Python項目實戰(zhàn)篇—常用驗證碼標(biāo)注&識別(CNN神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練/測試/部署)
大家好,我是Snowball。
一、前言
今天給大家分享的實戰(zhàn)項目是常用驗證碼標(biāo)注&識別,前面三篇文章講解了文章的創(chuàng)作靈感、需求分析和實現(xiàn)思路、數(shù)據(jù)采集/預(yù)處理/字符圖切割等知識、高效率數(shù)據(jù)標(biāo)注等知識,分別是以下文章:
- Python項目實戰(zhàn)篇——常用驗證碼標(biāo)注和識別(需求分析和實現(xiàn)思路)
- Python項目實戰(zhàn)篇——常用驗證碼標(biāo)注&識別(數(shù)據(jù)采集/預(yù)處理/字符圖切割)
- Python項目實戰(zhàn)篇——常用驗證碼標(biāo)注&識別(前端+后端實現(xiàn)高效率數(shù)據(jù)標(biāo)注)
這篇文章引入機(jī)器學(xué)習(xí),給大家講解下基于該項目的CNN神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練/測試/部署。
二、背景知識
按照學(xué)習(xí)的好習(xí)慣,先搜索網(wǎng)上資源,再腦洞一下,先思考啥是神經(jīng)網(wǎng)絡(luò),啥是卷積,CNN神經(jīng)網(wǎng)絡(luò)為啥能提取圖片特征,這些問題筆者剛開始全部都遇到過,一臉蒙蔽有沒有。不要急,有問題有時候是好事,說明你知道自己那些不知道,等到自己了解和懂得多了,有些問題就迎刃而解。
筆者剛開始在上面的OpenCV知識學(xué)習(xí)過程中,就嘗試用過傳統(tǒng)的SIFT算法進(jìn)行提取圖片特征可以進(jìn)行圖片相似度匹配,但是效果都比較差,這里面用的是多維向量特征描述。而神經(jīng)網(wǎng)絡(luò)在機(jī)器學(xué)習(xí)的領(lǐng)域為啥這么牛皮,這里面是有數(shù)學(xué)方面的理論支撐,也有現(xiàn)在計算力和數(shù)據(jù)量的支持,而卷積神經(jīng)網(wǎng)絡(luò)專門用來處理圖片特征提取。
剛開始,筆者對這方面的理論知識了解甚少,于是充分利用搜索工具和網(wǎng)上資源,這里分享一下自己學(xué)習(xí)過程中的文章鏈接和視頻鏈接,可以保證讀者看完基本可以加深對神經(jīng)網(wǎng)絡(luò)訓(xùn)練的實戰(zhàn)了解,可上手進(jìn)行項目功能調(diào)整。好的,讓我們開始學(xué)習(xí)(卷)起來,以下就是所有內(nèi)容的鏈接,沒有基礎(chǔ)的朋友可以補(bǔ)一補(bǔ),有基礎(chǔ)的可以直接跳過:
- **數(shù)學(xué)基礎(chǔ)**
