













使用 Python 創建一個簡單的基于規則的聊天機器人
還記得這個價值一個億的AI核心代碼?
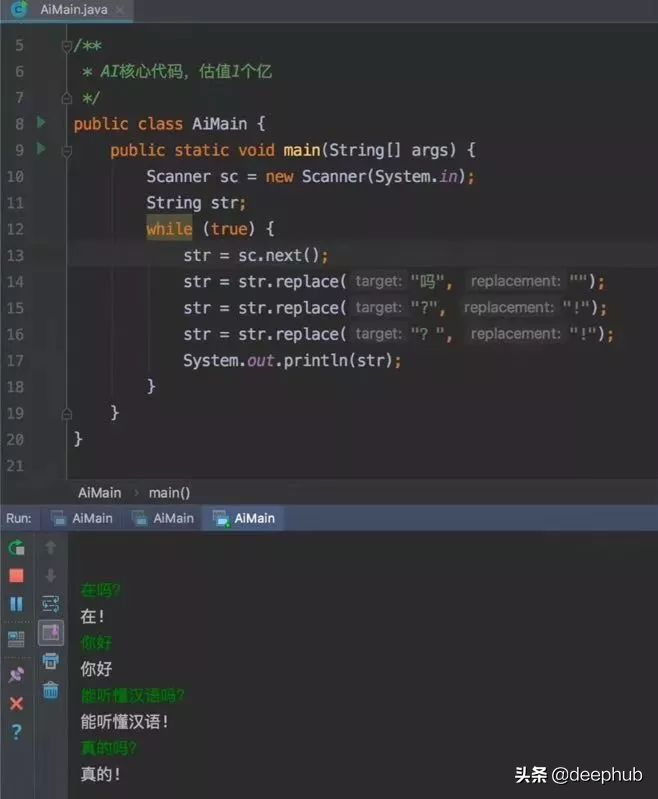
- while True:
- AI = input('我:')
- print(AI.replace("嗎", " ").replace('?','!').replace('?','!'))
以上這段代碼就是我們今天的主題,基于規則的聊天機器人
聊天機器人
聊天機器人本身是一種機器或軟件,它通過文本或句子模仿人類交互。 簡而言之,可以使用類似于與人類對話的軟件進行聊天。
為什么要嘗試創建聊天機器人? 也許你對一個新項目感興趣,或者公司需要一個,或者想去拉投資。 無論動機是什么,本文都將嘗試解釋如何創建一個簡單的基于規則的聊天機器人。
基于規則的聊天機器人
什么是基于規則的聊天機器人?它是一種基于特定規則來回答人類給出的文本的聊天機器人。由于它基于強加的規則所以這個聊天機器人生成的響應幾乎是準確的;但是,如果我們收到與規則不匹配的查詢,聊天機器人將不會回答。與它相對的另一個版本是基于模型的聊天機器人,它通過機器學習模型來回答給定的查詢。(二者的區別就是基于規則的需要我們指定每一條規則,而且基于模型的會通過訓練模型自動生成規則,還記得我們上一篇的”機器學習介紹“嗎,"機器學習為系統提供無需明確編程就能根據經驗自動學習和改進的能力。")
基于規則的聊天機器人可能基于人類給出的規則,但這并不意味著我們不使用數據集。聊天機器人的主要目標仍然是自動化人類提出的問題,所以我們還是需要數據來制定特定的規則。
在本文中,我們將利用余弦相似距離作為基礎開發基于規則的聊天機器人。余弦相似度是向量(特別是內積空間的非零向量)之間的相似度度量,常用于度量兩個文本之間的相似度。
我們將使用余弦相似度創建一個聊天機器人,通過對比查詢與我們開發的語料庫之間的相似性來回答查詢提出的問題。這也是我們最初需要開發我們的語料庫的原因。
創建語料庫
對于這個聊天機器人示例,我想創建一個聊天機器人來回答有關貓的所有問題。 為了收集關于貓的數據,我會從網上抓取它。
- import bs4 as bs
- import urllib.request#Open the cat web data page
- cat_data = urllib.request.urlopen('https://simple.wikipedia.org/wiki/Cat').read()
- #Find all the paragraph html from the web page
- cat_data_paragraphs = bs.BeautifulSoup(cat_data,'lxml').find_all('p')
- #Creating the corpus of all the web page paragraphs
- cat_text = ''
- #Creating lower text corpus of cat paragraphs
- for p in cat_data_paragraphs:
- cat_text += p.text.lower()
- print(cat_text)

使用上面的代碼,會得到來自wikipedia頁面的段落集合。 接下來,需要清理文本以去除括號編號和空格等無用的文本。
- import re
- cat_text = re.sub(r'\s+', ' ',re.sub(r'\[[0-9]*\]', ' ', cat_text))
上述代碼將從語料庫中刪除括號號。我特意沒有去掉這些符號和標點符號,因為當與聊天機器人進行對話時,這樣聽起來會很自然。
最后,我將根據之前創建的語料庫創建一個句子列表。
- import nltk
- cat_sentences = nltk.sent_tokenize(cat_text)

