多線程異步【日志系統】,高效、強悍的實現方式:雙緩沖!
別人的經驗,我們的階梯!
大家好,我是道哥,今天我為大伙兒解說的技術知識點是:【在多線程環境下,如何實現一個高效的日志系統】。
在很久之前,曾經寫過一篇文章《【最佳實踐】生產者和消費者模式中的雙緩沖技術》,討論了:在一個產品級的日志系統中,如何利用雙緩沖機制來解決生產者-消費者相關的問題。
前段時間,有位小伙伴私信給我,希望可以具體聊一下這個實現方案。
本來答應在國慶期間完成的,但是我的拖延癥一犯再犯,一直拖到今天,終于把這個作業給補上了。
雙緩沖這個思路并不是我原創的,而是參考了大神陳碩老師的一本書《Linux 多線程服務端編程》。
從書名就可以看出,討論的是服務器端的相關編程內容,而且是多線程場景下的,因此可以隱約看出,書中給出的參考代碼的質量是很高的。
如果您的主力開發語言是 C++,強烈推薦您去研究下這本書。
很多 C++ 語言的細節問題,作者都給出了自己專業、嚴謹的思考和解決方案。
言歸正傳!
在上一篇文章中,我主要從思路、概念的角度,來描述如何利用雙緩沖機制。
這篇文章,我們就忠于書中原文,一起來學習一下作者的思考過程,并給出一些對性能起決定作用的關鍵代碼。
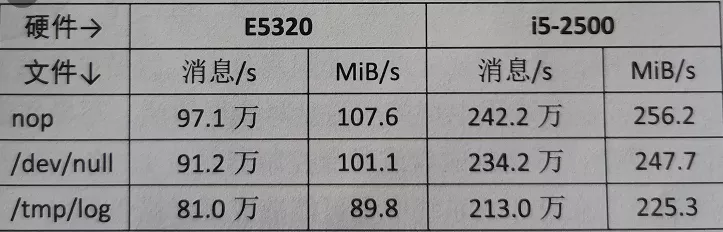
先來看一下書中的性能測試結果:
單片機中常用的環形緩沖區
一說到緩沖區,相信各位小伙伴一定看過很多關于緩沖緩沖區的文章和代碼,在單片機中的使用率很高。
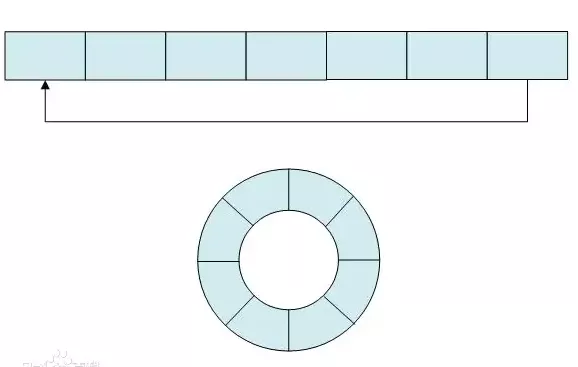
所謂的環形緩沖區,就是一塊平整的內存區域,讓它的尾部連接到首部即可。
- 另一個類似的結構:環形隊列,本質上都是一樣的。
維護環形緩沖區的數據結構中,有head和tail指針。
當寫入的時候,把輸入寫入到tail指針的位置,寫完之后,遞增tail的指針值;
當讀取的時候,從head指針的位置開始讀取,讀完之后,也遞增head的指針值。
這樣的操作方式,比較適合那種簡單的單輸入、單輸出場景。
只要處理好:當 head 和 tail 這兩個指針交匯的時候如何處理即可。
但是在x86的操作系統中,在多核 + 多線程的工作環境下,無論是從功能上、還是從性能上來考慮,這樣的環形緩沖區就滿足不了需求了。
還是拿日志系統來舉例:在一個應用程序中,可能會有多個線程同時調用日志系統的寫入API接口函數,這就需要保證線程安全。
- 這樣的線程稱作 前臺/前端 線程。
日志數據存儲在內存中之后,最終是要輸出的,比如:寫入到文件系統、通過網絡上傳到服務端、輸出到其他的監控系統等等。
實現輸出操作的也是一個線程,假如需要寫入到文件系統,那么在寫入期間,這個線程就需要一直持有緩沖區中的日志數據。
- 這樣的線程稱作 后臺/后端 線程。
但是,文件系統的寫入速度是很慢的(畢竟要操作硬盤啊),如果這個時候又有前臺線程需要寫日志信息了,該如何處理?