- [微積分](https://www.bilibili.com/video/BV1Eb411u7Fw)
- [線性代數(shù)](https://www.bilibili.com/video/BV1aW411Q7x1)
- [概率論](https://www.bilibili.com/video/BV1ot411y7mU)
- [計算機(jī)數(shù)學(xué)基礎(chǔ)](https://www.bilibili.com/video/BV1AB4y1K7kM)
- **OpenCV**
- [OpenCV文章專欄](https://blog.csdn.net/yukinoai/category_9283880.html)
- [OpenCV-Python視頻](https://www.bilibili.com/video/BV1tb4y1C7j7)
- **神經(jīng)網(wǎng)絡(luò)**
- [理解卷積意義](https://www.bilibili.com/video/BV1VV411478E)
- [前饋神經(jīng)網(wǎng)絡(luò)](https://www.bilibili.com/video/BV1Tt411s7fK)
- [神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)理解](https://space.bilibili.com/504715181?spm_id_from=333.788.b_765f7570696e666f.1)
- **Python框架使用**
- [Numpy中文教程](https://www.runoob.com/numpy/numpy-tutorial.html)
- [PyTorch中文教程](https://pytorch.panchuang.net/SecondSection/neural_networks/)
- [PyTorch視頻](https://www.bilibili.com/video/BV1t64y1t7V8)
以上就是筆者這次項目開發(fā)幾個月來搜索的優(yōu)質(zhì)學(xué)習(xí)文章和視頻資源了,有基礎(chǔ)的朋友可以選擇性相關(guān)知識學(xué)習(xí),沒有基礎(chǔ)而時間充裕的可以惡補(bǔ)基礎(chǔ)再動手實戰(zhàn),所謂磨刀不誤砍柴工。想快速動手的小伙伴可以快速學(xué)習(xí),把對應(yīng)項目需要的知識點看明白即可。筆者建議的學(xué)習(xí)方式是確定自己的任務(wù)主線,然后邊學(xué)邊練邊思考,在項目實戰(zhàn)中學(xué)習(xí)總結(jié)是成長最快的方式。
好的,在上面前置知識學(xué)習(xí)了解的差不多后,相信大家都已經(jīng)知道CNN神經(jīng)網(wǎng)絡(luò)的理論知識了,接下來我們動手進(jìn)行CNN模型的實戰(zhàn)訓(xùn)練過程。
