為什么說(shuō)MPP架構(gòu)與Hadoop架構(gòu)是一回事?
計(jì)算機(jī)領(lǐng)域的很多概念都存在一些傳播上的“謬誤”。
MPP這個(gè)概念就是其中之一。它的“謬誤”之處在于,明明叫做“Massively Parallel Processing(大規(guī)模并行處理)”,卻讓非常多的人拿它與大規(guī)模并行處理領(lǐng)域最著名的開(kāi)源框架Hadoop相關(guān)框架做對(duì)比,這實(shí)在是讓人困惑——難道Hadoop不是“大規(guī)模并行處理”架構(gòu)了?
很多人在對(duì)比兩者時(shí),其實(shí)并不知道MPP的含義究竟是什么、兩者的可比性到底在哪里。實(shí)際上,當(dāng)人們?cè)趯?duì)比兩者時(shí),與其說(shuō)是對(duì)比架構(gòu),不如說(shuō)是對(duì)比產(chǎn)品。雖然MPP的原意是“大規(guī)模并行處理”,但由于一些歷史原因,現(xiàn)在當(dāng)人們說(shuō)到MPP架構(gòu)時(shí),它們實(shí)際上指代的是“分布式數(shù)據(jù)庫(kù)”,而Hadoop架構(gòu)指的則是以Hadoop項(xiàng)目為基礎(chǔ)的一系列分布式計(jì)算和存儲(chǔ)框架。不過(guò)由于MPP的字面意思,現(xiàn)實(shí)中還是經(jīng)常有人糾結(jié)兩者到底有什么聯(lián)系和區(qū)別,兩者到底是不是同一個(gè)層面的概念。
這種概念上的含混不清之所以還在流傳,主要是因?yàn)椴欢夹g(shù)的人而喜歡這些概念的大有人在,所以也并不在意要去澄清概念。“既然分布式數(shù)據(jù)庫(kù)是MPP架構(gòu),那么MPP架構(gòu)就等于分布式數(shù)據(jù)庫(kù)應(yīng)該也沒(méi)什么問(wèn)題吧。”于是大家就都不在意了。
不過(guò),作為一個(gè)技術(shù)人員,還是應(yīng)該搞清楚兩種技術(shù)的本質(zhì)。本文旨在做一些概念上的澄清,并從技術(shù)角度論述兩者同宗同源且會(huì)在未來(lái)殊途同歸。
到底什么是MPP架構(gòu)?
MPP架構(gòu)與Hadoop架構(gòu)在理論基礎(chǔ)上幾乎是在講同一件事,即,把大規(guī)模數(shù)據(jù)的計(jì)算和存儲(chǔ)分布到不同的獨(dú)立的節(jié)點(diǎn)中去做。
有人可能會(huì)問(wèn):“既然如此,為什么人們不說(shuō)Hadoop是MPP(大規(guī)模并行處理)架構(gòu)呢?”
關(guān)于這個(gè)問(wèn)題嘛,請(qǐng)先問(wèn)是不是,再問(wèn)為什么。
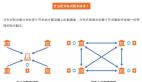
在GreenPlum的官方文檔中就寫(xiě)道:“Hadoop就是一種常見(jiàn)的MPP存儲(chǔ)與分析工具。Spark也是一種MPP架構(gòu)。”來(lái)看下面的圖,更能體會(huì)到兩者的相似性。
問(wèn):這是什么架構(gòu)?