總不能暴力的說:后臺線程正在把現有的日志數據存儲到硬盤上,已經持有了內存緩沖區,前臺線程你是后來的,先等著!
多線程異步日志:雙緩沖機制
在這本書中,作者對這樣的日志系統規定了幾個關鍵的要求,都是與實際的業務需求相關的:
- 線程安全:多個線程可以并發寫日志,不造成競爭,兩個線程的日志信息不會交叉出現;
- 吞吐量大;
- 日志消息有多種級別,格式可配置等等;
為了達到這個目的,作者提出了“雙緩沖”思路(Double Buffering)。
基本思路是:
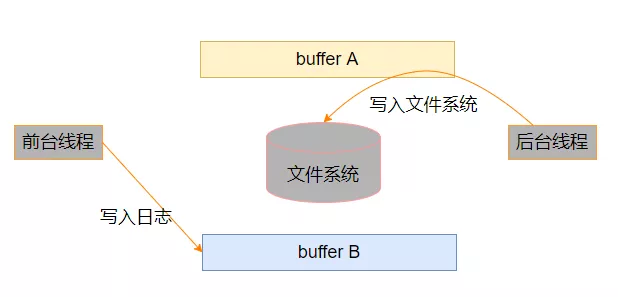
準備兩塊 buffer: A 和 B;
前端負責往 buffer A 填數據(日志信息);
后端負責把 buffer B 的數據寫入文件。
當 buffer A 寫滿之后,交換 A 和 B,讓后端將 buffer A 的數據寫入文件,而前端則往 buffer B 填入新的日志信息,如此反復。
其實還是蠻好理解的哈,我們還是來畫圖描述一下:
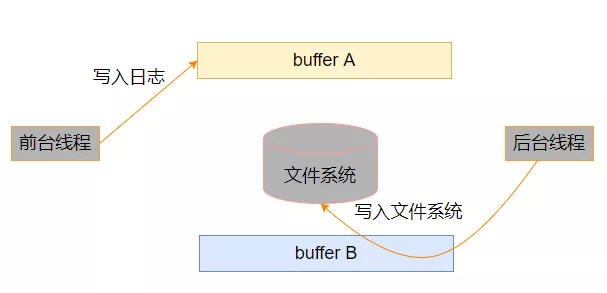
當 buffer A 寫滿之后,交換兩個緩沖區:
雙緩沖機制為什么高效
使用兩個buffer緩沖區的好處是:
在大部分的時間中,前臺線程和后臺線程不會操作同一個緩沖區,這也就意味著前臺線程的操作,不需要等待后臺線程緩慢的寫文件操作(因為不需要鎖定臨界區)。
還有一點就是:后臺線程把緩沖區中的日志信息,寫入到文件系統中的頻率,完全由自己的寫入策略來決定,避免了每條新日志信息都觸發(喚醒)后端日志線程。
例如:可以根據實際使用場景,定義一個刷新頻率,例如:3秒。
只要刷新時間到了,即使緩沖區中的日志信息很少,也要把它們存儲到文件系統中。
換言之,前端線程不是將一條條日志信息分別傳送給后端線程,而是將多條信息拼成一個大的 buffer 傳送給后端,相當于是批量處理,減少了線程喚醒的頻率,降低開銷。
盡可能的降低 Lock 的時間
在剛才的描述中,有這么一句話:在[大部分的時間中],前臺線程和后臺線程不會操作同一個緩沖區。
也就是是說,在小部分時間內,它們還是有可能操作同一個緩沖區的。
那就是:當前臺的寫入緩沖區 buffer A 被寫滿了,需要與 buffer B 進行交換的時候。
交換的操作,是由后臺線程來執行的,具體流程是:
- 后臺線程被喚醒,此時 buffer B 緩沖區是空的,因為在上一次進入睡眠之前,buffer B 中數據已經被寫入到文件系統中了;
- 把 buffer A 與 buffer B 進行交換;
- 把 buffer B 中的數據寫入到文件系統;
- 開始休眠;
在第2個步驟中:交換緩沖區,就是把兩個指針變量的值交換一下而已,利用C++語言中的swap操作,效率很高。
在執行交換緩沖區的時候,可能會有前臺線程寫入日志,因此這個步驟需要在 Lock 的狀態下執行。
可以看出:這個雙緩沖機制的前后臺日志系統,需要鎖定的代碼僅僅是交換兩個緩沖區這個動作,Lock 的時間是極其短暫的!這就是它提高吞吐量的關鍵所在!