在開始,確定模型訓(xùn)練基本過程
- 準(zhǔn)備訓(xùn)練數(shù)據(jù)集、測試數(shù)據(jù)集、預(yù)測數(shù)據(jù)集
- CNN模型編碼
- 模型訓(xùn)練、測試
- 模型預(yù)測、部署
三、CNN神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練
1.準(zhǔn)備數(shù)據(jù)
通過實現(xiàn)思路第1-2步,可以得到相關(guān)圖片驗證碼字符數(shù)據(jù),筆者這里準(zhǔn)備訓(xùn)練集500多張(這里得感謝我妹子花時間幫我在標(biāo)注系統(tǒng)上手動標(biāo)注的初始數(shù)據(jù)集~~),測試集30多張,預(yù)測5張。讀者在python項目拉取下來后,對應(yīng)的文件夾下面已有全部數(shù)據(jù),對應(yīng)路徑如下:
src_img:訓(xùn)練數(shù)據(jù)集
test_src_img:測試數(shù)據(jù)集
usage_src_img:預(yù)測數(shù)據(jù)集
在準(zhǔn)備好圖片驗證碼數(shù)據(jù)后,本次案例需要先進(jìn)行字符切割預(yù)處理(其他常用驗證碼需要讀者自己調(diào)整),對應(yīng)文件image_split,以下是main方法代碼。
- if __name__ == '__main__':
- split_image_dir(SRC_IMG_DIR)
- split_test_image()
執(zhí)行字符切割后,對應(yīng)的訓(xùn)練集字母分類在letter_template目錄下,測試集字母分類在letter_test目錄下。
數(shù)據(jù)集類:net_data.py,下面是主要代碼。
- labels = []
- #2-9
- for i in range(8):
- labels.append(50 + i)
- #A-Z
- for i in range(26):
- labels.append(65 + i)
- class VerCodeDataset(Dataset):
- def __init__(self, image_dir="./letter_template/"):
- l = os.listdir(image_dir)
- self.data = []
- self.label = []
- for d in l:
- fs = os.listdir("{}{}".format(image_dir, d))
- for f in fs:
- fup = "{}{}/{}".format(image_dir, d, f)
- #圖片numpy轉(zhuǎn)tensor
- t = torch.from_numpy(io.imread(fup)).float() / 255
- #將二維值標(biāo)準(zhǔn)化
