談談基于深度學習的目標檢測網絡為什么會誤檢,以及如何優化目標檢測的誤檢問題
對于以人臉檢測為代表的目標檢測深度學習網絡來說,誤檢是一件非常惱人的事情。把狗檢測為貓尚可接受,畢竟有些狗的確長得像貓,但是把墻壁、燈泡、拳頭、衣服檢測成人臉就不能忍了,明明一點都不像。稍稍思考下,我感覺應該能夠從兩個方面解釋下誤檢問題。
圖像內容問題
在訓練人臉檢測網絡時,一般都會做數據增強,為圖像模擬不同姿態、不同光照等復雜情況,這就有可能產生過亮的人臉圖像,“過亮”的人臉看起來就像發光的燈泡一樣。。。如果 發光燈泡 經過網絡提取得到的特征,和 過亮人臉 經過網絡提取得到的特征相似度達到臨界值,那么網絡把發光燈泡檢測為人臉就不足為奇了。
同樣的道理,用于訓練網絡的人臉數據集中,若是存在一些帶口罩,帶圍巾的人臉圖像,那么網絡就極有可能“記住”口罩、圍巾的特征,在預測階段,要是有物體(比如衣服)表現得像口罩、圍巾,那么網絡就有可能把該物體檢測成人臉。
當然,以上討論都是啟發性的,本文暫時不把它當做討論重點。
目標 bbox 的范圍問題
目前非常流行的深度學習目標檢測網絡(SSD、YOLO、RetinaFace 等)在訓練階段,我們需要提供目標在圖像中的 bbox,所謂 bbox,其實主要就是指目標的外接矩形。這樣訓練而來的網絡在預測階段,一般給出的也是目標的外接矩形。
問題就出在 bbox 上,接下來的討論還是以人臉檢測為例,請看下圖:

這是一個典型的目標 bbox。bbox 本質上是矩形,但通常目標(人臉)不是矩形,bbox 內部包含一些非人臉內容, 我認為這些非人臉內容要對誤檢負一部分責任 。
常用的人臉檢測網絡一般使用大量的卷積層提取圖像特征,得到的特征圖尺寸通常小于原始輸入圖像數倍(取決于卷積的 stride、padding 等參數),網絡對特征圖的每一個“像素點”做二分類(人臉類、背景類),“誤檢”就是在這個二分類過程中產生的。
數倍小的特征圖的一個“像素點”都對應著原圖的一小塊矩形區域內的像素,這么看來,特征圖的每一個“像素點”都可視為一個 bbox,只不過這些 bbox 有的屬于背景類,有的屬于人臉類。
為了簡單,將人臉檢測網絡的二分類分支抽離出來,設為 p_{\theta } ,再令 x 表示特征圖中的“像素點”, q 表示該像素點的標簽,則訓練 p_{\theta } 的一個常用方法就是優化下述目標:
- \underset{\theta}{argmax}{\mathbb{E}_{x \sim p_{\theta}(x)}}\frac{p_{\theta}(y|x)}{q(y|x)}
其中 y 為 0(背景類)/1(人臉類)標簽。 對于人臉類 ,理想情況下,我們希望 x 為人臉數據,但是實際上 x 卻是一小塊 矩形 區域內部的所有圖像數據,這個 矩形 內部常常包含一些非人臉數據,因此實際被優化的目標為:
- \underset{\theta}{argmax}{\mathbb{E}_{x \sim p_{\theta}(x+\Delta x)}}\frac{p_{\theta}(y|x+\Delta x)}{q(y|x+\Delta x)}
上式中 x 表示人臉數據, \Delta x 表示非人臉數據。通常 q(y|x+\Delta x) 是人工標注的標簽,因此 \Delta x 不會影響 q 的結果,優化下述目標就可以了:
- \underset{\theta}{argmax}{\mathbb{E}_{x \sim p_{\theta}(x+\Delta x)}}\frac{p_{\theta}(y|x+\Delta x)}{q(y|x)}
我們以為訓練得到的是 p_{\theta}(y|x) ,實際得到的卻是 p_{\theta}(y|x+\Delta x) ,可以認為 \Delta x 的存在是引起誤檢的主要原因之一。
優化誤檢問題
既然 \Delta x 的存在會引起誤檢,那么優化該問題直觀上有以下方法:
- 令 \Delta x \rightarrow 0
- 令 p_{\theta}(y|x+\Delta x) \rightarrow p_{\theta}(y|x)
遺憾的是,這兩個方法在實踐中都很難 直接 實現。雖然我們可以不考慮人工成本,將粗糙的人臉 bbox 用更加精細的多邊形代替,但是縮放數倍的卷積特征圖本身也隱含著“矩形框”,另外, 人眼認為的“人臉”未必是網絡認為的“人臉” 。
本文不考慮像素級別的語義分割任務。
稍稍再想一想,不難發現,雖然上述理論是將 x 和 \Delta x 作為彼此獨立的像素集合處理得到的,但是我們可以對該理論做稍許推廣,也即:將 x 視為 bbox 內的所有像素, \Delta x 視為 bbox 內所有干擾人臉誤檢的像素差值,那么該理論就更加有用了。
我們完成了優化人臉檢測網絡誤檢問題的理論構建,該理論將指導接下來的網絡,以及對應的損失函數設計。
構建深度學習網絡
構建 s_w 的方法有多種,下面是我做實驗時簡單構建的網絡關鍵部分的結構示意圖(這樣構造有些粗糙,但是多少能夠驗證下理論):
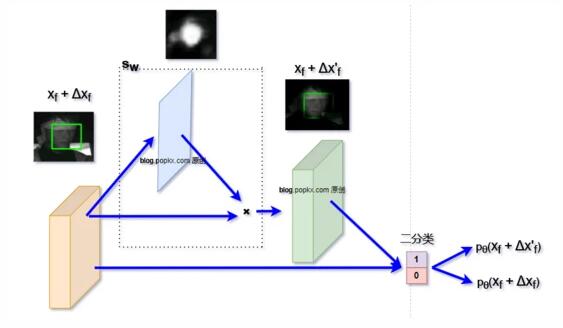
常規方法在得到特征圖 x_f + \Delta x_f 時,就直接將其送到背景/人臉二分類網絡分支做分類了。在上圖的網絡架構中,我們增加了額外的一個分支,該分支從特征圖 x_f + \Delta x_f 得到一個同尺寸的 1 通道人臉特征概率圖,該特征概率圖與 x_f + \Delta x_f 相乘即可得到 x_f + \Delta x'_f ,這樣就可以得到兩個分類結果:
- p_{\theta}(x_f + \Delta x_f)
- p_{\theta}(x_f + \Delta x'_f)
再根據前面理論分析得到的 s_w 優化方法,同步優化 \theta 和 w ,即可完成訓練。
若干可視化訓練效果
這里我沒有太過仔細的測試,只在手邊的 RetinaFace 網絡上增加了前面上述結構,訓練 10 個 epoch 后,中間生成一些可視效果圖:

左:原圖及bbox標簽;中:人臉特征概率圖;右:經過 s_w 處理過的圖。
可以看出,雖然 標簽是矩形的 bbox,但是通過簡單增加一條訓練分支,我們得到了類似于語義分割的效果。

此外,從效果圖2中可以看出,網絡認為的人臉區域與人眼感受的區域并不完全一致,但是總體是保留關鍵特征的。類似的還有下圖。


誤檢的優化效果
還是偷懶,暫時沒有太過詳細的測試,只在一個非常小(1000張規模)的數據集上做了測試,誤檢降低了 5.2%,對比對象為:
- p_{\theta}(x_f + \Delta x_f)
- p_{\theta}(x_f + \Delta x'_f)
當然,這只是我粗略訓練和測試的結果。后續有時間再嘗試仔細構造下網絡設計以及訓練,補上公開數據集的測試結果對比吧。