分布式計算MapReduce究竟是怎么一回事?
?前言
如果要對文件中的內容進行統計,大家覺得怎么做呢?一般的思路都是將不同地方的文件數據讀取到內存中,最后集中進行統計。如果數據量少還好,但是面對海量數據、大數據的場景這樣真的合適嗎?不合適的話,那有什么比較好的方式進行計算呢?不急,看完本文給你答案。
分布式計算思想
我們打開思路,既然文件數據遍布在各個節點上,那么我們就不把文件從各個節點加載過來,而是把算法分到各個節點進行計算,最后統一進行合并處理。這就是所謂的分布式計算。
? 分布式計算將該應用分解成許多小的部分,分配給多臺計算機進行處理。這樣可以節約整體計算時間,大大提高計算效率。

整個思想的核心就是“先分再合,分而治之”。所謂“分而治之”就是把一個復雜的問題,按照一定的“分解”方法分為等價的規模較小的若干部分,然后逐個解決,分別找出各部分的結果,然后把各部分的結果組成整個問題的最終結果。 ?
那么Hadoop也借鑒了這樣的思想,設計出了MapReduce計算框架。那么MapReduce框架具體設計上有什么亮點呢?
MapReduce設計思想
Hadoop在設計MapReduce的時候,吸取了分布式計算中分而治之的思想,同時需要考慮更多細節的問題。
(1)如何對付大數據處理場景
對相互間不具有計算依賴關系的大數據計算任務,實現并行最自然的辦法就是采取MapReduce分而治之的策略。
首先Map階段進行拆分,把大數據拆分成若干份小數據,多個程序同時并行計算產生中間結果;然后是Reduce聚
合階段,通過程序對并行的結果進行最終的匯總計算,得出最終的結果。 ?
不可拆分的計算任務或相互間有依賴關系的數據無法進行并行計算。

(2)構建抽象編程模型
MapReduce借鑒了函數式語言中的思想,用Map和Reduce兩個函數提供了高層的并行編程抽象模型。
map: 對一組數據元素進行某種重復式的處理;
reduce: 對Map的中間結果進行某種進一步的結果整理。

MapReduce中定義了如下的Map和Reduce兩個抽象的編程接口,由用戶去編程實現:
通過以上兩個編程接口,大家可以看出MapReduce?處理的數據類型是<key,value>鍵值對。
(3)統一架構、隱藏底層細節
如何提供統一的計算框架,如果沒有統一封裝底層細節,那么程序員則需要考慮諸如數據存儲、劃分、分發、結果
收集、錯誤恢復等諸多細節;為此,MapReduce設計并提供了統一的計算框架,為程序員隱藏了絕大多數系統層
面的處理細節。
MapReduce最大的亮點在于通過抽象模型和計算框架把需要做什么(what need to do)?與具體怎么做(how to do)分開了,為程序員提供一個抽象和高層的編程接口和框架。
程序員僅需要關心其應用層的具體計算問題,僅需編寫少量的處理應用本身計算問題的業務程序代碼。 ?
至于如何具體完成這個并行計算任務所相關的諸多系統層細節被隱藏起來,交給計算框架去處理: 從分布代碼的執行,到大到數千小到單個節點集群的自動調度使用。
MapReduce介紹
Hadoop MapReduce是一個分布式計算框架,用于輕松編寫分布式應用程序,這些應用程序以可靠,容錯的方式并行處理大型硬件集群(數千個節點)上的大量數據(多TB數據集)。
MapReduce是一種面向海量數據處理的一種指導思想,也是一種用于對大規模數據進行分布式計算的編程模型。

MapReduce特點
易于編程
Mapreduce框架提供了用于二次開發的接口;簡單地實現一些接口,就可以完成一個分布式程序。任務計算交給計算框架去處理,將分布式程序部署到hadoop集群上運行,集群節點可以擴展到成百上千個等。
良好的擴展性
當計算機資源不能得到滿足的時候,可以通過增加機器來擴展它的計算能力。基于MapReduce的分布式計算得特點可以隨節點數目增長保持近似于線性的增長,這個特點是MapReduce處理海量數據的關鍵,通過將計算節點增至幾百或者幾千可以很容易地處理數百TB甚至PB級別的離線數據。
高容錯性
Hadoop集群是分布式搭建和部署得,任何單一機器節點宕機了,它可以把上面的計算任務轉移到另一個節點上運行,不影響整個作業任務得完成,過程完全是由Hadoop內部完成的。
適合海量數據的離線處理
可以處理GB、TB和PB級別得數據量。
MapReduce局限性
MapReduce雖然有很多的優勢,也有相對得局限性,局限性不代表不能做,而是在有些場景下實現的效果比較差,并不適合用MapReduce來處理,主要表現在以下結果方面:
實時計算性能差
MapReduce主要應用于離線作業,無法作到秒級或者是亞秒級得數據響應。
不能進行流式計算
流式計算特點是數據是源源不斷得計算,并且數據是動態的;而MapReduce作為一個離線計算框架,主要是針對靜態數據集得,數據是不能動態變化得。
MapReduce實戰
WordCount算是大數據計算領域經典的入門案例,相當于Hello World。主要是統計指定文件中,每個單詞出現的總次數。
雖然WordCount業務極其簡單,但是希望能夠通過案例感受背后MapReduce的執行流程和默認的行為機制,這才是關鍵。