- norl = transforms.Normalize(t.mean(), t.std())
- self.data.append(norl(t.reshape(1, 40, 40)))
- #添加字符對應(yīng)標(biāo)簽序號
- self.label.append(labels.index(ord(d)))
數(shù)據(jù)集值制作描述可參考該文章鏈接:
- [數(shù)據(jù)集制作參考文章](https://zhuanlan.zhihu.com/p/358671390)
2.CNN模型編碼
本文驗證碼的識別與MNIST的識別相當(dāng)類似,模型這塊采用簡單的前饋神經(jīng)網(wǎng)絡(luò),它接收輸入,讓輸入一個接著一個的通過一些層,最后給出輸出。下面是minst網(wǎng)絡(luò)結(jié)構(gòu)圖:
- [PyTorch 神經(jīng)網(wǎng)絡(luò) - PyTorch官方教程中文版](https://link.zhihu.com/?target=http%3A//pytorch.panchuang.net/SecondSection/neural_networks/)
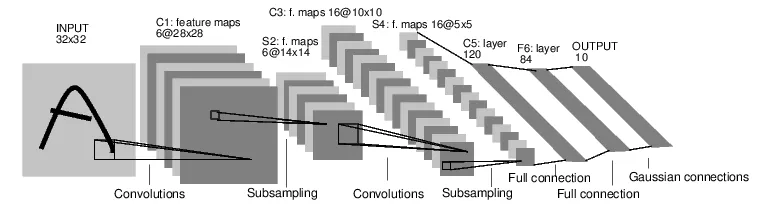
一個典型的神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程包括以下幾點:
1.定義一個包含可訓(xùn)練參數(shù)的神經(jīng)網(wǎng)絡(luò)
2.迭代整個輸入
3.通過神經(jīng)網(wǎng)絡(luò)處理輸入
4.計算損失(loss)
5.反向傳播梯度到神經(jīng)網(wǎng)絡(luò)的參數(shù)
6.更新網(wǎng)絡(luò)的參數(shù),典型的用一個簡單的更新方法:weight = weight - learning_rate *gradient
定義神經(jīng)網(wǎng)絡(luò)(net_train.py):
- class Net(nn.Module):
- def __init__(self, dropout=0.1):
- super(Net, self).__init__()
- self.dropout = nn.Dropout(dropout)
- #第一層,卷積核個數(shù)從6改成10
- self.conv1 = nn.Conv2d(1, 10, 5)
- #第二層,卷積核個數(shù)從10改成25
- self.conv2 = nn.Conv2d(10, 25, 5)
- #全連接層1,40*40的字符圖經(jīng)過2層卷積+2層池化變成7*7
- self.fc1 = nn.Linear(1 * 25 * 7 * 7, 120)
- #全連接層2
- self.fc2 = nn.Linear(120, 84)
