













NLP新秀prompt跨界出圈,清華劉知遠(yuǎn)最新論文將它應(yīng)用到VLM圖像端
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
NLP的新秀prompt,最近著實(shí)有點(diǎn)火。

還跨界火到了VLM(Visual-Language model,視覺(jué)語(yǔ)言模型)。
像OpenAI的CLIP,和南洋理工大學(xué)的CoOp都用了這種思路。
現(xiàn)在,清華副教授劉知遠(yuǎn)團(tuán)隊(duì)最新發(fā)布的視覺(jué)語(yǔ)言模型論文中,也提出了一種基于prompt的新方法。

據(jù)論文表示,這也是首次將prompt用于cross-model和零樣本/少樣本學(xué)習(xí)視覺(jué)定位中。
從目前的NLP和VLM模型來(lái)看,不少基于prompt的模型效果都不錯(cuò),讓搞CV的同學(xué)們也有點(diǎn)心動(dòng)——能不能給我們也整一個(gè)?
那么,prompt究竟好在哪,應(yīng)用于圖像端后是否也能收獲不錯(cuò)的效果?
一起來(lái)看看。
與微調(diào)差別在哪?
最初,在NLP模型還不太大的時(shí)候,大家會(huì)采用“預(yù)訓(xùn)練+微調(diào)(fine-tune)”的方式設(shè)計(jì)針對(duì)特定任務(wù)的模型。
這種模式下,研究人員會(huì)預(yù)先訓(xùn)練出一個(gè)效果比較好的模型,再在保留大部分模型參數(shù)的情況下,根據(jù)特定任務(wù)(下游任務(wù))調(diào)整部分參數(shù),使得它在這一任務(wù)上達(dá)到最好的效果。
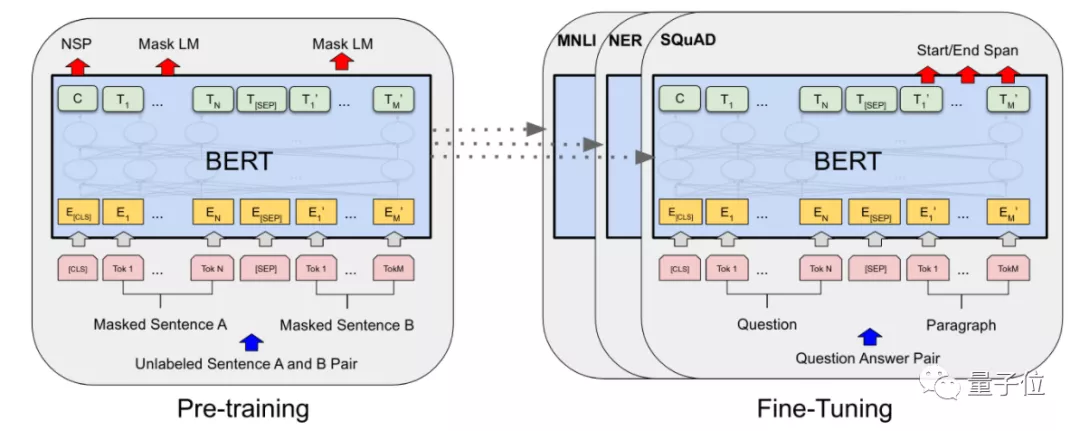
△例如以BERT作為預(yù)訓(xùn)練模型
然而,隨著預(yù)訓(xùn)練模型變得越來(lái)越大,微調(diào)的代價(jià)(訓(xùn)練時(shí)間、需求的數(shù)據(jù)量等)也在增加,研究人員有點(diǎn)吃不消了,開始找更好的方法。
prompt就在這個(gè)時(shí)候出現(xiàn)了,只不過(guò)它這次是針對(duì)下游任務(wù)進(jìn)行調(diào)整。
它有點(diǎn)像是一種輸入模板,用來(lái)給預(yù)訓(xùn)練模型“做出提示”,預(yù)訓(xùn)練模型一“看到”它,就知道自己要完成什么任務(wù)。
例如,在情感分類任務(wù)中,希望預(yù)訓(xùn)練模型能體會(huì)到輸入句子的情緒,并給出形容詞來(lái)對(duì)它分類:
輸入“I love this movie.”后,提前給定一個(gè)prompt“This movie is [mask]”,讓預(yù)訓(xùn)練模型一看到它,就明白自己要輸出“great/nice”等夸贊的形容詞。
這樣訓(xùn)練后,預(yù)訓(xùn)練模型就能在看到對(duì)應(yīng)prompt時(shí),選出正確的詞匯類型,而不是“跑偏”去做別的事情。
由于prompt在NLP領(lǐng)域的應(yīng)用效果挺好,因此在與NLP相關(guān)的VLM模型中,不少研究人員也開始嘗試這種方法。
清華將它用到圖像端
當(dāng)然,最初應(yīng)用prompt的VLM模型,大多也還仍然是將它應(yīng)用在文本端。
據(jù)知乎@陀飛輪介紹,像OpenAI的CLIP、NTU的CoOp這兩個(gè)VLM模型,prompt應(yīng)用都與NLP中的PET模型有點(diǎn)像。
從它們的模型設(shè)計(jì)來(lái)看,都能很明顯從文本端看出prompt的影子,像CLIP中的“A photo of a [mask]”:
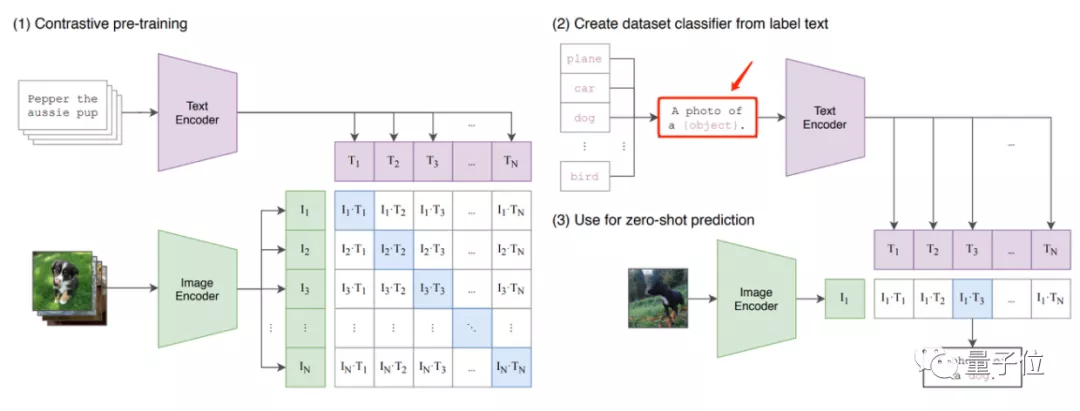
以及CoOp在CLIP上進(jìn)一步改進(jìn)的、在訓(xùn)練中能夠自行優(yōu)化的prompt:

這些prompt的應(yīng)用,整體改進(jìn)了VLM模型整體的輸出效果。
不過(guò),這也基本都是VLM在文本端的應(yīng)用,prompt到底適不適合被用在圖像端上?
最新來(lái)自清華劉知遠(yuǎn)團(tuán)隊(duì)的論文中,就嘗試著在VLM的圖像端中,以涂色的方式建立了一種visual sub-prompts。
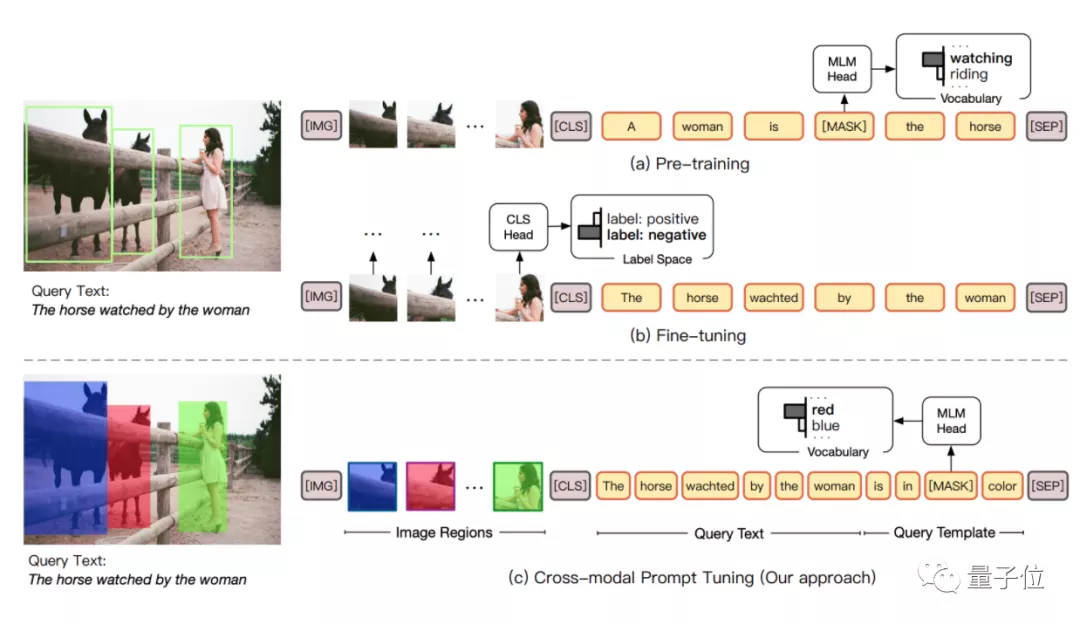
當(dāng)然,文本端也對(duì)應(yīng)用上了prompt,不過(guò)據(jù)劉知遠(yuǎn)老師介紹,prompt在文本端的應(yīng)用,感覺(jué)不足以完全發(fā)揮prompt tuning的作用,因此這篇論文嘗試了一種cross-modal prompt tuning的方法。
從論文的測(cè)試結(jié)果來(lái)看,這種方法在少樣本學(xué)習(xí)(few-shot)的情況下,基本能取得比微調(diào)更好的效果。
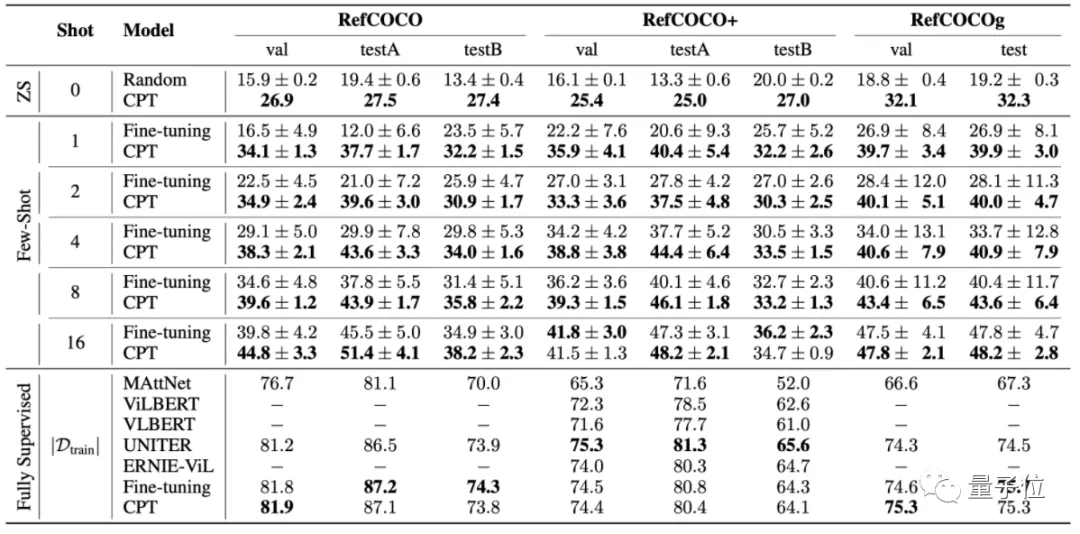
不過(guò),這也還是prompt在VLM上的另一種嘗試。
它究竟適不適合用來(lái)處理CV領(lǐng)域的圖像問(wèn)題?
CV領(lǐng)域能借鑒嗎?
在知乎上,有不少博主給出了自己的看法。
知乎@陀飛輪從方法上給出了兩條路徑:
如果是純CV方向的prompt,也就是類似于ViT將圖片拆分patch,每個(gè)patch實(shí)際上可以看成一個(gè)字符,那么也可以設(shè)計(jì)patch的prompt對(duì)模型進(jìn)行訓(xùn)練,這其中也可以分成生成式(類似ViT)和判別式(類似self-supervised)兩種方法。
