接下來讓我們關注數字示例。以下是一些常見的(數字)索引:
- 反向索引
- 哈希索引
- B-樹
- 區分位置的哈希(LSH)
為了更好地理解索引是如何工作的,讓我們研究一下最基本的索引之一:反向索引(Inverted index)。
(2)反向索引
反向索引是搜索引擎中使用的標準索引。
它旨在快速找到信息的位置:它旨在優化檢索時間。
簡而言之,反向索引將內容映射到它們的位置,有點像書的索引。
它通常用于將特性映射到具有該特性的數據。
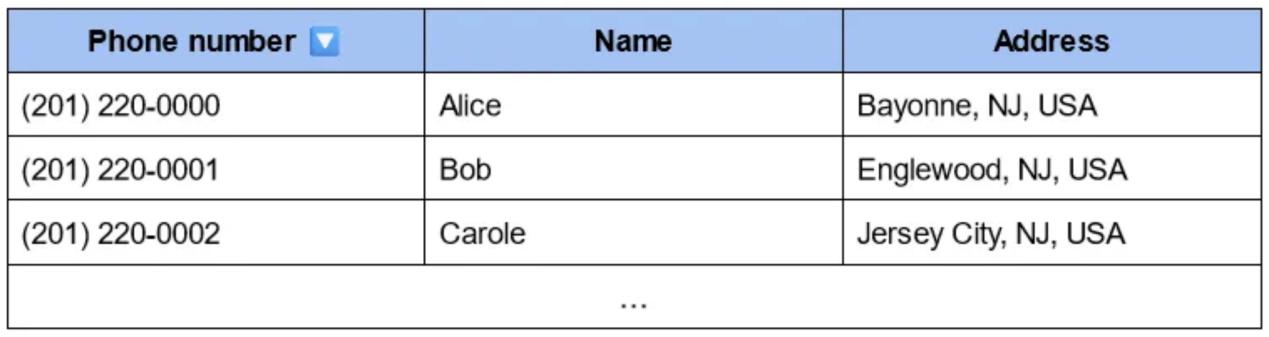
例如,假設你想知道誰住在同一棟樓里。
首先,你應該有一個表格,每個名字都對應一棟樓(這個表格本可以幫助你找到愛麗絲):
每當有人到達或離開該地區時,此表都會更新。
如果你想在這個表中找到住在B樓的人,你必須遍歷整個表。
雖然這在技術上是可能的,但它不會縮放,因為計算時間會隨著表的大小線性增加。
想想該地區的公寓數量:如果你想通過逐一查看所有檔案來找到B棟的所有住戶,這需要一段時間!
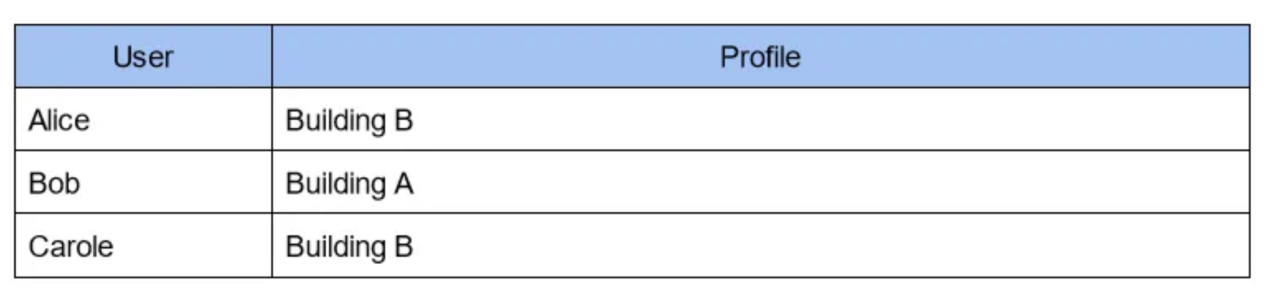
另一種解決方案是使用反向索引:您維護一個表格,其中的建筑物被用作密鑰,并與居住在其中的人相連:

此表與上一個表同時維護:添加或刪除新人的成本比以前略高,但檢索時間已縮短到幾乎為零!