- #最后全連接3層為輸出層,本案例驗證碼分類一共34類,[2-9,A-Z],改為34。
- self.fc3 = nn.Linear(84, 34)
- def forward(self, x):
- # 池化出來大小直接除2
- x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
- #防止過擬合
- x = self.dropout(x)
- x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
- x = self.dropout(x)
- x = x.view(-1, self.num_flat_features(x))
- #神經(jīng)元relu激活函數(shù)
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
- def num_flat_features(self, x):
- size = x.size()[1:] # all dimensions except the batch dimension
- num_features = 1
- for s in size:
- num_features *= s
- return num_features
下方代碼中:
- self.fc1 = nn.Linear(1 * 25 * 7 * 7, 120)
全連接層第一個參數(shù)的大小:
[40,40]經(jīng)過[5,5]卷積核->[35,35]
[35,35]經(jīng)過[2,2]池化->[18,18]
[18,18]經(jīng)過[5,5]卷積核->[13,13]
[13,13]經(jīng)過[2,2]池化->[7,7]
上層卷積層一共25個卷積核,因此這里的大小為1(通道數(shù))*25*7*7= 1225,至于后面全連接的84可以隨便改,和下層全連接層保持一致即可。
以上就是模型定義的代碼了,讀者有興趣的也可以自行用其他模型訓(xùn)練。
四、CNN神經(jīng)網(wǎng)絡(luò)模型測試
net_train.py文件提供的訓(xùn)練代碼支持GPU訓(xùn)練,在沒有NVDIA顯卡和安裝pytorch對應(yīng)版本的CUDA庫,默認(rèn)是使用CPU訓(xùn)練,筆者對二種訓(xùn)練方式都進(jìn)行了嘗試,下面是訓(xùn)練對比情況:
- 數(shù)據(jù)量:2286張 40*40 單通道字符圖片
- batch_size: 50
- epoch: 200
- 設(shè)備 時間
- GTX 1070TI 25s
- AMD R7 4750U PRO 4min
總結(jié),數(shù)據(jù)量大,有條件上GTX顯卡就用顯卡訓(xùn)練,訓(xùn)練效率高出CPU數(shù)量級
- [cuda安裝文章鏈接](https://www.cnblogs.com/yang520ming/p/10677110.html)