知乎@yearn則認(rèn)為,就目前來(lái)看,continuous prompt是最有可能transfer到CV領(lǐng)域的一系列工作。最近transformer準(zhǔn)備大一統(tǒng)CV,NLP,將image輸入轉(zhuǎn)化為patch的形式,也讓研究人員更方便借鑒NLP的方法學(xué)習(xí)prompt。
當(dāng)然,@yearn也表示,要想真正將prompt應(yīng)用到CV領(lǐng)域,還存在兩個(gè)需要解決的難題:
1、CV還不存在BERT,GPT這樣具有統(tǒng)治力的預(yù)訓(xùn)練模型,因此近期內(nèi)可能很難將prompt 做few-shot learning這一套搬過(guò)來(lái)。
2、CV的downstream task更加復(fù)雜,感覺(jué)檢測(cè),分割這類任務(wù)要把prompt調(diào)work是一個(gè)非常大的工作量。
但也有匿名用戶直接認(rèn)為,圖像上只能用非常別扭的方法做一些任務(wù)。當(dāng)然,視頻反而可能應(yīng)用得更好。

那么,你認(rèn)為prompt能應(yīng)用在CV領(lǐng)域嗎?
劉知遠(yuǎn)團(tuán)隊(duì)最新論文:
https://arxiv.org/abs/2109.11797
知乎回答(已授權(quán)):
@陀飛輪:https://www.zhihu.com/question/487096135/answer/2127127513
@yearn:https://www.zhihu.com/question/487096135/answer/2124603834




