要找到住在B棟樓的人,你只需訪問此表的行“B棟樓(Building B)”即可獲得結果!
還有一個典型的例子:反向電話查找也是電話號碼的反向索引!
在實踐中,反向索引有點復雜,因為它們處理的數據比配對(用戶、興趣)更復雜。索引通常存儲為哈希表(https://w.wiki/7mdQ)中。
盡管反向索引相對簡單,但它們是搜索引擎中最常見的索引之一。
(3)索引和數據庫
數據庫建立在索引之上。索引通過存儲指向數據庫數據的指針或引用來增強數據庫中的數據檢索。它不存儲實際數據,而是作為一種快速訪問數據的手段,顯著提高了查詢性能。
數據庫不僅僅是索引,因為它是一個全面的數據管理系統。它存儲、組織和管理實際數據,加強數據完整性,處理事務,并提供索引之外的一系列功能,使其成為數據存儲和操作的中心樞紐。雖然索引加快了數據庫中的數據檢索,但數據庫是數據存儲、管理和檢索的完整生態系統。

總之,索引就像數據庫中的路標,為您查找的數據指明方向。相比之下,數據庫是實際數據所在的存儲庫,并配備了各種工具和功能來管理和操作這些數據。
根據您的使用情況,您可能不需要整個數據庫,而只需要索引,因為全面管理數據的成本可能非常高昂。
2、向量索引和向量數據庫
(1)什么是向量索引?
簡而言之,向量索引是一個索引,其中鍵是向量。
在我們的反向索引示例中,鍵是單詞(愛好和名稱)。在向量索引中,我們操縱向量:固定大小的數字序列。