答:MPP架構(gòu)。
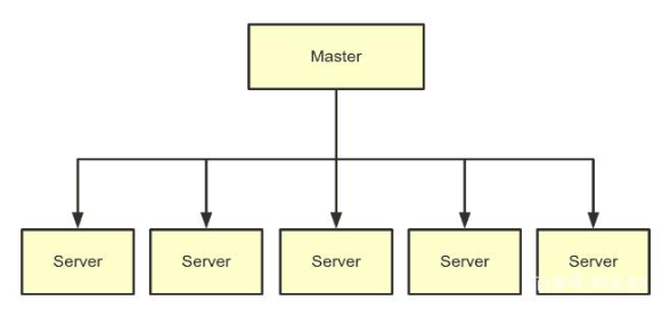
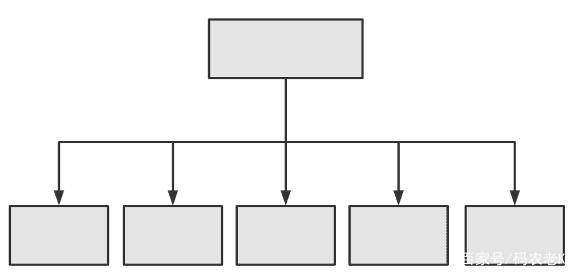
相信了解過(guò)MPP架構(gòu)的讀者對(duì)這幅圖不會(huì)陌生。也許在不同的分布式數(shù)據(jù)庫(kù)產(chǎn)品中,節(jié)點(diǎn)角色的名稱(chēng)會(huì)有差異,但總體而言都是一個(gè)主節(jié)點(diǎn)加上多個(gè)從節(jié)點(diǎn)的架構(gòu)。
但是,還可以有其他答案,比如MapReduce on Yarn:
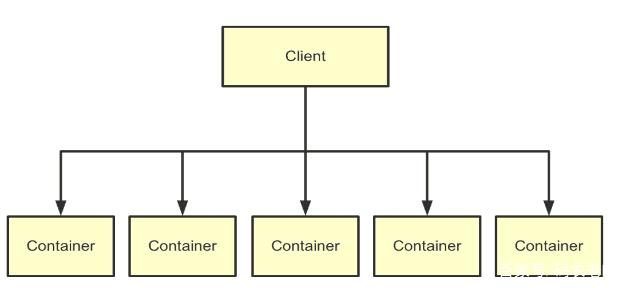
這幅圖或許大家有些陌生,但只不過(guò)是省略了資源調(diào)度的簡(jiǎn)化版MapReduce運(yùn)行時(shí)架構(gòu)罷了。
當(dāng)然,還可以有更多答案,如Spark:
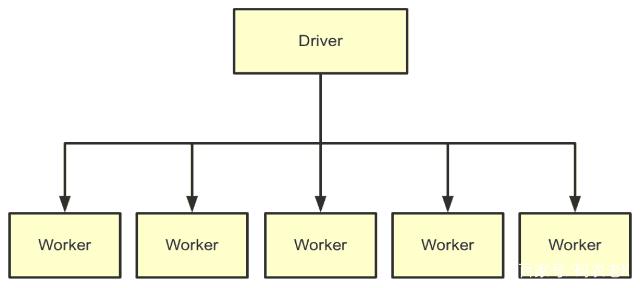
自然還可以是Flink:
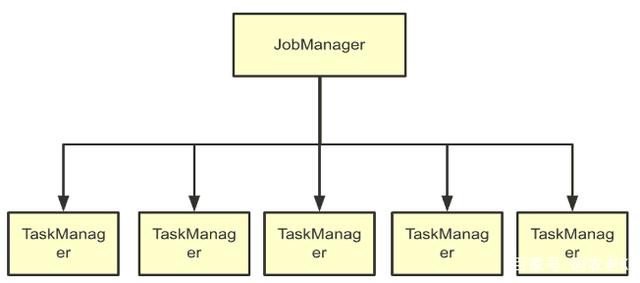
有人可能會(huì)說(shuō),雖然直觀上這些架構(gòu)長(zhǎng)得很像,但是MPP架構(gòu)中的Master所負(fù)責(zé)的事情是不是與其他框架不一樣?
