













Meta復刻GPT-3“背刺”OpenAI,完整模型權重及訓練代碼全公開
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
千億級參數AI大模型,竟然真的能獲取代碼了?!
一覺醒來,AI圈發生了一件轟動的事情——
Meta AI開放了一個“重達”1750億參數的大語言模型OPT-175B,不僅參數比GPT-3的3750億更少,效果還完全不輸GPT-3——
這意味著AI科學家們,終于可以“撬開”像GPT-3這樣的大模型,看看里面到底有些什么秘密了。
之前GPT-3雖然效果驚艷但不夠開放,源代碼獨家授權給了微軟,連馬斯克都批評過OpenAI不夠open。
雖然論文就在那里,想要在此之上做進一步研究的話就得先復現一個出來再說。
而這一次,Meta從完整模型到訓練代碼、部署代碼全部開放。
有人甚至在官宣之前就摸到還沒上傳好的GitHub倉庫去蹲點了。
還有人艾特OpenAI試圖“引戰”:

那么,Meta大模型有何特點、如何做到綠色低能耗,又為何要對外開放?一起來看看。
用16塊V100就能跑起來
OPT全稱Open Pre-trained Transformer Language Models,即“開放的預訓練Transformer語言模型”。
相比GPT,名字直接把Generative換成了Open,可以說是非常內涵了。(手動狗頭)
在論文中,Meta AI也不避諱宣稱OPT-175B就是對標GPT-3,還暗示一波自己更環保:

Meta AI對此解釋稱,OPT就是奔著開放代碼去的,為了讓更多人研究大模型,環境配置肯定是越經濟越好。
這不,運行時產生的碳足跡連GPT-3的1/7都不到,屬實省能又高效。
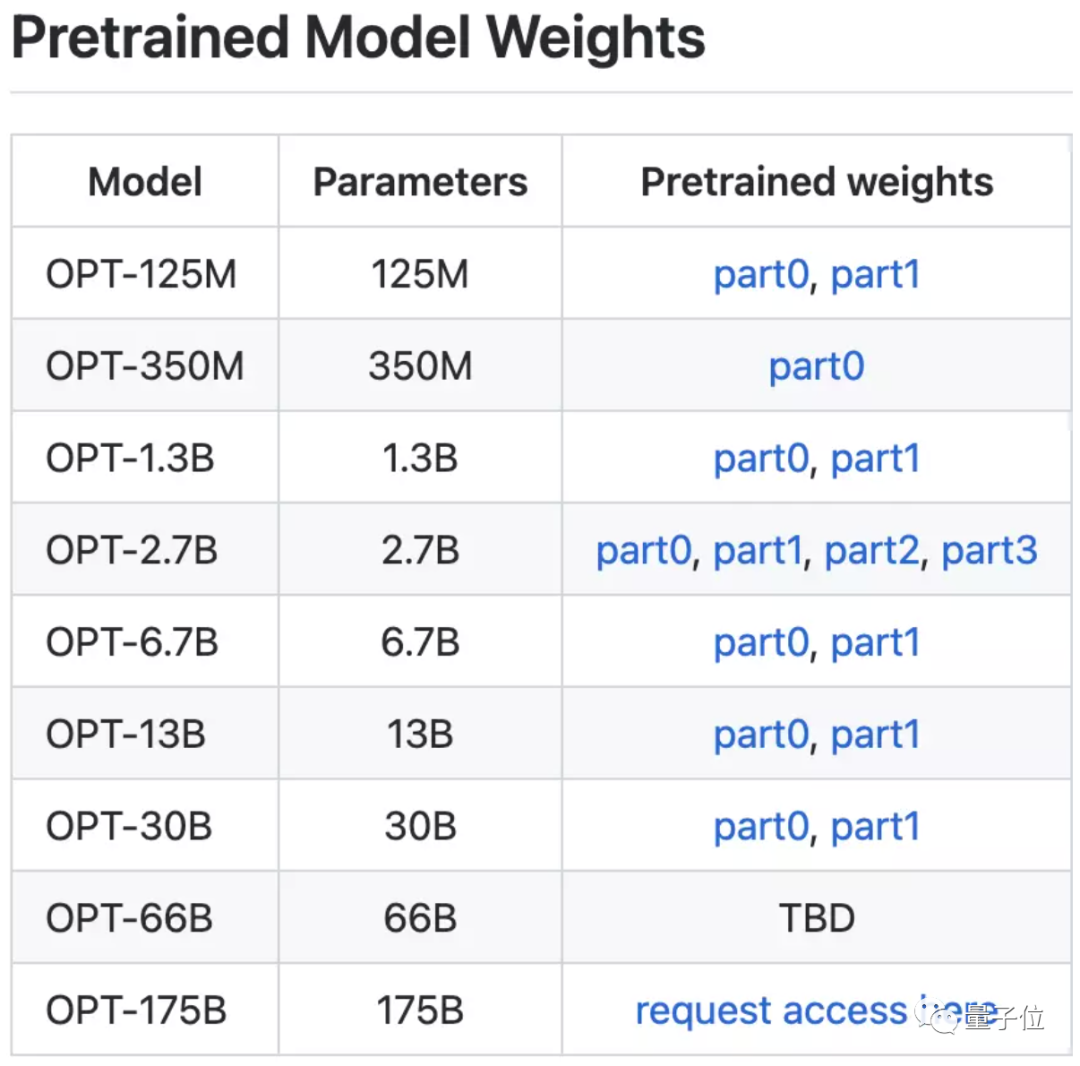
為了方便研究人員“量力而行”,Meta AI搞出了各種大小的OPT模型,從125M參數到1750億參數的不同大小模型都有。
其中,660億參數的模型還在制作中,馬上也會和大伙兒見面:
所以,最大的OPT-175B模型究竟有多高效,又是怎么做到的?
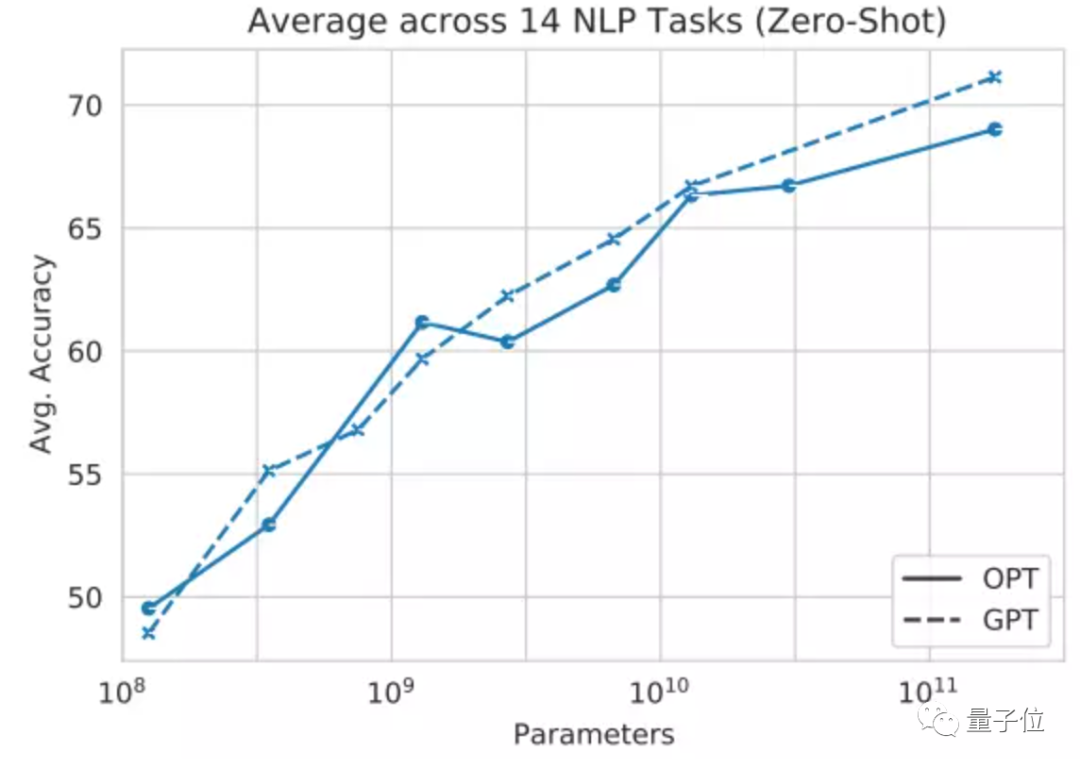
性能方面,Meta AI針對OPT-175B和GPT-3,用14個NLP任務進行了測試。
結果表明,無論是零樣本學習(zero-shot)還是多樣本學習(Multi-shot),OPT在這些任務上的平均精度都與GPT-3相差不大。其中虛線為GPT,實線為OPT:
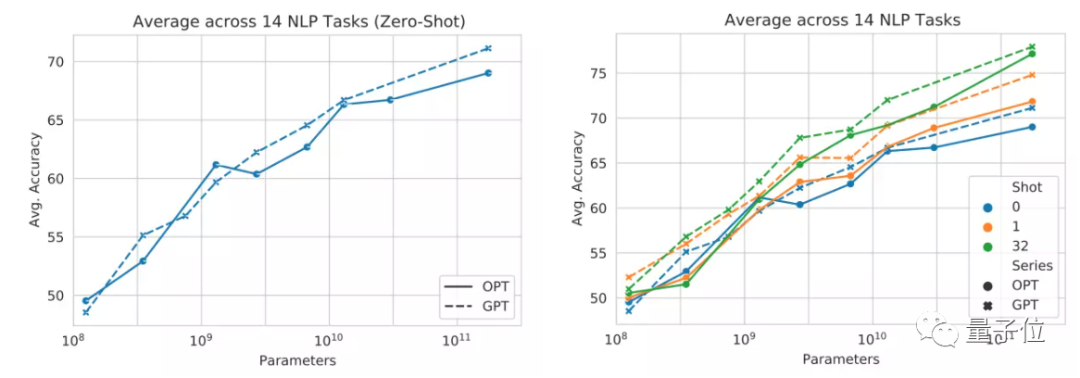
△左為零樣本學習,右為多樣本學習
