













譯者 | 崔皓
審校 | 重樓
摘要
Google Research的研究科學(xué)家Arsha Nagrani和Paul Hongsuck Seo介紹了一種名為AVFormer的新技術(shù),該技術(shù)將視覺理解能力注入現(xiàn)有的僅音頻ASR模型中,以提高其在各種領(lǐng)域的泛化性能。AVFormer通過(guò)使用輕量級(jí)的可訓(xùn)練適配器,將視覺嵌入注入凍結(jié)的ASR模型中,這些適配器可以在少量弱標(biāo)簽視頻數(shù)據(jù)上進(jìn)行訓(xùn)練,額外的訓(xùn)練時(shí)間和參數(shù)最少。這種方法實(shí)現(xiàn)了零樣本性能,即在未經(jīng)手動(dòng)注釋的AV-ASR數(shù)據(jù)集上進(jìn)行訓(xùn)練的情況下,實(shí)現(xiàn)了最先進(jìn)的性能。

【編者:在機(jī)器學(xué)習(xí)和深度學(xué)習(xí)中,"凍結(jié)"一般指的是在訓(xùn)練過(guò)程中保持模型的某些部分或參數(shù)不變。這通常是通過(guò)禁止反向傳播過(guò)程中對(duì)這些參數(shù)的更新來(lái)實(shí)現(xiàn)的。"凍結(jié)的語(yǔ)音模型"意味著這個(gè)語(yǔ)音識(shí)別模型在被用于新的視覺任務(wù)時(shí),其參數(shù)保持不變,不會(huì)被進(jìn)一步訓(xùn)練或調(diào)整。】
開篇
自動(dòng)語(yǔ)音識(shí)別(ASR)是一項(xiàng)成熟的技術(shù),廣泛應(yīng)用于各種應(yīng)用,如電話會(huì)議、視頻轉(zhuǎn)錄和語(yǔ)音命令。雖然這項(xiàng)技術(shù)的挑戰(zhàn)主要集中在嘈雜的音頻輸入上,但多模態(tài)視頻(例如,電視,在線編輯的視頻)中的視覺流可以為提高ASR系統(tǒng)的魯棒性提供強(qiáng)有力的線索,這就是所謂的音頻視覺ASR(AV-ASR)。
【編者:"Zero-shot"是機(jī)器學(xué)習(xí)中的一個(gè)術(shù)語(yǔ),通常用于描述一種特殊的訓(xùn)練和測(cè)試情況。在這種情況下,模型在沒有看過(guò)任何特定類別的訓(xùn)練樣本的情況下,被要求識(shí)別該類別的實(shí)例。這通常通過(guò)訓(xùn)練模型來(lái)理解和利用類別之間的某種結(jié)構(gòu)或關(guān)系來(lái)實(shí)現(xiàn)。
例如,如果你有一個(gè)模型,它已經(jīng)學(xué)會(huì)了識(shí)別貓和狗,然后你要求它識(shí)別一只兔子,盡管它從未在訓(xùn)練數(shù)據(jù)中見過(guò)兔子。如果模型能夠正確地識(shí)別出兔子,那么我們就說(shuō)它具有"零樣本/零射擊"的能力。
在這篇文章中,"Zero-Shot"是指模型在未經(jīng)手動(dòng)注釋的AV-ASR數(shù)據(jù)集上進(jìn)行訓(xùn)練的情況下,實(shí)現(xiàn)了最先進(jìn)的性能。換句話說(shuō),模型能夠處理和理解它在訓(xùn)練階段從未見過(guò)的數(shù)據(jù)類型或情況。】