兩個大小為4的向量
我知道,我能聽到你說,“我數學不好,我不想用向量”。
別擔心,你不需要擅長數學就能理解向量索引。
您所需要知道的是,使用向量使您能夠依賴強大且優化的操作。
你可能會問自己的第一個問題是,“你的向量有什么有趣的?”
比方說,你終于在愛麗絲家找到了她,現在你想找點吃的。你可能想找最近的餐館。于是,你查找一份餐館列表,最后得到一張餐館、特色菜和地址的表格。讓我們來看看您可以找到的信息:
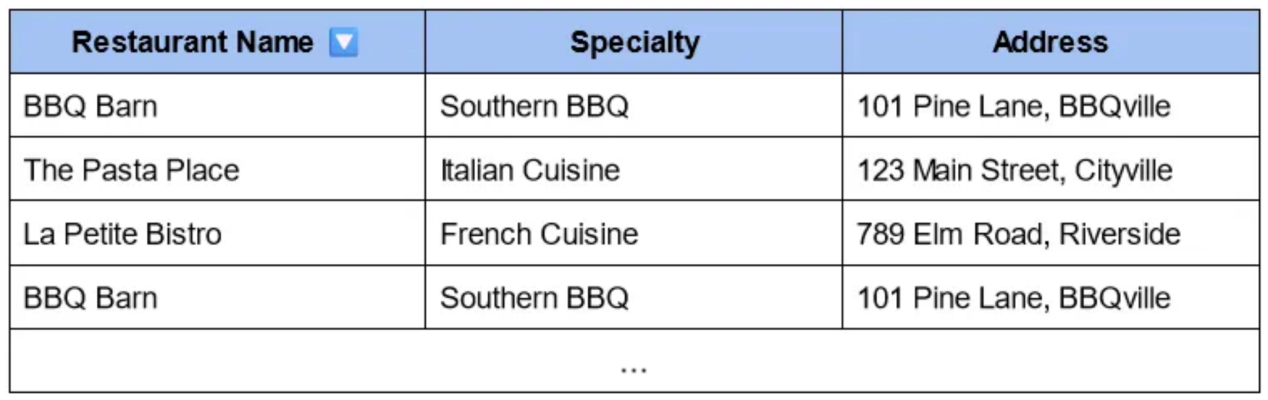
這看起來沒有幫助,對吧?你唯一的選擇是瀏覽列表,逐個讀取地址,然后手動評估它離你有多近。我們可以嘗試自動對最近的地方進行排名,但基于原始地址計算距離很困難(兩條街道可能在附近,但名稱不同)。
想象一下,現在你有一張表格,上面有GPS位置,代表每個餐廳的確切緯度和經度:
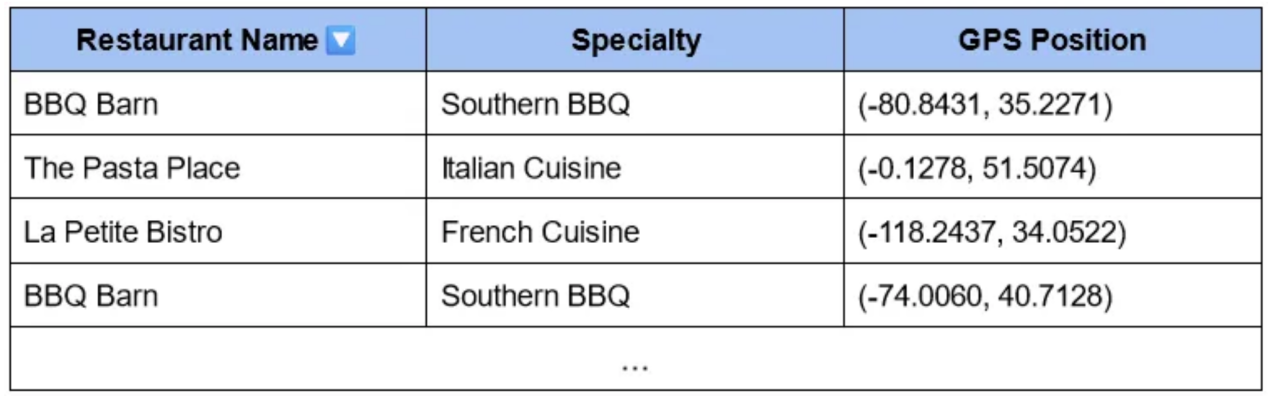
每個位置都是大小為2的向量。有了這些向量,你就可以通過簡單快速的數學運算輕松計算到自己位置的距離。然后你可以快速檢索到最近的餐館,換句話說,距離你最小的餐館!
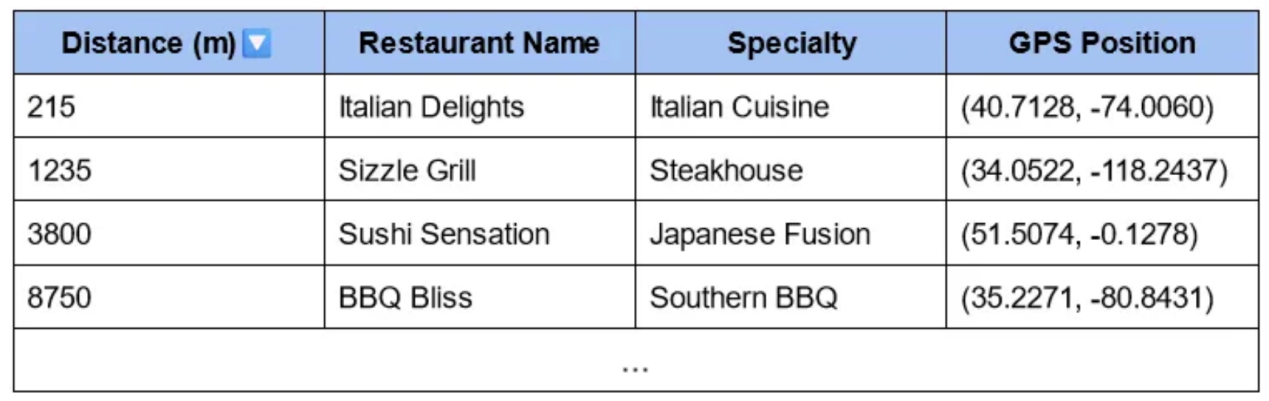
現在,你可以很容易地找到離你最近的餐館了!