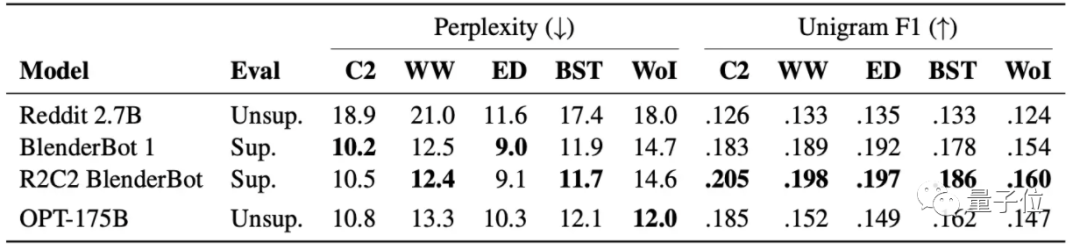
再看具體任務。在對話任務中,采用無監督學習的方法訓練OPT-175B,效果和監督學習訓練的幾類模型相近:
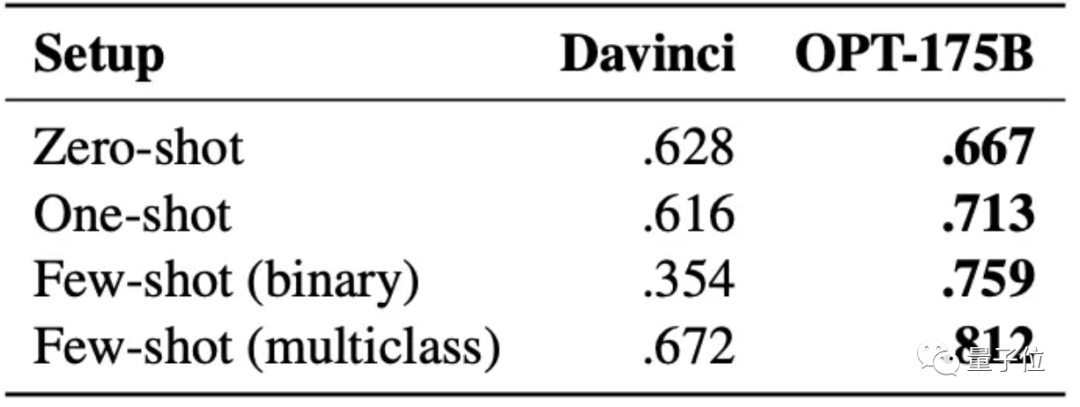
仇恨言論檢測任務上的效果,更是完全超過Davinci版本的GPT-3模型(在GPT-3的四個版本中是效果最好的):
訓練硬件方面,Meta AI用了992塊英偉達A100 GPU(80GB)訓練OPT,平均每塊GPU的計算效率最高能達到147 TFLOP/s。
這個效率,甚至比英偉達自家研究人員用起來還高,大約超過17%左右。
Meta AI透露稱,一方面是采用了自家推出的一款名叫FSDP(Fully Sharded Data Parallel)的GPU內存節省工具,使得大規模訓練的速度比傳統方法快上5倍左右;
另一方面他們也借鑒了英偉達Megatron-LM模型的張量并行方法,將一個運算分布到多個處理器上同時進行。
甚至Meta AI表示,最低只需要16塊英偉達V100 GPU,就能訓練并部署OPT-175B模型。