盡管唇動(dòng)可以為語(yǔ)音識(shí)別提供強(qiáng)烈的信號(hào),并且是AV-ASR最常關(guān)注的區(qū)域,但在野外的視頻中,口部往往不直接可見(例如,由于以自我為中心的視點(diǎn),面部覆蓋物和低分辨率),因此,一個(gè)新興的研究領(lǐng)域是無(wú)約束的AV-ASR(例如,AVATAR),它研究整個(gè)視覺幀的貢獻(xiàn),而不僅僅是口部區(qū)域。
然而,構(gòu)建用于訓(xùn)練AV-ASR模型的音頻視覺數(shù)據(jù)集是具有挑戰(zhàn)性的。如How2和VisSpeech這樣的數(shù)據(jù)集已經(jīng)從在線教學(xué)視頻中創(chuàng)建,但它們的規(guī)模較小。相比之下,模型本身通常很大,包含視覺和音頻編碼器,因此它們傾向于在這些小數(shù)據(jù)集上過(guò)度擬合。盡管如此,最近發(fā)布了一些大規(guī)模的僅音頻模型,這些模型通過(guò)大規(guī)模訓(xùn)練在大量?jī)H音頻數(shù)據(jù)上進(jìn)行了大量?jī)?yōu)化,這些數(shù)據(jù)來(lái)自音頻書籍,如LibriLight和LibriSpeech。這些模型包含數(shù)十億個(gè)參數(shù),隨時(shí)可用,并在各個(gè)領(lǐng)域顯示出強(qiáng)大的泛化能力。
考慮到上述挑戰(zhàn),在“AVFormer:將視覺注入凍結(jié)的語(yǔ)音模型,實(shí)現(xiàn)零樣本AV-ASR”中,我們提出了一種簡(jiǎn)單的方法,用視覺信息增強(qiáng)現(xiàn)有的大規(guī)模僅音頻模型,同時(shí)進(jìn)行輕量級(jí)的領(lǐng)域適應(yīng)。AVFormer將視覺嵌入注入凍結(jié)的ASR模型(類似于Flamingo如何將視覺信息注入大型語(yǔ)言模型進(jìn)行視覺-文本任務(wù)),使用輕量級(jí)可訓(xùn)練的適配器,這些適配器可以在少量弱標(biāo)簽視頻數(shù)據(jù)上進(jìn)行訓(xùn)練,額外的訓(xùn)練時(shí)間和參數(shù)最少。我們還引入了一個(gè)簡(jiǎn)單的課程方案,在訓(xùn)練過(guò)程中,我們發(fā)現(xiàn)使模型能夠有效地處理音頻和視覺信息至關(guān)重要。最終的AVFormer模型在三個(gè)不同的AV-ASR基準(zhǔn)測(cè)試(How2,VisSpeech和Ego4D)上實(shí)現(xiàn)了最先進(jìn)的零樣本性能,同時(shí)也保持了在傳統(tǒng)的僅音頻語(yǔ)音識(shí)別基準(zhǔn)測(cè)試(即LibriSpeech)上的良好性能。
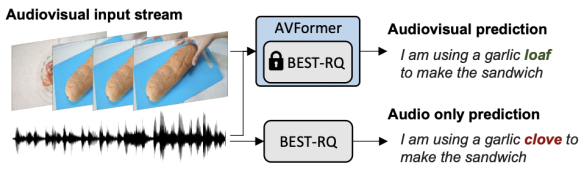
使用輕量級(jí)模塊注入視覺"
我們的目標(biāo)是將視覺理解能力添加到現(xiàn)有的僅音頻ASR模型中,同時(shí)保持其對(duì)各種領(lǐng)域(包括AV和僅音頻領(lǐng)域)的泛化性能。
