













OpenAI用GPT-3與小學生比數學!小模型性能翻倍追平1750億大模型
還記得上小學時,被「口算天天練」里面的應用題繞暈的陰影嗎?
來,試一道!
「小明每半小時喝一瓶水。一個普通的數獨難題要花他45分鐘。一個極難的數獨需要4倍的時間。做一道極難的數獨那段時間他喝了多少瓶水?」
不算難吧。
但這回,OpenAI要拿這些應用題去考考自家的當家模型,GPT-3。
成績很喜人啊!
新方法可以解決小學數學問題,60億參數的GPT-3采用新方法,準確率直接翻倍,甚至追平了1750億參數,采用微調方法的GPT-3模型。
更重要的是,一個9-12歲的小孩子在測試中得分為60分,而采用新方法的GPT-3在同樣的問題上可以拿到55分,已經達到了人類小學生90%左右的水平!
偏科的GPT-3:重文輕理
OpenAI的GPT-3以1750億參數的「大」這一特點,讓人印象頗深。
GPT-3「文采出眾」,上知天文,下知地理。模仿名家的寫作風格,展示一下廣博的知識,這都不在話下。
然而,GPT-3這種「大」模型卻是典型的偏科生,擅長文,但不擅理。
要是指望他們能夠完成精確的多步推理,比如,解決小學數學應用題,那還是別指望了。
原因何在?
其實,問題就在于,盡管GPT-3可以模仿正確解決方法的規律,但它經常會在邏輯上產生嚴重錯誤。
所以,人類要想教會大語言模型理解復雜的邏輯,就必須得讓模型學會識別它們的錯誤,并仔細選擇他們的解題步驟。
傳統方法:微調
目前,要想讓大模型掌握一個領域,最常用的方法就是用大模型在指定領域微調。
微調通過更新模型參數進行,最小化所有訓練token的交叉熵損失。顯而易見,1750億參數的模型性能要優于其他更小的模型。
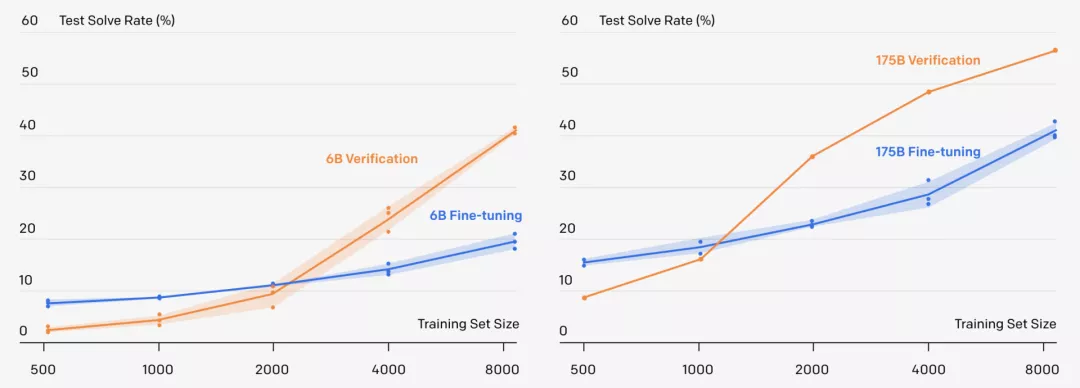
在對不同規模的訓練集進行微調后,各種GPT-3模型的測試性能
假設在對數線性趨勢下,使用完整的GSM8K訓練集時,需要一個具有10^16(10萬億)個參數的模型來達到80%的解決率。
然而,模型的性能并不遵循對數線性趨勢,對于175B模型來說,則需要至少增加兩個數量級的訓練數據才能達到80%的解決率。
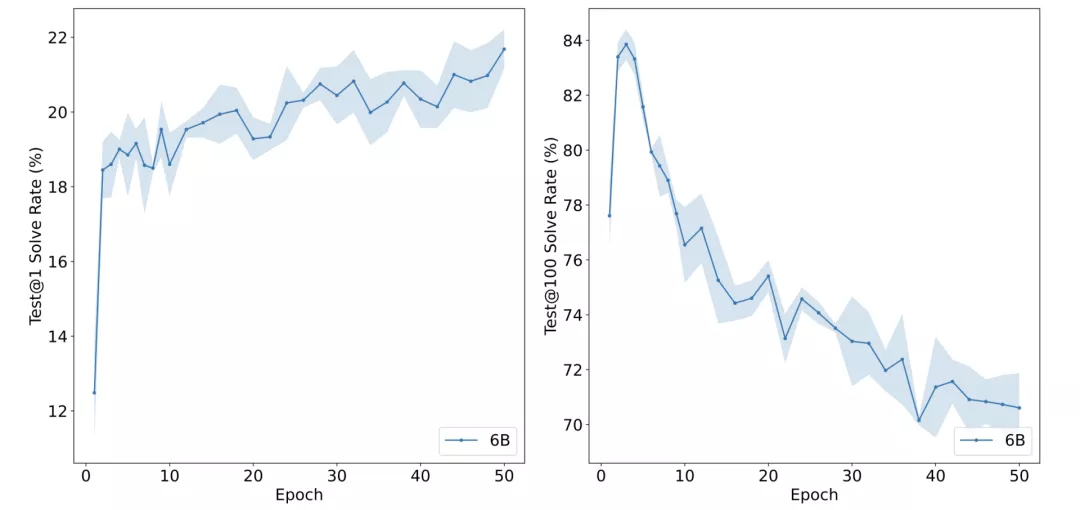
在GSM8K訓練集上對6B模型進行微調后,當模型被允許進行1次猜測(左)或100次猜測(右)時,回答的正確率
其中,test@N來表示在允許模型對每個問題進行N次單獨猜測時,至少正確解決一次問題的百分比。
test@1的性能近似單調遞增,而對于test@100來說,當增加epoch的數量時,其性能比test@1的性能下降得更快。
選擇一個具有良好覆蓋率的模型是成功訓練驗證器的關鍵。從經驗上看,test@100的性能在最初的幾個epoch內達到了頂峰。
此外,在輸出最終答案之前,讓模型生成完整的自然語言解決方案是很重要的。如果把6B模型調整為直接輸出最終答案,而不經過任何中間步驟,性能就會從20.6%急劇下降到5.2%。
讓AI擁有「邏輯」的法寶:「驗證器」
很明顯,「微調」是無法讓GPT-3學會邏輯推理的。
那這次,OpenAI是如何讓GPT-3擁有「邏輯」的呢?
答案就是一個叫「驗證器」的東西。
訓練這個驗證器(verifier),就是為了使用驗證器從許多候選的解決方案中選擇出最佳方案。
同時,為了評估「驗證器」的表現,OpenAI收集了全新的「GSM8K數據集」并將其開源以方便研究。