這里是cuda安裝注意事項:
- 1.更新nvida顯卡驅(qū)動程序,然后看cuda版本
- 2.找pytorch對應(yīng)cuda的版本安裝
train方法代碼如下:
- def train_gpu():
- use_cuda = torch.cuda.is_available()
- if(use_cuda):
- print("use gpu cuda")
- else:
- print("use cpu")
- device = torch.device("cuda:0" if use_cuda else "cpu")
- net = Net()
- net.to(device)
- #隨機(jī)梯度下降
- opt = optim.SGD(net.parameters(), lr=0.01)
- #迭代數(shù)據(jù)200次
- epoch = 200
- #單批次數(shù)據(jù)為50個
- batch_size = 50
- trainloader = data.trainloader(batch_size)
- st = datetime.datetime.now()
- loss = 0
- for e in range(epoch):
- for step, d in enumerate(trainloader):
- data_cuda = d["data"].to(device)
- label_cuda = d["label"].to(device)
- #每次反向傳播后,梯度清零
- opt.zero_grad()
- #前向傳播
- out = net(data_cuda)
- #分類問題選用交叉熵?fù)p失函數(shù)
- lf = nn.CrossEntropyLoss()
- #計算損失
- loss = lf(out, label_cuda)
- #反向傳播修改神經(jīng)元參數(shù)
- loss.backward()
- opt.step()
- #每迭代50次或第一個批次步驟數(shù)據(jù)輸出損失值
- if (e % 50 == 0 or step == 1):
- print("e : {} , step : {}, loss : {}".format(e, step, loss))
- print("loss : {}".format(loss))
- #輸出訓(xùn)練時間
- print("cost time:",datetime.datetime.now() - st)
- #保存模型
- saveModel(net, opt)
描述見上面代碼注釋,對概念理解有問題建議可以再看下這個up主的視頻,筆者覺得講得非常不錯:
- [神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)理解](https://space.bilibili.com/504715181?spm_id_from=333.788.b_765f7570696e666f.1)