為了實(shí)現(xiàn)這一目標(biāo),我們將現(xiàn)有的最先進(jìn)的ASR模型(Best-RQ)增強(qiáng)了以下兩個(gè)組件:(i)線性視覺投影器和(ii)輕量級(jí)適配器。前者將視覺特征投影到音頻令牌嵌入空間。這個(gè)過(guò)程使模型能夠正確地連接單獨(dú)預(yù)訓(xùn)練的視覺特征和音頻輸入令牌表示。然后,后者最小化地修改模型,以增加對(duì)來(lái)自視頻的多模態(tài)輸入的理解。然后,我們?cè)贖owTo100M數(shù)據(jù)集的未標(biāo)記網(wǎng)絡(luò)視頻上,以及ASR模型的輸出作為偽真實(shí)值,訓(xùn)練這些額外的模塊,同時(shí)保持Best-RQ模型的其余部分凍結(jié)。這樣的輕量級(jí)模塊使得數(shù)據(jù)效率和性能的強(qiáng)大泛化成為可能。
我們?cè)诹銟颖驹O(shè)置中,在AV-ASR基準(zhǔn)測(cè)試上評(píng)估了我們的擴(kuò)展模型,其中模型從未在手動(dòng)注釋的AV-ASR數(shù)據(jù)集上進(jìn)行過(guò)訓(xùn)練。
為視覺注入設(shè)置課程學(xué)習(xí)
在初步評(píng)估之后,我們經(jīng)驗(yàn)性地發(fā)現(xiàn),通過(guò)一輪簡(jiǎn)單的聯(lián)合訓(xùn)練,模型很難一次性學(xué)習(xí)適配器和視覺投影器。為了解決這個(gè)問(wèn)題,我們引入了一個(gè)兩階段的課程學(xué)習(xí)策略,該策略解耦了這兩個(gè)因素——領(lǐng)域適應(yīng)和視覺特征集成——并以順序的方式訓(xùn)練網(wǎng)絡(luò)。在第一階段,優(yōu)化適配器參數(shù),完全不需要輸入視覺令牌。一旦適配器被訓(xùn)練,我們?cè)诘诙A段添加視覺令牌,并單獨(dú)訓(xùn)練視覺投影層,同時(shí)保持訓(xùn)練過(guò)的適配器凍結(jié)。
第一階段專注于音頻領(lǐng)域的適應(yīng)。到了第二階段,適配器完全凍結(jié),視覺投影器只需學(xué)習(xí)生成視覺提示,將視覺令牌投影到音頻空間。通過(guò)這種方式,我們的課程學(xué)習(xí)策略允許模型同時(shí)接納視覺輸入和適應(yīng)AV-ASR基準(zhǔn)測(cè)試中的新音頻領(lǐng)域。我們只應(yīng)用每個(gè)階段一次,因?yàn)榻惶骐A段的迭代應(yīng)用會(huì)導(dǎo)致性能下降。
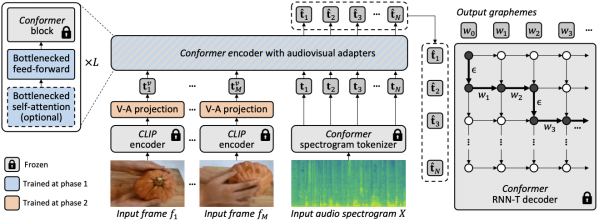
【編者:在第一階段,他們優(yōu)化了模型的"適配器"參數(shù)。適配器是模型的一部分,它的任務(wù)是幫助模型適應(yīng)新的領(lǐng)域或任務(wù)。在這個(gè)階段,他們并沒有使用任何視覺信息,只是讓模型更好地處理音頻信息。
一旦適配器被訓(xùn)練好,他們進(jìn)入了第二階段。在這個(gè)階段,他們開始添加視覺信息,并訓(xùn)練模型的"視覺投影器"部分。視覺投影器的任務(wù)是將視覺信息轉(zhuǎn)換成模型可以理解的形式。在這個(gè)階段,他們保持適配器的參數(shù)不變,只訓(xùn)練視覺投影器。
這種分階段的訓(xùn)練策略允許模型逐步學(xué)習(xí)如何處理視覺和音頻信息,而不是一次性地學(xué)習(xí)所有的東西。這樣做的好處是,它可以防止模型在訓(xùn)練過(guò)程中出現(xiàn)性能下降的問(wèn)題。】