我們的規則很簡單:將聊天機器人的查詢文本與句子列表中的每一個文本之間的進行余弦相似性的度量,哪個結果產生的相似度最接近(最高余弦相似度)那么它就是我們的聊天機器人的答案。
創建一個聊天機器人
我們上面的語料庫仍然是文本形式,余弦相似度不接受文本數據;所以需要將語料庫轉換成數字向量。通常的做法是將文本轉換為詞袋(單詞計數)或使用TF-IDF方法(頻率概率)。在我們的例子中,我們將使用TF-IDF。
我將創建一個函數,它接收查詢文本,并根據以下代碼中的余弦相似性給出一個輸出。讓我們看一下代碼。
- from sklearn.metrics.pairwise import cosine_similarity
- from sklearn.feature_extraction.text import TfidfVectorizer
- def chatbot_answer(user_query):
- #Append the query to the sentences list
- cat_sentences.append(user_query)
- #Create the sentences vector based on the list
- vectorizer = TfidfVectorizer()
- sentences_vectors = vectorizer.fit_transform(cat_sentences)
- #Measure the cosine similarity and take the second closest index because the first index is the user query
- vector_values = cosine_similarity(sentences_vectors[-1], sentences_vectors)
- answer = cat_sentences[vector_values.argsort()[0][-2]]
- #Final check to make sure there are result present. If all the result are 0, means the text input by us are not captured in the corpus
- input_check = vector_values.flatten()
- input_check.sort()
- if input_check[-2] == 0:
- return "Please Try again"
- else:
- return answer
我們可以把上面的函數使用下面的流程圖進行表示:
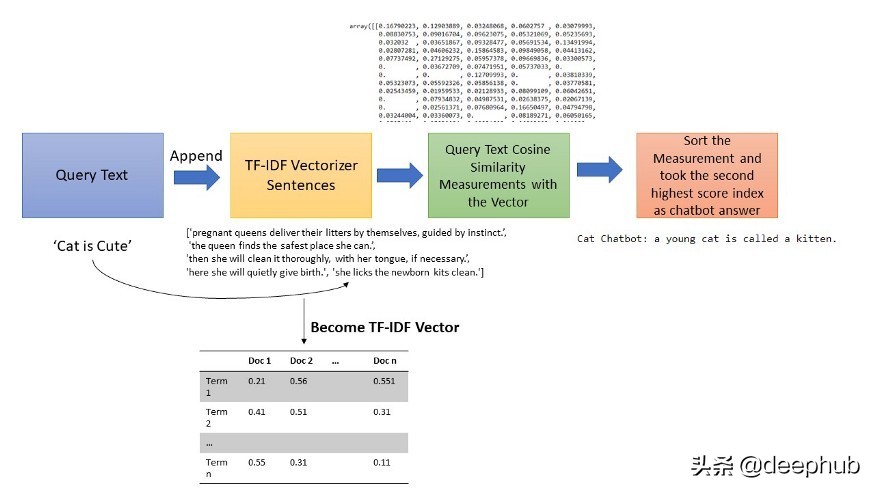
最后,使用以下代碼創建一個簡單的回答交互。
- print("Hello, I am the Cat Chatbot. What is your meow questions?:")
- while(True):
- query = input().lower()
- if query not in ['bye', 'good bye', 'take care']:
- print("Cat Chatbot: ", end="")
- print(chatbot_answer(query))
- cat_sentences.remove(query)
- else:
- print("See You Again")
- break
上面的腳本將接收查詢,并通過我們之前開發的聊天機器人處理它們。

從上面的圖片中看到的,結果還是可以接受的,但有也有些奇怪的回答。但是我們要想到,目前只從一個數據源中得到的結果,并且也沒有做任何的優化。如果我們用額外的數據集和規則來改進它,它肯定會更好地回答問題。
總結
聊天機器人項目是一個令人興奮的數據科學項目,因為它在許多領域都有幫助。在本文中,我們使用從網頁中獲取的數據,利用余弦相似度和TF-IDF,用Python創建了一個簡單的聊天機器人項目,真正的將我們的1個億的項目落地。其實這里面還有很多的改進:
- 向量化的選擇,除了TF-IDF還可以使用word2vec,甚至使用預訓練的bert提取詞向量。
- 回答環節,其實就是通過某種特定的算法或者規則從我們的語料庫中搜索最匹配的答案,本文中使用的相似度TOP1的方法其實就是一個最簡單的類greedsearch的方法,對于答案結果的優化還可以使用類beamsearch 的算法提取回答的匹配項。
- 等等很多
在端到端的深度學習興起之前,很多的聊天機器人都是這樣基于規則來運行的并且也有很多落地案例,如果你想快速的做一個POC展示,這種基于規則方法還是非常有用的。

