有趣的一點是,通過直接根據向量(本例中的GPS位置)對表進行索引,我們可以優化索引,從而快速找到距離最低的條目。
向量索引是專門的索引,旨在有效地檢索與給定向量最接近或最相似的向量。這些索引依賴于優化的數學運算來有效地識別最相似的向量。
在我們的例子中,使用的距離是經典距離,但是針對所有現有距離或相似性都使用了索引,例如余弦相似性度量。
位置敏感哈希(LSH)是用于查找數據集中k個最相似數據點的最廣泛使用的索引之一,它適用于不同的距離或相似性。
“這很好,但我沒有在數據庫中使用向量”。
這就是令人興奮的部分:你可以將任何東西轉化為向量。
簡單地采用二進制表示是低效的,因為它可能包含噪聲,所以找到一種保留數據特性的表示是至關重要的。
將不同的信息表示為向量以使用向量索引已成為提高系統效率的標準方法。向量化已經成為一門藝術。
例如,如果你有一個圖像數據集,并且你想要一個數據庫,在那里你可以找到與給定圖像最相似的圖像,那么,你可以使用圖像的SIFT描述符。
(2)向量索引和向量數據庫之間的區別是什么?
向量索引和向量數據庫之間的區別與索引和數據庫之間的差異相同:索引旨在快速找到數據所在的位置,而向量數據庫使用向量索引快速執行檢索查詢,但它們也存儲和維護數據,同時提供額外的操作和屬性。
3、LLM和RAG之間的聯系是什么?
既然您已經了解了向量索引,您可能會想,為什么這么多關于LLM和RAG的討論也討論了向量索引。為了理解原因,讓我們首先快速解釋什么是檢索增強生成(Retrieval Augmented Generation,簡稱RAG)。AG是LLM的一個固有局限性的巧妙解決方案,即其知識有限。
LLM只知道它們接受過訓練的數據。增加它們知識的一種技術是提示工程(Prompt Engineering),將額外的數據集成到查詢提示中:“給定這些數據{data},回答這個問題:{question}”。
雖然這種方法很有效,但它面臨著一個新的挑戰:可擴展性。不僅提示的大小是有限的,而且包含的數據越多,查詢的成本就越高。