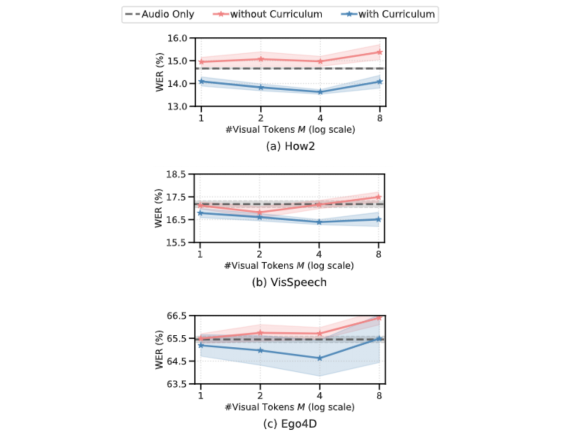
以下的圖表顯示,如果沒有課程學(xué)習(xí),我們的AV-ASR模型在所有數(shù)據(jù)集上都比僅音頻的基線模型差,隨著添加更多的視覺令牌,差距增大。相比之下,當(dāng)應(yīng)用了我們提出的兩階段課程時(shí),我們的AV-ASR模型的性能明顯優(yōu)于基線的僅音頻模型。
零樣本AV-ASR的結(jié)果
我們將AVFormer與BEST-RQ(我們模型的音頻版本)和AVATAR(AV-ASR的最新技術(shù))進(jìn)行比較,對(duì)三個(gè)AV-ASR基準(zhǔn)測(cè)試:How2,VisSpeech和Ego4D的零樣本性能進(jìn)行比較。AVFormer在所有方面都超過(guò)了AVATAR和BEST-RQ,甚至在LibriSpeech和完整的HowTo100M集合上進(jìn)行訓(xùn)練時(shí),也超過(guò)了AVATAR和BEST-RQ。值得注意的是,對(duì)于BEST-RQ而言訓(xùn)練參數(shù)為600M,而AVFormer的訓(xùn)練參數(shù)是4M,因此只需要訓(xùn)練數(shù)據(jù)集的一小部分(HowTo100M的5%)就可以達(dá)到效果。此外,我們還在LibriSpeech上評(píng)估了性能,僅音頻這一項(xiàng),AVFormer就超過(guò)了兩個(gè)基線。
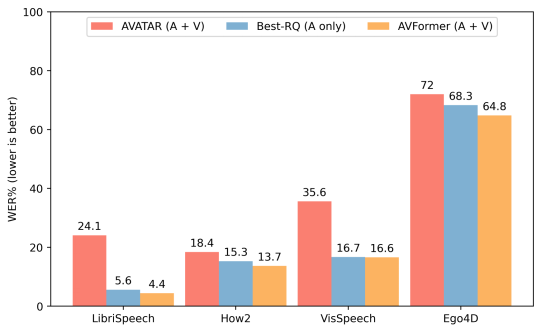
與不同AV-ASR數(shù)據(jù)集的零樣本性能的最新方法進(jìn)行比較。展示了在僅音頻的LibriSpeech上的性能。結(jié)果顯示W(wǎng)ER%(越低越好)的報(bào)告。AVATAR和BEST-RQ在HowTo100M上進(jìn)行了端到端的微調(diào)(所有參數(shù)),而AVFormer即使只使用了數(shù)據(jù)集的5%,也能有效工作,這得益于微調(diào)參數(shù)的小集合
結(jié)論
我們介紹了AVFormer,這是一種輕量級(jí)的方法,用于將現(xiàn)有的,凍結(jié)的最先進(jìn)的ASR模型適應(yīng)AV-ASR。我們的方法實(shí)用且高效,實(shí)現(xiàn)了令人印象深刻的零樣本性能。隨著ASR模型越來(lái)越大,調(diào)整預(yù)訓(xùn)練模型的整個(gè)參數(shù)集變得不切實(shí)際(對(duì)于不同的領(lǐng)域更是如此)。我們的方法無(wú)縫地實(shí)現(xiàn)了,在同一個(gè)參數(shù)有效的模型中進(jìn)行領(lǐng)域轉(zhuǎn)移和視覺輸入混合。
譯者介紹
崔皓,51CTO社區(qū)編輯,資深架構(gòu)師,擁有18年的軟件開發(fā)和架構(gòu)經(jīng)驗(yàn),10年分布式架構(gòu)經(jīng)驗(yàn)。
原文標(biāo)題:AVFormer: Injecting vision into frozen speech models for zero-shot AV-ASR,作者:Arsha Nagrani,Paul Hongsuck Seo



