那么,MPP架構(gòu)的Master做的什么事呢?它會(huì)接收SQL語(yǔ)句,解析它并生成執(zhí)行計(jì)劃,將計(jì)劃分發(fā)到各個(gè)節(jié)點(diǎn)。那么,這與Spark SQL有區(qū)別嗎?不僅與Spark SQL沒(méi)有區(qū)別,與其他任何Hadoop生態(tài)圈類(lèi)似架構(gòu)如Hive SQL、Flink SQL都沒(méi)有區(qū)別。對(duì)于非SQL的輸入,邏輯也是一致的,只是沒(méi)有了解析SQL的步驟,但還是會(huì)生成執(zhí)行圖分發(fā)到各個(gè)節(jié)點(diǎn)去執(zhí)行,執(zhí)行結(jié)果也可以在主節(jié)點(diǎn)進(jìn)行匯總。
不僅是在計(jì)算上沒(méi)有區(qū)別,存儲(chǔ)架構(gòu)上也沒(méi)有區(qū)別。下面是HDFS的架構(gòu)圖:
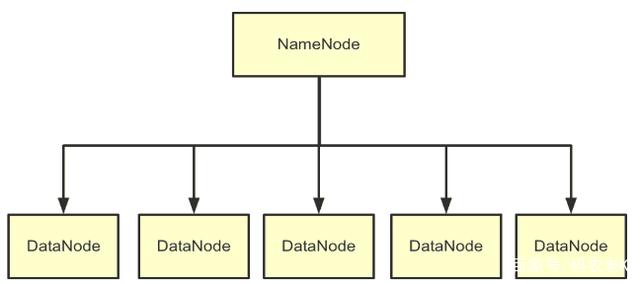
所以回到最初說(shuō)的那句話(huà)——MPP架構(gòu)與Hadoop架構(gòu)在理論基礎(chǔ)上幾乎是在講同一件事,即,把大規(guī)模數(shù)據(jù)的計(jì)算和存儲(chǔ)分布到不同的獨(dú)立的節(jié)點(diǎn)中去做。上面的幾幅架構(gòu)圖印證了這一點(diǎn)。
既然MPP架構(gòu)與Hadoop架構(gòu)本質(zhì)上是一回事,那么為什么很多人還要將兩者分開(kāi)討論呢?我們可能經(jīng)常聽(tīng)到這樣的話(huà):“這個(gè)項(xiàng)目的架構(gòu)是MPP架構(gòu)。”這似乎有意在說(shuō):“這可不是Hadoop那一套哦。”
這就與MPP架構(gòu)的歷史有關(guān)系。雖然從理論基礎(chǔ)上兩者是一回事,但是MPP架構(gòu)與Hadoop架構(gòu)的發(fā)展卻是走的兩條路線。MPP架構(gòu)雖然也是指的“大規(guī)模并行處理”,但是由于提出者是數(shù)據(jù)庫(kù)廠商,所以MPP架構(gòu)在很多人眼中就成了“分布式數(shù)據(jù)庫(kù)”的代名詞,它處理的也都是“結(jié)構(gòu)化”的數(shù)據(jù),常常作為企業(yè)數(shù)據(jù)倉(cāng)庫(kù)的解決方案。
