













視頻也可以用擴散模型來生成了,效果很能打:新SOTA已達成
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯(lián)系出處。
?擴散模型最近是真的有點火。
前有OpenAI用它打敗霸榜多年的GAN,現(xiàn)在谷歌又緊隨其后,提出了一個視頻擴散模型。
和圖像生成一樣,初次嘗試,它居然就表現(xiàn)出了不俗的性能。
比如輸入“fireworks”,就能生成這樣的效果:

滿屏煙花盛放,肉眼看上去簡直可以說是以假亂真了。
為了讓生成視頻更長、分辨率更高,作者還在這個擴散模型中引入了一種全新的采樣方法。
最終,該模型在無條件視頻生成任務中達到全新SOTA。
一起來看。
由圖像擴散模型擴展而成
這個擴散視頻模型,由標準的圖像擴散模型UNet擴展而成。
UNet是一種神經(jīng)網(wǎng)絡架構,分為空間下采樣通道和上采樣通道,通過殘差連接。
該網(wǎng)絡由多層2D卷積殘差塊構建而成,每個卷積塊后面跟著一個空間注意塊。
通過固定幀數(shù)的塊,以及在空間和時間上分解的3D U-Net,就可以將它擴展為視頻模型。
具體來說:
先將每個二維卷積更改為三維卷積(space-only),比如將3x3卷積更改為1x3x3卷積(第一軸(axis)索引視頻幀,第二軸和第三軸索引空間高度和寬度)。
每個空間注意塊中的注意力仍然專注于空間維度。
然后,在每個空間注意塊之后,插入一個時間注意塊;該時間注意塊在第一個軸上執(zhí)行注意力,并將空間軸視為批處理軸(batch axes)。
眾所周知,像這樣在視頻Transformer中分對時空注意力進行分解,會讓計算效率更高。
由此一來,也就能在視頻和圖像上對模型進行聯(lián)合訓練,而這種聯(lián)合訓練對提高樣本質(zhì)量很有幫助。
此外,為了生成更長和更高分辨率的視頻,作者還引入了一種新的調(diào)整技術:梯度法。
它主要修改模型的采樣過程,使用基于梯度的優(yōu)化來改善去噪數(shù)據(jù)的條件損失,將模型自回歸擴展到更多的時間步(timestep)和更高的分辨率。
評估無條件和文本條件下的生成效果
對于無條件視頻生成,訓練和評估在現(xiàn)有基準上進行。
該模型最終獲得了最高的FID分數(shù)和IS分數(shù),大大超越了此前的SOTA模型。
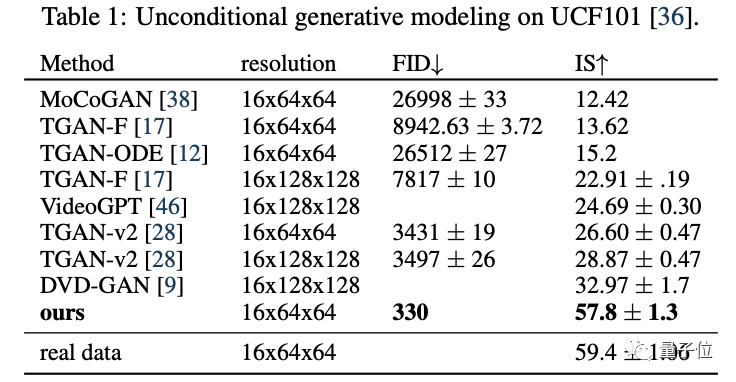
對于文本條件下的視頻生成,作者在1000萬個字幕視頻的數(shù)據(jù)集上進行了訓練,空間分辨率為64x64px;
在此之前,視頻生成模型采用的都是各種GAN、VAE,以及基于流的模型以及自回歸模型。
所以這也是他們首次報告擴散模型根據(jù)文本生成視頻的結果。

下圖則顯示了無分類器引導對該模型生成質(zhì)量的影響:與其他非擴散模型一致,添加引導會增加每個單獨圖像的保真度(右為該視頻擴散模型,可以看到它的圖片更加真實和清晰)。

△ 圖片為隨機截取的視頻幀
最后,作者也驗證發(fā)現(xiàn),他們所提出的梯度法在生成長視頻時,確實比此前的方法更具多樣性,也就更能保證生成的樣本與文本達成一致。

△ 右為梯度法
論文地址:https://arxiv.org/abs/2204.03458
項目主頁:https://video-diffusion.github.io/



