參考代碼
在示例代碼中,作者對雙緩沖機制進行了擴展,采用4個緩沖區,這樣可以進一步減少或避免前端線程的等待時間。
數據結構如下:

這里的 nextBuffer_ 相當有是currentBuffer_的“備胎”。
當前臺線程發現currentBuffer_不可用時(空間已滿,或者正在被后臺線程操作),可以立刻寫入到這個"備胎"緩沖區中,從而降低了前臺線程的等待時間。
下面是前臺線程的寫入代碼:
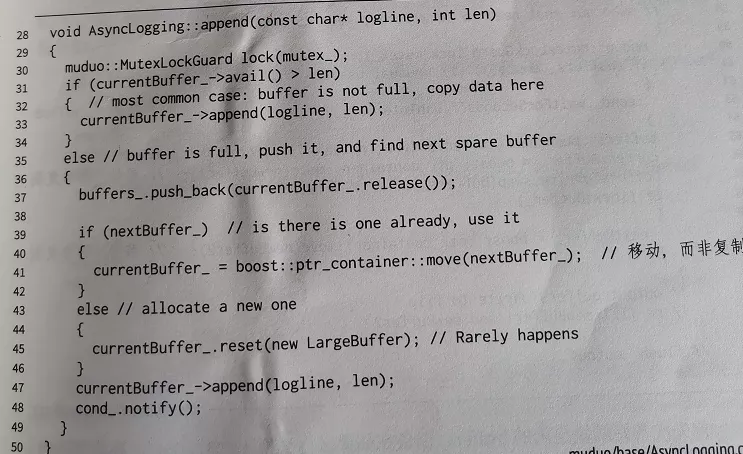
前端線程在生成一條日志消息的時候,會調用append()函數。
在這個函數中,如果當前緩沖區(currentBuffer_)剩余的空間足夠大,直接把消息消息拷貝(追加)進去,這是最常見的情況。
如果當前緩沖區的剩余空間,小于這次日志信息的寫入長度,就把它移動到 buffer_ 集合中(一個Vector),此時會發送喚醒信號給后端線程,然后把 nextBuffer_ 這個備胎 move 為 currentBuffer_。
- move 是 C++ 中的操作,意思是移動,而不是拷貝/復制。
當然了,如果前端的寫入速度太快,一下子就把兩塊緩沖區都用完了,那么只好分配一塊新的 buffer 作為當前緩沖區,這是極少發生的情況。
再來看看后端的代碼實現,這里只貼出了最關鍵的臨界區內的代碼,也就是前文所說的“小部分時間”的情況:

這段代碼中最重要的就是 swap 函數,它把前后臺使用的緩沖區進行了交換。
當前后臺緩沖區交換之后,就離開了臨界區,此時后臺線程就可以慢慢的往文件系統中寫入數據了。
另外,這段代碼中還有一個地方比較有意思,就是對備胎 nextBuffer_ 的操作:
當前臺中使用的備胎 nextBuffer_ 已經被消耗掉時,后臺線程及時地為它補充一個新的備胎。
可以繼續優化的地方
在本章的最后部分,作者提出了一個更加嚴苛的情況:
異步日志系統中,使用了一個全局鎖,盡管臨界區很小,但是如果線程數目較多,鎖爭用也可能影響性能。
一種解決方法是像 Java 的 ConCurrentHashMap 那樣使用多個桶子(bucket),前端線程寫日志的時候根據線程id哈希到不同的 bucket 中,以減少競爭。
這種解決方案本質上就是提供更多的緩沖區,并且把不同的緩沖區分配給不同的線程(根據線程 id 的哈希值)。
那些哈希到相同緩沖區的線程,同樣是存在爭用的情況的,只不過爭用的概率被降低了很多。
本文轉載自微信公眾號「IOT物聯網小鎮」