論文地址:https://arxiv.org/pdf/2110.14168.pdf
GSM8K數據集地址:https://github.com/openai/grade-school-math
那到底「驗證器」是怎么工作的呢?
驗證器:吃一塹,長一智
驗證器(verifier)可以判斷模型生成的解決方案正不正確,所以在測試時,驗證器會以問題和候選解答為輸入,輸出每個解答正確的概率。
驗證器(verifier)訓練時,只訓練解決方案是否達到正確的最終答案,將其標記為正確或不正確。但是在實踐中,一些解決方案會使用有缺陷的推理得出正確的最終答案,從而導致誤報。
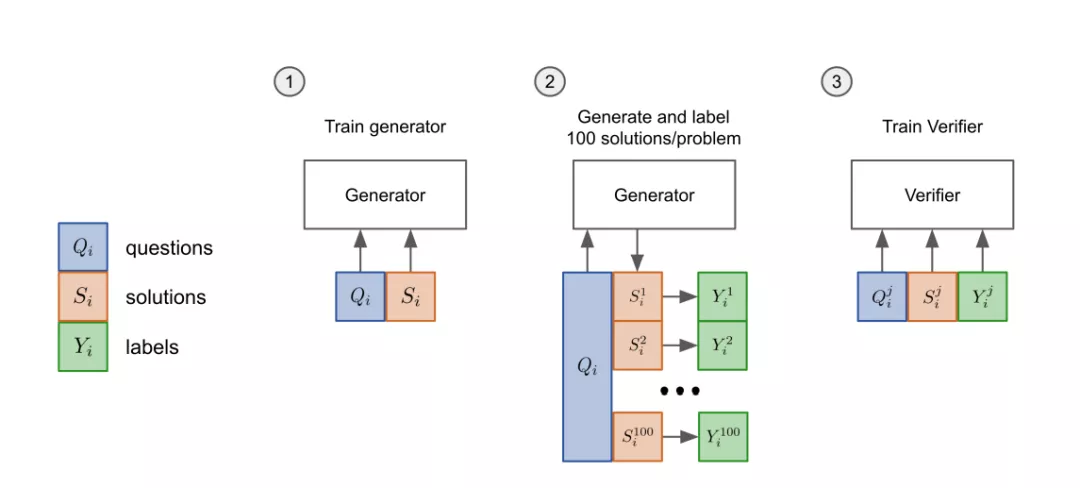
驗證器具體訓練方法分為「三步走」:
- 先把模型的「生成器」在訓練集上進行2個epoch的微調。
- 從生成器中為每個訓練問題抽取100個解答,并將每個解答標記為正確或不正確。
- 在數據集上,驗證器再訓練單個epoch。
「生成器」只訓練2個epoch是因為2個epoch的訓練就足夠學習這個領域的基本技能了。如果采用更長時間的訓練,生成的解決方案會過度擬合。
測試時,解決一個新問題,首先要生成100個候選解決方案,然后由「驗證器」打分,排名最高的解決方案會被最后選中。
GSM8K數據集
有了新的解決方案,再來看看這次考試的「試卷」。
GSM8K由8500個高質量、高多樣性、中等難度的小學數學問題組成。當然了。OpenAI表示,對于一個中學生來說,這些問題就都不是問題了。
數據集中的每個問題都需要計算2到8個步驟來得出最終答案,涉及到「加減乘除」四則運算。
- 高質量:GSM8K中的問題都是人工設計的,避免了錯誤問題的出現。
- 高多樣性:GSM8K中的問題都被設計得相對獨特,避免了來自相同語言模板或僅在表面細節上有差異的問題。
- 中等難度:GSM8K中的問題分布對大型SOTA語言模型是有挑戰的,但又不是完全難以解決的。這些問題不需要超出早期代數水平的概念,而且絕大多數問題都可以在不明確定義變量的情況下得到解決。
- 自然語言解決方案:GSM8K中的解決方案是以自然語言而不是純數學表達式的形式編寫的。模型由此生成的解決方案也可以更容易被人理解。此外,OpenAI也期望它能闡明大型語言模型內部獨白的特性。