Map階段代碼實現

實現了map接口,把輸入的數據經過切割,全部標記1,因此輸出就是<單詞,1>。
Reduce階段代碼實現

實現了reduce接口,對所有的1進行累加求和,就是單詞的總次數
啟動代碼

可以參考官方例子:https://github.com/apache/hadoop/blob/branch-3.3.0/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordCount.java
運行
- 第一個參數:wordcount表示執行單詞統計任務;
- 第二個參數:指定輸入文件的路徑;
- 第三個參數:指定輸出結果的路徑(該路徑不能已存在)
查看運行結果
最終可以在/output目錄下看到輸出的結果

MapReduce執行流程
從資源運行層面,一個完整的MapReduce程序在分布式運行時有三類程序,如下所示:
- MRAppMaster:負責整個MR程序的過程調度及狀態協調
- MapTask:負責map階段的整個數據處理流程
- ReduceTask:負責reduce階段的整個數據處理流程

MapReduce任務優先會提交到Yarn組件上,這個主要是用來管理資源的,因為計算需要CPU、內存等資源。首先會運行1個MRAppMaster?程序,主要負責整個MR程序的過程調度及狀態協調。然后運行多個MapTask?,最后運行ReduceTask。
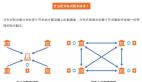
從業務邏輯層面上,以上面的wordCount為例,它的運行流程如下圖所示:

Map階段執行流程
- 第一階段:把輸入目錄下文件按照一定的標準逐個進行邏輯切片,形成切片規劃。默認Split size = Block size(128M)?,每一個切片由一個MapTask處理。
- 第二階段:對切片中的數據按照一定的規則讀取解析返回<key,value>對。默認是按行讀取數據。key是每一行的起始位置偏移量,value是本行的文本內容。
- 第三階段:調用Mapper類中的map方法處理數據。每讀取解析出來的一個<key,value>,調用一次map方法。
- 第四階段:按照一定的規則對Map輸出的鍵值對進行分區partition。默認不分區,因為只有一個reducetask。分區的數量就是reducetask運行的數量。
- 第五階段:Map輸出數據寫入內存緩沖區,達到比例溢出到磁盤上。溢出spill的時候根據key進行排序sort。默認根據key字典序排序。
- 第六階段:對所有溢出文件進行最終的merge合并,成為一個文件。

Reduce階段執行過程
- 第一階段:ReduceTask會主動從MapTask復制拉取屬于需要自己處理的數據。
- 第二階段:把拉取來數據,全部進行合并merge,即把分散的數據合并成一個大的數據。再對合并后的數據排序。 ?
- 第三階段是對排序后的鍵值對調用reduce方法。鍵相等的鍵值對調用一次reduce方法。最后把這些輸出的鍵值對寫入到HDFS文件中。

shuffle階段
- Shuffle的本意是洗牌、混洗的意思,把一組有規則的數據盡量打亂成無規則的數據。
- 而在MapReduce中,Shuffle更像是洗牌的逆過程,指的是將map端的無規則輸出按指定的規則“打亂”成具有一定規則的數據,以便reduce端接收處理。 ?
- 一般把從Map產生輸出開始到Reduce取得數據作為輸入之前的過程稱作shuffle。

以上就是整個MapReduce執行的整個流程。
總結
MapReduce是Hadoop提供的一個分布式計算框架,對于大數據開發人員來說,只要關注于自己的業務,實現他們提供的Map和Reduce接口,接下來底層都交給Hadoop來處理。但是MapReduce已經日薄西山,企業用的也越來越少了,慢慢被Spark、Flink等計算引擎代替,主要原因還是太慢,比如shuffle階段中頻繁涉及到數據在內存、磁盤之間的多次往復,但是這種計算思想還是很值得一學的。