而Hadoop生態(tài)圈是根正苗紅伴隨著“大數(shù)據(jù)”興起而發(fā)展起來(lái)的概念,它所要解決的是大規(guī)模數(shù)據(jù)量的存儲(chǔ)和計(jì)算,它的提出者也并非數(shù)據(jù)庫(kù)廠商,而是有著C端數(shù)據(jù)的互聯(lián)網(wǎng)企業(yè)。因此Hadoop架構(gòu)雖然也解決“大規(guī)模并行處理”,但沒(méi)有了數(shù)據(jù)庫(kù)那一套東西的限制,處理的也大多是“非結(jié)構(gòu)化”的數(shù)據(jù)(自然在最初階段也少了相關(guān)的優(yōu)化)。當(dāng)然,Hadoop生態(tài)圈也要考慮“結(jié)構(gòu)化”的數(shù)據(jù),這時(shí)Hive就成了Hadoop生態(tài)圈的數(shù)據(jù)倉(cāng)庫(kù)解決方案。但是,Hadoop、Spark等框架的理論基礎(chǔ)與分布式數(shù)據(jù)庫(kù)仍然是一樣的。
廣義上講,MPP架構(gòu)是一種更高層次的概念,它的含義就是字面含義,但是它本身并沒(méi)有規(guī)定如何去實(shí)現(xiàn)。Hadoop相關(guān)框架和各個(gè)分布式數(shù)據(jù)庫(kù)產(chǎn)品則是具體的實(shí)現(xiàn)。狹義上講,MPP架構(gòu)成了分布式數(shù)據(jù)庫(kù)這種體系架構(gòu)的代名詞,而Hadoop架構(gòu)指的是以Hadoop框架為基礎(chǔ)的一套生態(tài)圈。
本文并不想僅僅從較高層次的架構(gòu)設(shè)計(jì)來(lái)說(shuō)明兩者是一回事,這樣還是缺乏說(shuō)服力。下面,我們從分布式計(jì)算框架中最重要的過(guò)程——Shuffle——來(lái)展示兩者更多的相似性。
數(shù)據(jù)重分區(qū)
Shuffle是分布式計(jì)算框架中最重要的概念與過(guò)程之一。在MPP架構(gòu)(分布式數(shù)據(jù)庫(kù))中,這個(gè)數(shù)據(jù)重分區(qū)的過(guò)程與Hadoop相關(guān)框架在計(jì)算中的數(shù)據(jù)重分區(qū)過(guò)程也是一致的。
