盤點四種使用Python批量合并同一文件夾內所有子文件夾下的Excel文件內所有Sheet數據
一、前言
大家好,我是Python進階者。前一陣子給大家分享了Python自動化文章:手把手教你利用Python輕松拆分Excel為多個CSV文件,手把手教你4種方法用Python批量實現多Excel多Sheet合并,而后在Python進階交流群里邊有個叫【扮貓】的粉絲遇到一個問題,她有很多個Excel表格,而且多個excel里多個sheet,現在需要對這些Excel文件進行合并。
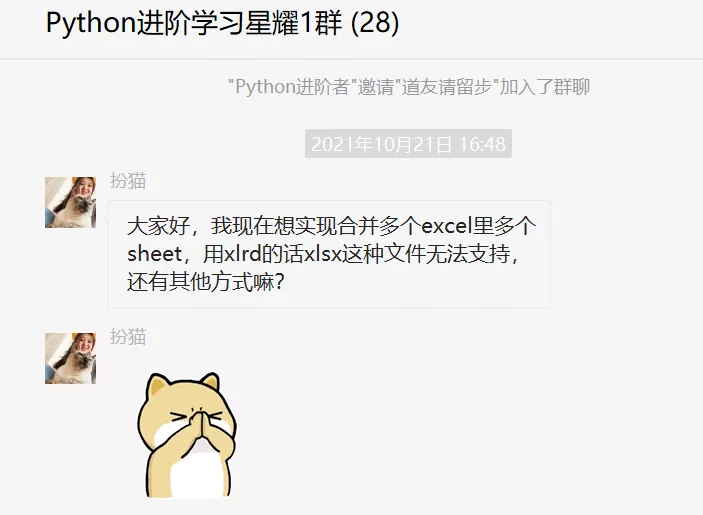
用上面鏈接對應的方法進行合并,發現只能夠合并Sheet,其他的就合并不了,這確實是個問題。
誠然,一個一個打開復制粘貼固然可行,但是該方法費時費力,還容易出錯,幾個文件還可以手動處理,要是幾十個甚至上百個,你就抓瞎了,不過這問題對Python來說,so easy,一起來看看吧!
二、項目目標
用Python實現多Excel、多Sheet的合并處理,針對現實中的切確需求,使用Python批量合并同一文件夾內所有子文件夾下的Excel文件內所有Sheet數據,這個需求在現實生活中還是挺常見的,所有比較實用。
三、項目準備
軟件:PyCharm
需要的庫:pandas,os,glob
四、項目分析
1)如何選擇要合并的Excel文件?
利用os和glob,獲取所有要合并的Excel文件。
2)如何選擇要合并的Sheet?
利用pandas庫進行Excel讀取,獲取要合并的Sheet名。
3)如何合并?
利用pandas庫,對所有Sheet名逐一循環打開,通過concat()函數進行數據追加合并即可。
4)如何保存文件?
利用to_excel保存數據,得到最終合并后的目標文件。
五、項目實現
這里提供4種方法給大家,一個比一個簡潔,其中后面三個方法都是來自【小小明大佬】提供的,確實太強了。
1、方法一
這個方法是來自【王寧】大佬的分享,代碼確實有點多,不過也是手把手教程,非常詳細,也有注釋,詳情可以戳這篇文章:文科生自學Python-批量匯總同一路徑內所有Excel文件內所有Sheet數據-基礎知識1.41,代碼如下:
- # -*- coding: utf-8 -*-
- import pandas as pd
- import datetime
- import os
- # define a starting point of time
- start = datetime.datetime.now()
- def Set_Work_Path(x):
- try:
- os.chdir(x)
- route = os.getcwd()
- print(route)
- return route
- except Exception:
- print("No Result")
- work_path = r"E:\\PythonCrawler\\python_crawler-master\\MergeExcelSheet\\file\\"
- Set_Work_Path(work_path)
- # define a function to get all the xlsx file names after deleting old file if there.