GSM8K中的三個問題示例,紅色為計算的注釋
「微調」VS 「驗證」
在GSM8K數據集上,OpenAI測試了新方法「驗證」(verification)和基線方法「微調」(fine-tuning)生成的答案。
結果非常優秀啊!
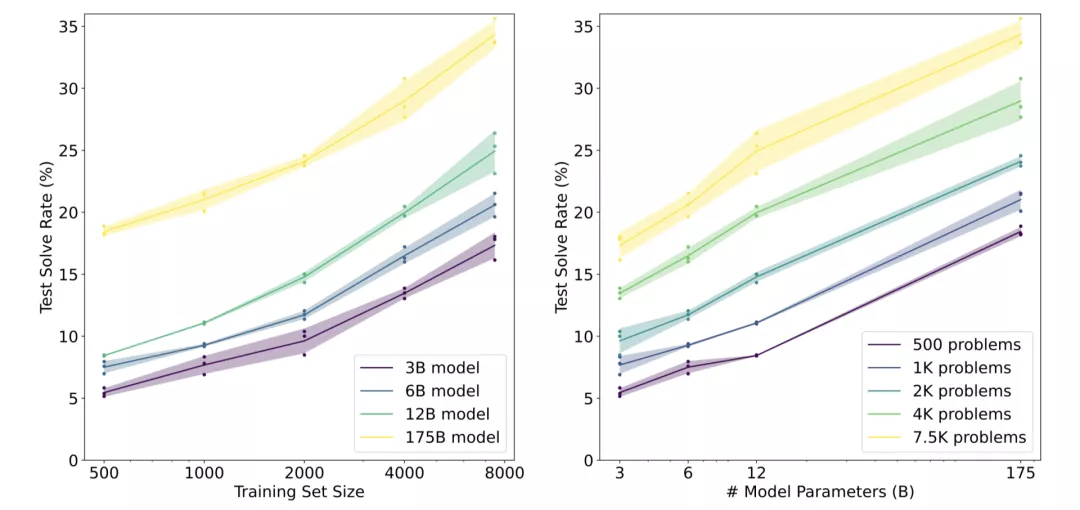
在完整的訓練集上,采用「驗證」方法的60億參數模型,會略微優于采用「微調」的1750億參數模型,性能提升大約相當于模型規模整整增加30倍!
但大模型也不是一無是處,采用「驗證」的1750億參數模型還是比采用「驗證」方法的60億參數模型學習速度更快,只需要更少的訓練問題,就能超過微調基線。
OpenAI發現,只要數據集足夠大,大模型就能從「驗證」中獲得強大的性能提升。
但是,對于太小的數據集,驗證器會通過記憶訓練集中的答案而過度擬合,而不是學習基本的數學推理這種更有用的屬性。
所以,根據目前的結果進行推斷,「驗證」似乎可以更有效地擴展到額外的數據。
舉個「栗子」
理論都講完了,不如來一波實操,對比一下新方法「驗證」(verification)和基線方法「微調」(fine-tuning)生成的答案。
問題:「Richard,Jerry和Robert三個人分60個櫻桃。如果Robert有30個櫻桃,比Richard多10個,那么Robert比Jerry多幾個?」
175B Verification:正確