已經有網友迫不及待地想要一試了:
當然,Meta AI也不避諱談及OPT-175B大模型面臨的一些問題,例如更容易生成“毒性語言”(例如使用有攻擊性的詞匯、語言歧視等):
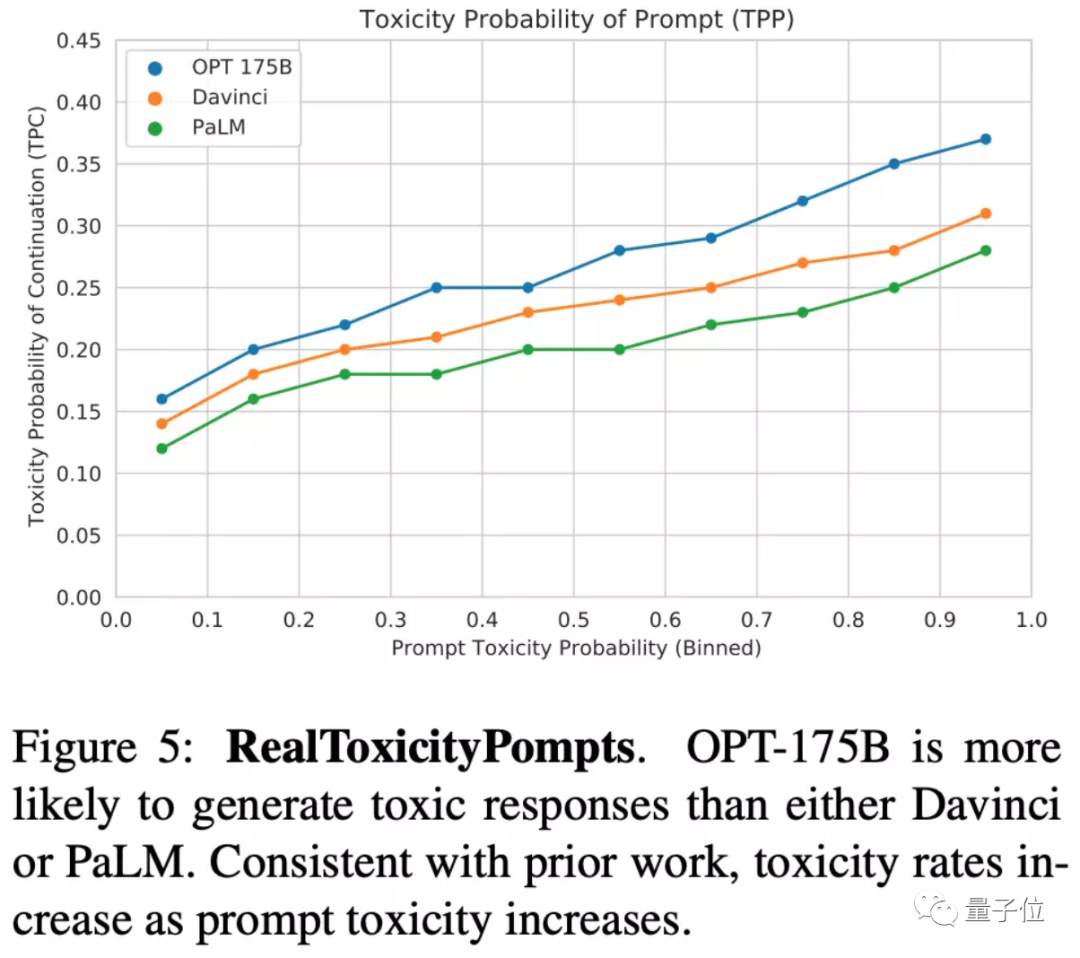
研究人員表示,希望能在開放后,有更多人參與進來研究,并真正解決這些問題。
手把手教你復刻GPT-3
上面提到,這一次的OPT模型系列,300億參數及以下的版本都是可以直接下載,660億版還在路上。
只有完整的1750億版需要額外填寫一張申請表,包括工作單位、用途、相關發表工作等問題。
訓練和部署的代碼工具包metaseq發布在GitHub,并配有使用教程和文檔。
作為著名的fairseq工具包的一個分支,metaseq專注于1750億規模大模型,刪除了訓練和使用大模型不需要的部分。