無(wú)論是Hadoop MapReduce,還是Spark或Flink,由于業(yè)務(wù)的需求,往往需要在計(jì)算過(guò)程中對(duì)數(shù)據(jù)進(jìn)行Hash分區(qū),再進(jìn)行Join操作。這個(gè)過(guò)程中不同的框架會(huì)有不同的優(yōu)化,但是歸根到底,可以總結(jié)為兩種方式。
其中一種方式就是直接將兩個(gè)數(shù)據(jù)源的數(shù)據(jù)進(jìn)行分區(qū)后,分別傳輸?shù)较掠稳蝿?wù)中做Join。這就是一般的“Hash Join”。
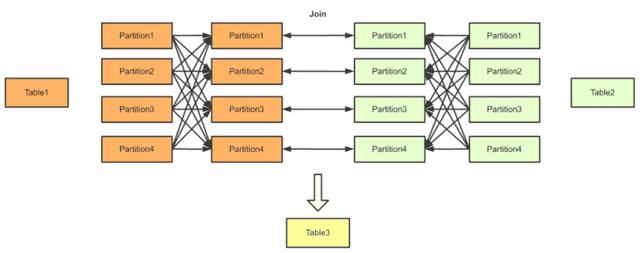
另一種方式是,當(dāng)其中一個(gè)數(shù)據(jù)源數(shù)據(jù)較少時(shí),可以將該數(shù)據(jù)源的數(shù)據(jù)分發(fā)到所有節(jié)點(diǎn)上,與這些節(jié)點(diǎn)上的另一個(gè)數(shù)據(jù)源的數(shù)據(jù)進(jìn)行Join。這種方式叫做“Broadcast Join”。它的好處是,數(shù)據(jù)源數(shù)據(jù)較多的一方不需要進(jìn)行網(wǎng)絡(luò)傳輸。
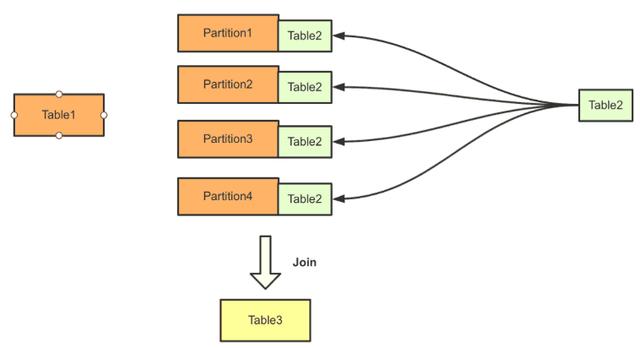
以上是Hadoop相關(guān)框架的實(shí)現(xiàn)。下面用一個(gè)具體的例子來(lái)看MPP架構(gòu)對(duì)這一過(guò)程的思考。
在MPP架構(gòu)中,數(shù)據(jù)往往會(huì)先指定分區(qū)Key,數(shù)據(jù)就按照分區(qū)Key分布在各個(gè)節(jié)點(diǎn)中。
現(xiàn)在假設(shè)有三張表,其中兩張為大表,一張為小表:
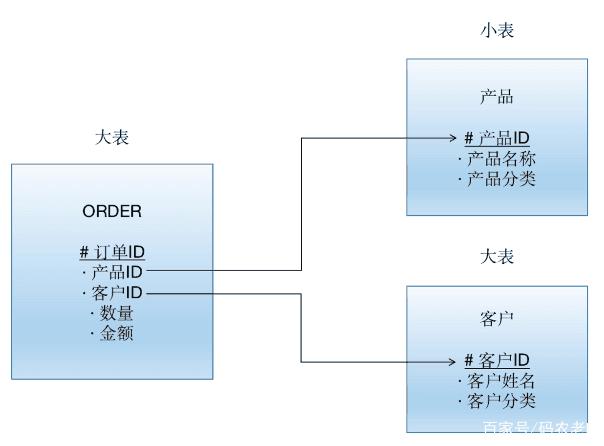
很自然地,訂單表會(huì)選擇訂單ID為做分區(qū)Key,產(chǎn)品表會(huì)選擇產(chǎn)品ID作為分區(qū)Key,客戶(hù)表會(huì)選擇客戶(hù)ID作為分區(qū)Key。給這些表中添加一些數(shù)據(jù),并且執(zhí)行一個(gè)查詢(xún)語(yǔ)句:
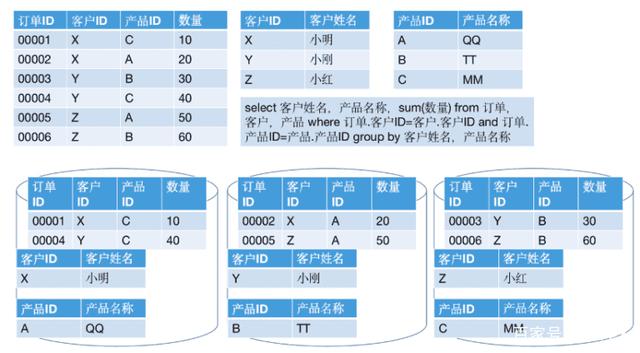