175B Fine-tuning:錯誤

6B Verification:正確

6B Fine-tuning:錯誤

可見,新方法「驗證」(verification)比基線方法「微調」(fine-tuning)在回答數學應用題上有了很大的提升。
不過,「驗證」的方法也不是十全十美的,也有它做不對的問題。畢竟還要考慮6B小模型的局限性。
還記得最開始的那個問題么?
「John每半小時喝一瓶水。一個普通的數獨難題要花他45分鐘。一個極難的數獨需要4倍的時間。做一道極難的數獨那段時間他喝了多少瓶水?」
175B Verification:正確

175B Fine-tuning:錯誤

6B Verification:錯誤

6B Fine-tuning:錯誤

當然,如果問題再難一點兒,語言模型們就集體躺平了。
比如下面這個:
「Debra正在監測一個蜂巢,看一天中有多少蜜蜂來來往往。她看到30只蜜蜂在前6個小時內離開蜂巢,然后她看到1/2的蜜蜂在接下來的6個小時內返回。她看到兩倍于第一次離開蜂巢的蜜蜂在接下來的6個小時內飛出蜂巢。然后,之前離開的每只蜜蜂,如果還沒有回來,在接下來的6個小時內都會回到蜂巢。在這一天的最后6個小時里,Debra看到有多少只蜜蜂回到了蜂巢?」
175B Verification:錯誤

175B Fine-tuning:錯誤

6B Verification:錯誤

6B Fine-tuning:錯誤

看來,AI做數學題還是道阻且長啊。
你要不要也來嘗試一下?


