- def Get_Dedicated_4Letter_File_List(x):
- path = os.getcwd()
- old_name = path + os.sep + "匯總數據" + ".xlsx" # dim a txt name
- if os.path.exists(old_name):
- os.remove(old_name)
- files = os.listdir(path) # print(files) #check all files name in the path
- current_list = []
- for i in range(0, len(files), 1):
- try:
- if files[i][-4:] == x and files[i][:4] != "匯總數據":
- current_list.append(files[i])
- except Exception:
- pass
- return current_list
- Current_Excel_list = Get_Dedicated_4Letter_File_List("xlsx")
- print(Current_Excel_list)
- # define a function to read all sheets one by one in excel file
- def Get_All_Sheets_Excel(x):
- file = pd.ExcelFile(x)
- list_sht_name = file.sheet_names # get list of sheets' names
- print(list_sht_name)
- list_sht_data = [] # get all sheet data sets into a list
- for i in range(0, len(list_sht_name), 1):
- list_sht_data.append(pd.read_excel(x, header=0, sheet_name=list_sht_name[i], index_col=None))
- # merge all data sets together
- df = pd.concat(list_sht_data)
- # delete blank data
- df.dropna(axis=0, how="all", inplace=True)
- print(df)
- return df
- # define a list to get all data from sheets from different excel files
- data_list = []
- for i in range(0, len(Current_Excel_list), 1):
- # print(Current_Excel_list[i])
- data_list.append(Get_All_Sheets_Excel(Current_Excel_list[i]))
- data = pd.concat(data_list)
- data.dropna(axis=0, how="all", inplace=True)
- print(data)
- # save the data into excel file
- writer = pd.ExcelWriter("王寧大佬的匯總數據.xlsx")
- data.to_excel(writer, encoding="utf_8_sig", sheet_name="DATA", index=False)
- # get the target pivot datasets
- writer.save()
- end = datetime.datetime.now()
- run_time = round((end-start).total_seconds()/60, 2)
- show = "程序運行消耗時間為: %s 分鐘" % run_time+",搞定!"
- print(show)
上面這個代碼對原始數據要求比較苛刻,前提條件:所有數據都是規范的數據源且字段名和數據結構是一樣的。這樣看來,還是有些受限的。不過不要慌,接下來【小小明大佬】的這三個方法,就沒有這個限制,下面一起來看看吧!
2、方法二
下面這個代碼是基于【小小明大佬】提供的單Sheet表合并代碼改進所得到的,關鍵點在于將sheet_name=None這個參數帶上,代表獲取Excel文件中的所有sheet表,其返回的是一個字典,所有在后面遍歷的時候,是以字典的形式進行取值的,之后在15行的地方,需要注意使用的是extend()方法進行追加,如果使用append()方法,得到的就只有最后一個表格的合并結果,這個坑小編親自踩過,感興趣的小伙伴也可以踩下坑。
- # -*- coding: utf-8 -*-
- import os
- import pandas as pd
- result = []
- path = r"E:\\PythonCrawler\\python_crawler-master\\MergeExcelSheet\\testfile\\file"
- for root, dirs, files in os.walk(path, topdown=False):
- for name in files:
- if name.endswith(".xls") or name.endswith(".xlsx"):
- df = pd.read_excel(os.path.join(root, name), sheet_name=None)
- result.append(df)
- data_list = []
- for data in result:
- # print(data.values())
- data_list.extend(data.values()) # 注意這里是extend()函數而不是append()函數
- df = pd.concat(data_list)
- df.to_excel("testfile所有表合并.xlsx", index=False)
- print("合并完成!")
3、方法三
下面這個代碼是【小小明大佬】手擼的一個代碼,使用了列表append()方法,效率雖說會低一些,但是處理上百上千個文件,仍然不在話下。
需要注意的是代碼中的第6行和第7行,獲取文件路徑,其中**代表的是文件夾下的子文件遞歸。另外就是.xls*了,這個是正則寫法,表示的是既可以處理xls格式,也可以處理xlsx格式的Excel文件,真是妙哉!
- # -*- coding: utf-8 -*-
- import glob
- import pandas as pd
- path = "E:\\PythonCrawler\\python_crawler-master\\MergeExcelSheet\\file\\"
- data = []
- for excel_file in glob.glob(f'{path}/**/[!~]*.xls*'):
- # for excel_file in glob.glob(f'{path}/[!~]*.xlsx'):
- excel = pd.ExcelFile(excel_file)
- for sheet_name in excel.sheet_names:
- df = excel.parse(sheet_name)
- data.append(df)
- # print(data)
- df = pd.concat(data, ignore_index=True)
- df.to_excel("小小明提供的代碼(合并多表)--glob和pandas庫列表append方法--所有表合并.xlsx", index=False)
- print("合并完成!")