為了克服這一點,檢索增強生成通過只插入最相似的數據來限制數據量,這就是向量索引的作用所在!
它的工作原理如下:
所有文檔最初都使用LLM轉換為向量(1)。更具體地說,使用LLM的編碼器部分。
這些向量被用作索引向量索引(2)中的文檔的關鍵字。
在執行查詢時,使用LLM對查詢進行向量化(3)。然后在向量索引中查詢得到的向量,以檢索最相似的文檔(4)。然后,使用提示工程將這些文檔用于回答查詢(5)。
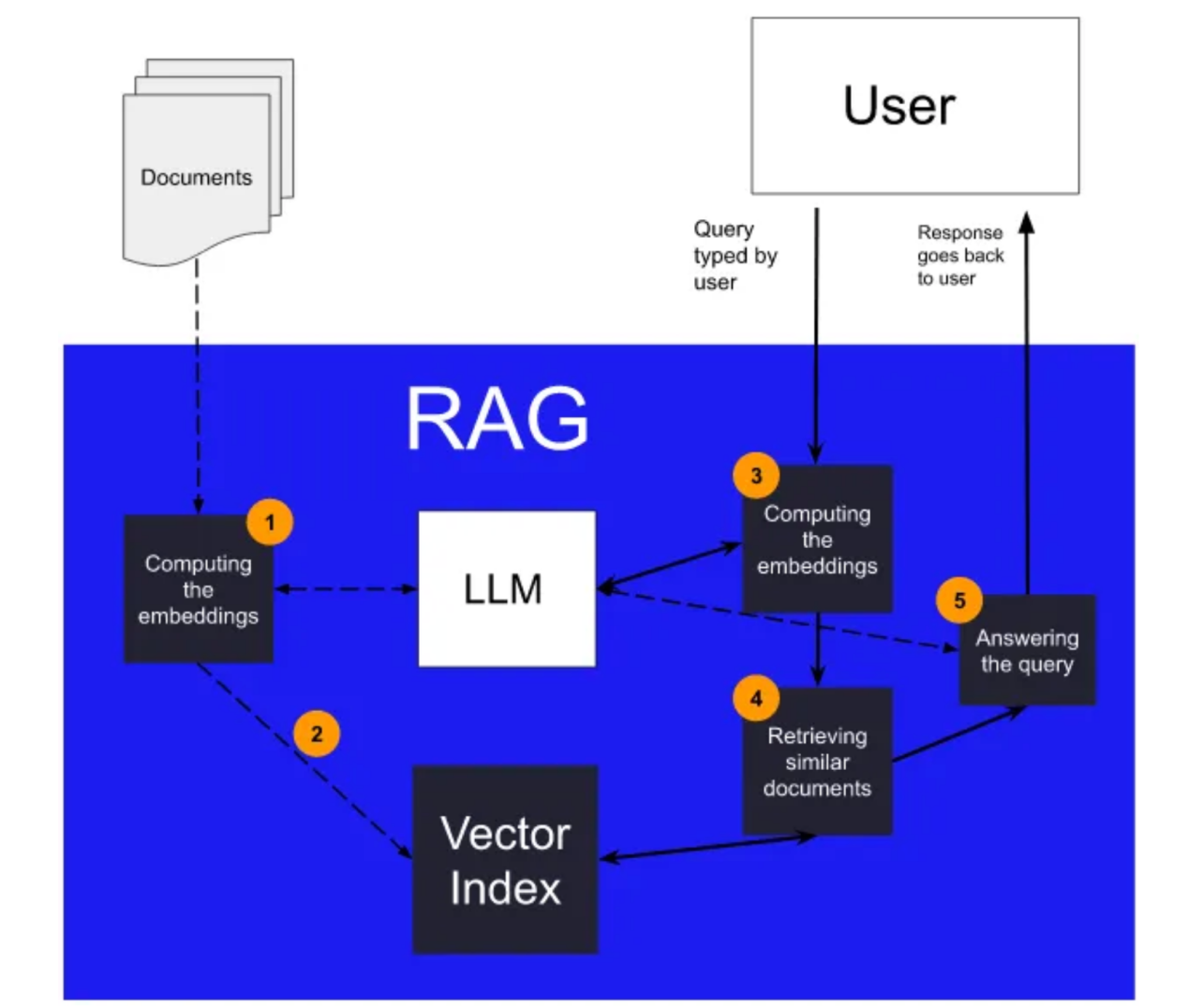
檢索增強生成(RAG)依賴LLM和向量索引
就是這樣!
正如您所看到的,與LLM類似,向量索引在RAG中占據中心位置。
有些人更喜歡使用向量數據庫而不是向量索引。只要您想在多個應用程序中重用相同的數據,就可以了。但是,如果您主要關心的是檢索效率或為每個應用程序定義索引的靈活性,那么部署單個向量索引通常更簡單、更快。
結論
我相信你現在已經具備了參與那些關于LLM和RAG的激情討論的所有背景知識。
索引在數據檢索中起著核心作用。由于數據檢索可能仍然是數據技術的關鍵組成部分,因此了解索引(包括向量索引)是關于什么的至關重要。
如果你想了解更高級的索引技術,我建議你閱讀我關于LSH的文章(https://pathway.com/developers/showcases/lsh/lsh_chapter2)。如果你想學習更實用的東西,并想體驗實時檢索增強生成(RAG)的實際應用,可以考慮探索LLM應用程序(https://github.com/pathwaycom/llm-app),在那里你可以親身體驗這些技術的力量。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:The Hidden World of (Vector) Indexes,作者:Olivier Ruas
鏈接:https://towardsdatascience.com/the-hidden-world-of-vector-indexes-f320a626c3dd。