下面給出訓(xùn)練、測試過程中的效果圖:
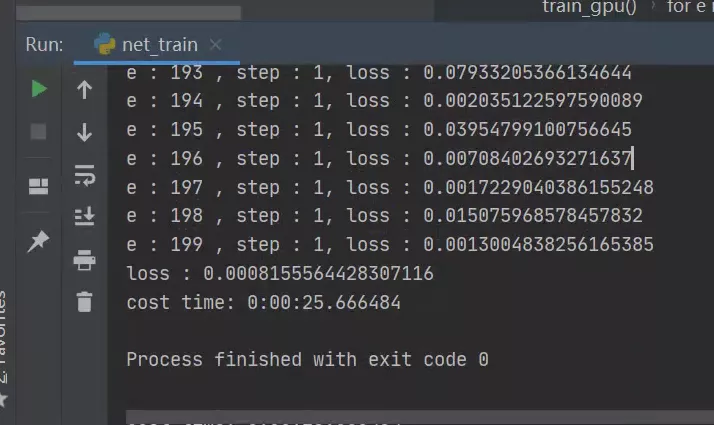
GPU模型-訓(xùn)練集訓(xùn)練:
CPU模型-訓(xùn)練集訓(xùn)練:
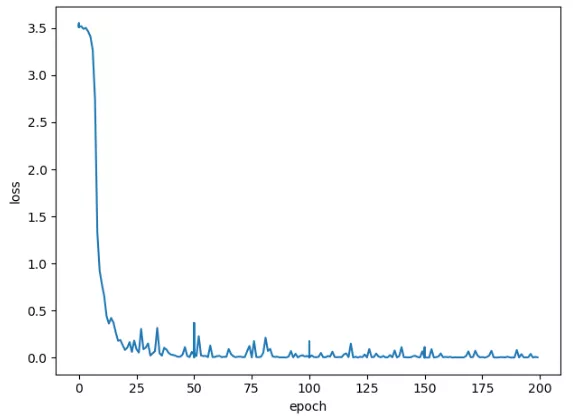
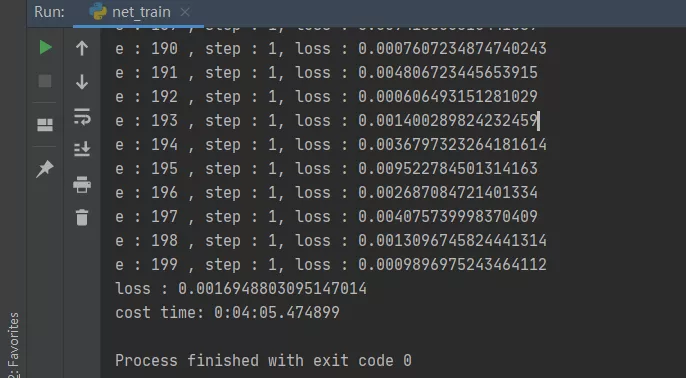
可以看到迭代200次,花費(fèi)4分鐘的訓(xùn)練,模型趨于擬合效果,次數(shù)越往后梯度下降越慢。其實在迭代100次之后就接近穩(wěn)定來回振蕩,損失值減少越慢,最后的損失值為0.0016,擬合效果還不錯,如果增加訓(xùn)練數(shù)據(jù)量、迭代次數(shù)、優(yōu)化部分字符串的切割,可以讓模型效果更好,讀者可自行實踐。
CPU模型-測試集測試:
代碼見net_test.py
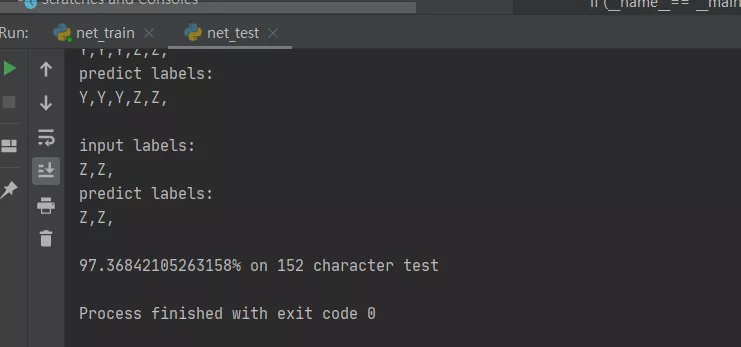
可以看到152個字符,97%的準(zhǔn)確率,部分字符切割問題會導(dǎo)致準(zhǔn)確率下降,不過問題不大,基本達(dá)到個人項目可用程度,Nice~~
五、CNN神經(jīng)網(wǎng)絡(luò)模型預(yù)測和部署
經(jīng)過1,2,3步循環(huán)過程后,可以用一個相對擬合穩(wěn)定的模型進(jìn)行預(yù)測集預(yù)測,因為過擬合的問題,可能有些模型在測試集表現(xiàn)較好,在測試時效果就不太好,這里需要對訓(xùn)練數(shù)據(jù),模型參數(shù)進(jìn)行排
CPU模型-預(yù)測集測試:
代碼見net_usage.py
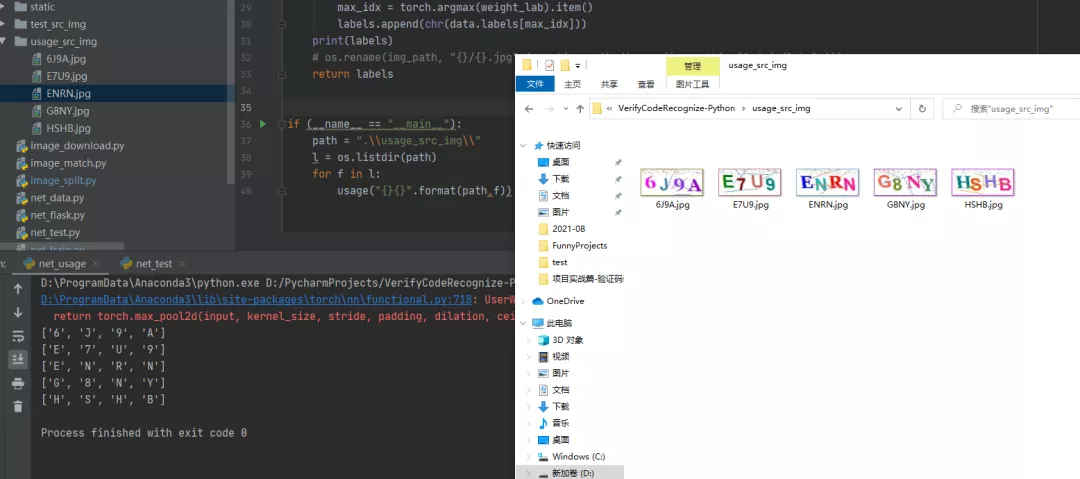
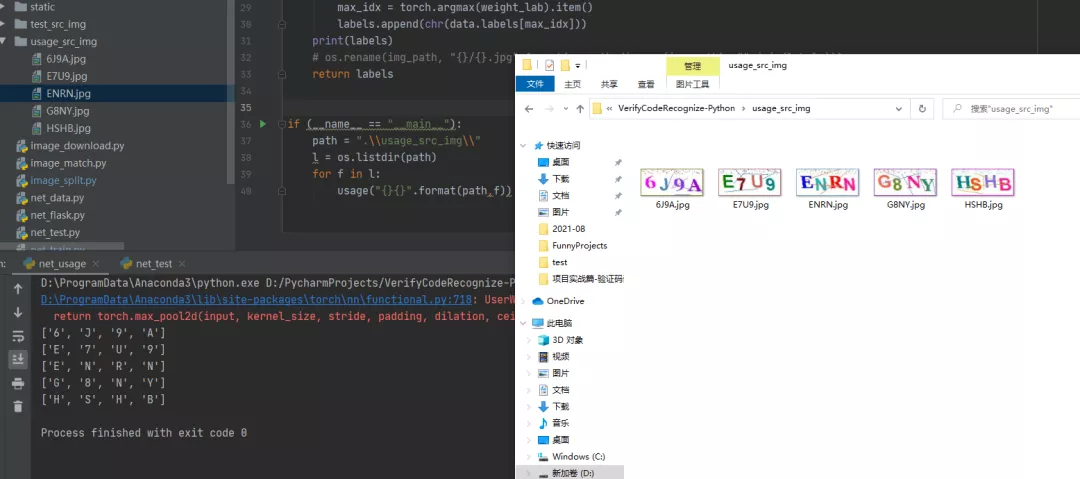
上圖可以看到,5張驗證碼的字符全部預(yù)測正確。
CPU模型-部署:
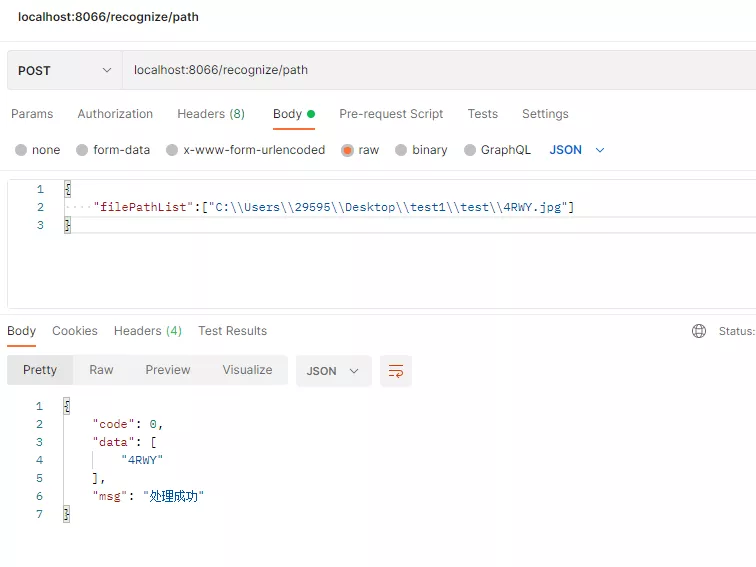
使用python的web框架Flask API,編寫圖片驗證碼識別POST接口,傳入文件路徑,啟動web應(yīng)用,以下是通過本機(jī)文件路徑識別接口代碼,詳細(xì)代碼見net_flask.py
- @app.route('/recognize/path', methods=['POST'])
- def recognize_path():
- filePathList = request.json['filePathList']
- code = CODE_SUCCESS
- msg = MSG_SUCCESS
- data = []
- for filePath in filePathList:
- if not os.path.exists(filePath):