4、方法四
下面這個代碼是【小小明大佬】手擼的另外一個代碼,使用了sheet_name=None和列表extend()方法,將sheet_name=None這個參數帶上,代表獲取Excel文件中的所有sheet表,其返回的是一個字典,所有在后面遍歷的時候,是以字典的形式進行取值的,效率比前面的方法都要高一些。
需要注意的是代碼中的第6行和第7行,獲取文件路徑,其中**代表的是文件夾下的子文件遞歸。另外就是.xls*了,這個是正則寫法,表示的是既可以處理xls格式,也可以處理xlsx格式的Excel文件,真是妙哉!
- # -*- coding: utf-8 -*-
- import glob
- import pandas as pd
- path = r"E:\PythonCrawler\python_crawler-master\MergeExcelSheet\file"
- data = []
- # for excel_file in glob.glob(f'{path}/**/[!~]*.xlsx'):
- for excel_file in glob.glob(f'{path}/[!~]*.xlsx'):
- dfs = pd.read_excel(excel_file, sheet_name=None).values()
- data.extend(dfs)
- # print(data)
- df = pd.concat(data, ignore_index=True)
- df.to_excel("小小明提供的代碼(合并多表)--glob和pandas庫列表extend方法--簡潔--所有表合并.xlsx", index=False)
- print("合并完成!")
六、效果展示
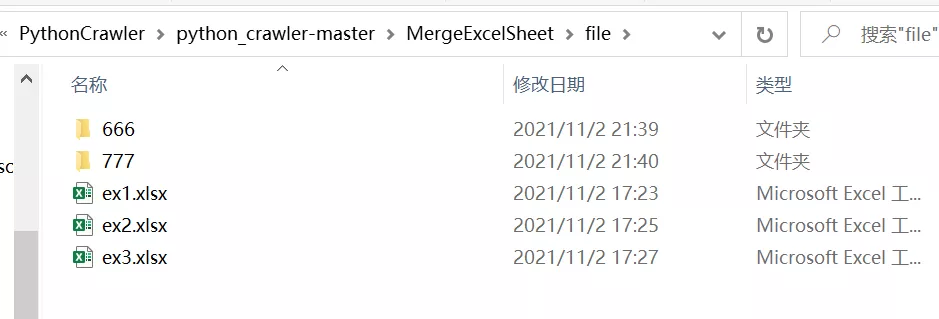
1、處理前Excel數據:
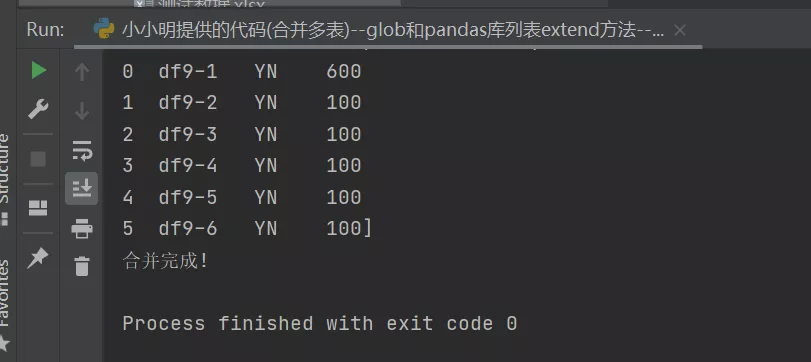
2、運行進度提示:
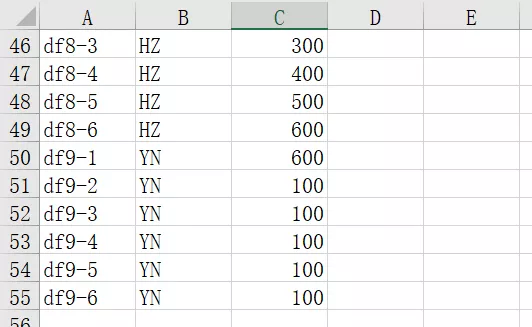
3、合并后的結果:
七、總結
本文從實際工作出發,基于Python編程,介紹了4種方法,實現批量合并同一文件夾內所有子文件夾下的Excel文件內所有Sheet數據,為大家減少了很多復制粘貼的麻煩,省時省力,還不容易出錯。代碼不多,循環追加有點繞,想想也就明白了,大家一起學習進步。