首先,訂單表要與客戶(hù)表做Join,Join Key是客戶(hù)ID。這種操作在Hadoop生態(tài)圈的分布式計(jì)算框架中,相當(dāng)于對(duì)兩個(gè)表做了Hash分區(qū)的操作。不過(guò)由于客戶(hù)表已經(jīng)按照客戶(hù)ID提前做好了分區(qū),所以這時(shí)只需要對(duì)訂單表做重分區(qū)。在MPP架構(gòu)中,會(huì)產(chǎn)生如下的結(jié)果:
此時(shí),訂單表整個(gè)表的數(shù)據(jù)會(huì)發(fā)生重分區(qū),由此產(chǎn)生網(wǎng)絡(luò)IO。這種情況相當(dāng)于Hadoop架構(gòu)中的“Hash Join”。
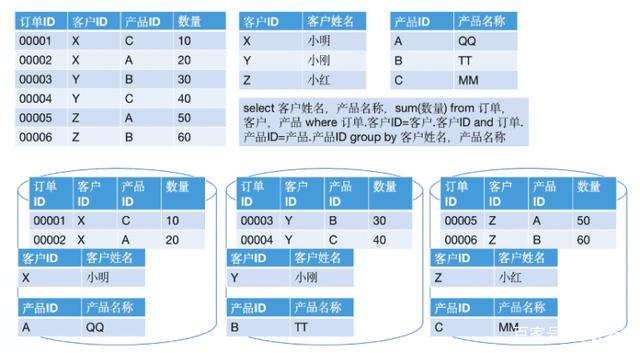
接著,需要讓結(jié)果與產(chǎn)品表按照產(chǎn)品ID做Join。這時(shí),因?yàn)橹爱a(chǎn)生的結(jié)果的分區(qū)Key不是產(chǎn)品ID,看起來(lái)又需要將整個(gè)數(shù)據(jù)進(jìn)行重分區(qū)。不過(guò),注意到產(chǎn)品表是個(gè)小表,所以此時(shí)只需要將該表廣播到各個(gè)節(jié)點(diǎn)即可。結(jié)果如下:
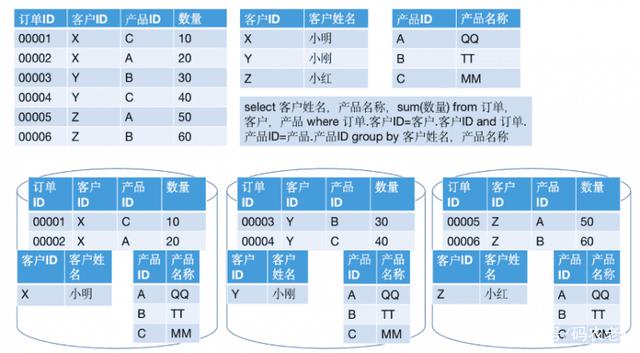
在這個(gè)過(guò)程中,就只有小表的數(shù)據(jù)發(fā)生了網(wǎng)絡(luò)IO。這就相當(dāng)于Hadoop架構(gòu)中的“Broadcast Join”。兩者還有區(qū)別嗎?
前文在MPP架構(gòu)的概念、歷史以及技術(shù)細(xì)節(jié)上與Hadoop架構(gòu)做了對(duì)比,了解到了兩者一些極為相似的地方,而且在廣義上講,Hadoop就是MPP架構(gòu)的一種實(shí)現(xiàn)。
然而前文也講到,由于傳播上的謬誤,現(xiàn)在人們說(shuō)到MPP架構(gòu),主要指的是分布式數(shù)據(jù)庫(kù),它處理的是結(jié)構(gòu)化的數(shù)據(jù),而Hadoop生態(tài)圈是由“大數(shù)據(jù)”這套概念發(fā)展而來(lái),最初處理的都是非結(jié)構(gòu)化的數(shù)據(jù)。以此為出發(fā)點(diǎn),兩者到底在發(fā)展過(guò)程中產(chǎn)生了多大的區(qū)別呢?