- # code = CODE_FAIL
- # msg = "文件不存在"
- print("文件不存在:", filePath)
- data.append("")
- continue
- else:
- labels = usage_model.usage(filePath)
- data.append(''.join(labels))
- result = {'code': code, "msg": msg, "data": data}
- return jsonify(result)
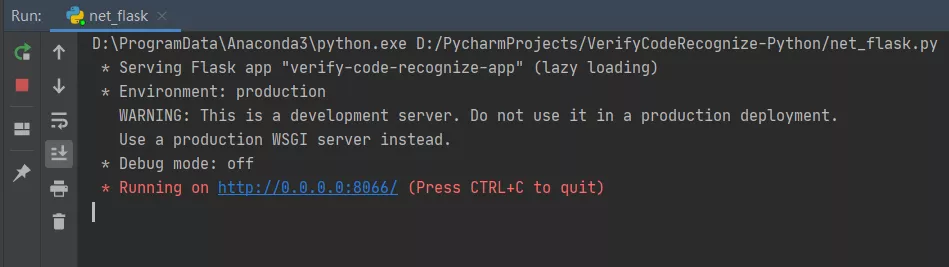
模型-Flask Web App啟動效果:
Postman接口測試效果:
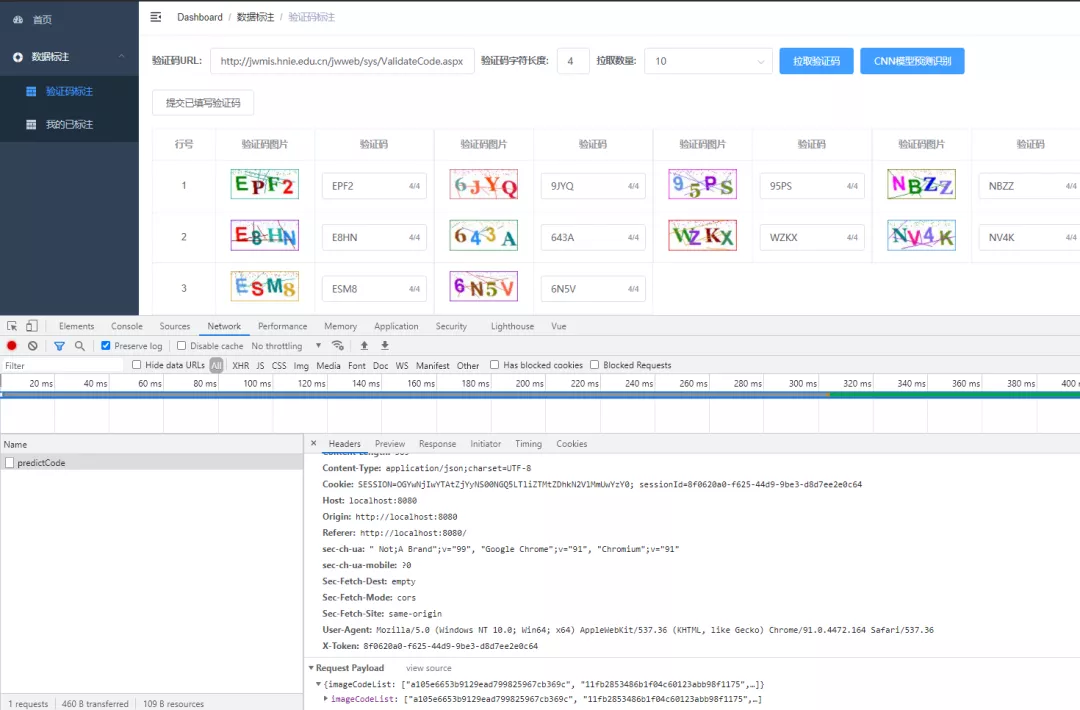
Web頁面批量請求-預(yù)測:
好的,以上就是筆者圖片驗證碼識別案例中的卷積神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練、測試、部署的全部內(nèi)容了,總的來說,從結(jié)果看模型預(yù)測效果還是非常不錯的,首先利用標(biāo)注系統(tǒng)進(jìn)行人工標(biāo)注初始數(shù)據(jù)集、下載數(shù)據(jù)集,然后再進(jìn)行數(shù)據(jù)集的準(zhǔn)備,接著進(jìn)行模型的編碼、訓(xùn)練和測試,然后利用訓(xùn)練出來的模型進(jìn)行數(shù)據(jù)預(yù)測,通過人工判斷修正再把加入到訓(xùn)練集中,從而低時間成本、高效率增加訓(xùn)練數(shù)據(jù)量。
六、總結(jié)
大家好,我是Snowball。這幾篇文章,整個過程下來,讀者就會熟悉到CNN神經(jīng)網(wǎng)絡(luò)在圖片特征提取的魅力之處,其原理還是利用概率論、機(jī)器學(xué)習(xí)知識,在多層CNN模型下,通過多層感知機(jī)的激活函數(shù)、隨機(jī)梯度下降法、損失函數(shù)、反向傳播等機(jī)制進(jìn)行復(fù)雜非線性模型參數(shù)的調(diào)節(jié),使得訓(xùn)練處理的模型概率分布盡可能接近人腦中標(biāo)注數(shù)據(jù)的概率模型。
當(dāng)然,讀者看到這里覺得這里面還有很多疑問和問題,請不要?dú)怵H,整個機(jī)器學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)的知識體系是非常龐大的,從數(shù)學(xué)理論到計算機(jī)算法,再到工程框架,細(xì)節(jié)一步步被隱藏,請保持好奇心和思考,持續(xù)了解和學(xué)習(xí),未來可能等知識積累到一定程度,那么很多問題就會明白和理解。說的東西有點多了,哈哈,總之還是,信息時代合理利用互聯(lián)網(wǎng)上的資源。