還有不少開發者特別看重一個與模型和代碼同時發布的“隱藏寶藏”——開發日志。
里面詳細記錄了Meta團隊在開發大模型過程中遇到的問題、解決的辦法和決策的依據。


為自Pytorch誕生之前就存在的一系列機器學習研究中的痛點和困惑提供了大廠解法的一手資料。

如此的開放力度可以說是史無前例了,自然收到了不少贊美。
比如同樣在做開源大模型項目的HuggingFace首席科學家Thomas Wolf。

不過針對1750億參數版需要申請一事,還是有人表示懷疑。
我不是學者或從業者,他們會接受我的申請嗎?
也有開發者建議Meta像OpenAI一樣提供一些Demo,如果大家看到效果會更愿意參與研究改進,不然的話光是搭建開發環境就挺勸退的。
斯坦福大學基礎模型研究中心主任、副教授Percy Liang對此發表了觀點,將大模型的開放程度總結成4個層次,更高層次的開放能讓研究者專注于更深的問題。

第一層論文開放,證明一些設想的可行性,并提供構建思路。
第二層API開放,允許研究人員探索和評估現有模型的能力(如推理能力)和限制(如偏見)
第三層模型權重開放和訓練數據開放。允許研究人員逐步改進現有模型,開發更深入的可解釋性技術和更有效的微調方法,讓研究人員更好地理解訓練數據在模型行為中的作用。
第四層計算能力開放,允許研究人員嘗試新的體系結構、訓練目標和過程、進行數據融合,并在不同的領域開發全新的模型。
Percy Liang認為更高層次的開放同時也會帶來更多風險。
也許是時候制定相關的社區規范了?
One More Thing
Meta這次論文的的共同一作有三人,其中Susan Zhang加入Meta之前正是來自OpenAI。

不過在OpenAI期間她并沒有負責GPT-3的開發,而是參與了玩Dota的OpenAI Five強化學習項目,以及多模態大模型的研究。
項目地址:
https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
論文地址:
https://arxiv.org/abs/2205.01068



