對(duì)比的維度有很多,比如很多人會(huì)說(shuō),MPP架構(gòu)的平臺(tái)封閉、擁有成熟的人才市場(chǎng),而Hadoop架構(gòu)平臺(tái)開(kāi)放、人才專(zhuān)業(yè)培訓(xùn)較少等。但這些并不是本質(zhì)的區(qū)別。這里還是以技術(shù)指標(biāo)作為維度來(lái)進(jìn)行對(duì)比。
技術(shù)角度上來(lái)講,MPP產(chǎn)品最大的優(yōu)勢(shì)是作業(yè)運(yùn)行時(shí)間更快。這不難理解,因?yàn)镸PP產(chǎn)品處理的都是結(jié)構(gòu)化數(shù)據(jù),本身就是從數(shù)據(jù)庫(kù)發(fā)展而來(lái),擁有極為復(fù)雜的優(yōu)化器對(duì)作業(yè)進(jìn)行優(yōu)化。這些優(yōu)化器是各廠商最有價(jià)值的商業(yè)機(jī)密,自然是開(kāi)源產(chǎn)品不能比的。不過(guò)另一個(gè)角度來(lái)看,這也是MPP產(chǎn)品相比于Hadoop相關(guān)產(chǎn)品不夠靈活的地方——它只能處理結(jié)構(gòu)化數(shù)據(jù)。
有人說(shuō)MPP產(chǎn)品能夠處理的數(shù)據(jù)量沒(méi)有Hadoop架構(gòu)大。這種說(shuō)法并不準(zhǔn)確。Hadoop架構(gòu)之所以能處理更大量的數(shù)據(jù),其中一個(gè)原因是硬件成本較低,擴(kuò)展更加的方便。實(shí)際上,經(jīng)過(guò)精心設(shè)計(jì)的MPP架構(gòu)照樣可以處理PB及以上級(jí)別的數(shù)據(jù)。有人說(shuō),MPP產(chǎn)品不能處理大規(guī)模數(shù)據(jù),是因?yàn)樵獢?shù)據(jù)的量十分巨大。其實(shí),同樣的問(wèn)題也存在于Hadoop相關(guān)框架中。另一方面,Hadoop相關(guān)框架能處理多大量的數(shù)據(jù),與具體的實(shí)現(xiàn)有很大關(guān)系。如果擁有足夠的資金可以對(duì)MPP產(chǎn)品進(jìn)行擴(kuò)展,而Hadoop相關(guān)產(chǎn)品我們又用基于內(nèi)存的計(jì)算,那么,對(duì)比的結(jié)果一定是MPP產(chǎn)品能夠應(yīng)對(duì)更大的數(shù)據(jù)量。如果非要從數(shù)據(jù)量這一維度來(lái)做對(duì)比,可能反而是Hadoop相關(guān)產(chǎn)品對(duì)小數(shù)據(jù)量更有優(yōu)勢(shì)。比如想要存儲(chǔ)一個(gè)極小的表,MPP產(chǎn)品也許會(huì)根據(jù)分區(qū)Key將其拆分到100個(gè)節(jié)點(diǎn)中去,而HDFS用一個(gè)文件塊存儲(chǔ)就夠用了。
未來(lái)發(fā)展
前面講到MPP產(chǎn)品對(duì)結(jié)構(gòu)化數(shù)據(jù)的計(jì)算和存儲(chǔ)都更有效率。其中一部分優(yōu)化就包括了存儲(chǔ)時(shí)的“列存儲(chǔ)”技術(shù),查詢(xún)時(shí)的“CBO優(yōu)化”等等。這些都是Hadoop生態(tài)圈一開(kāi)始比較缺乏的技術(shù)。但是隨著這些年的發(fā)展,這些技術(shù)早就融入到了Hadoop生態(tài)圈中,Hive、Spark框架的優(yōu)化技術(shù)也越做越好,由此與MPP架構(gòu)的技術(shù)差距也越來(lái)越小,甚至有覆蓋的趨勢(shì)。從最核心的技術(shù)上來(lái)看,兩者未來(lái)只會(huì)越來(lái)越像。可以預(yù)測(cè),Hadoop架構(gòu)的市場(chǎng)會(huì)越來(lái)越大。
不過(guò),分布式數(shù)據(jù)庫(kù)產(chǎn)品在安全性等方面仍然提供著更成熟的解決方案,這是開(kāi)源產(chǎn)品短時(shí)間內(nèi)無(wú)法超越的。因此,“MPP架構(gòu)”這個(gè)概念仍然會(huì)在政府、傳統(tǒng)企業(yè)中長(zhǎng)期占有一席之地。