













爆爆:Java代碼編譯流程是怎樣的?

前言
寫了這么多年的代碼,對于java代碼運行的全流程你心里有清晰的脈絡嗎?
大家會不會跟我最開始一樣,覺得在IDE里點一下RUN按鈕,我們寫的代碼就直接直接跑起來了吧?
俗話說的好,你覺得生活靜好,其實只是因為有人在為你負重前行,編譯器和虛擬機默默的承受了這一切。
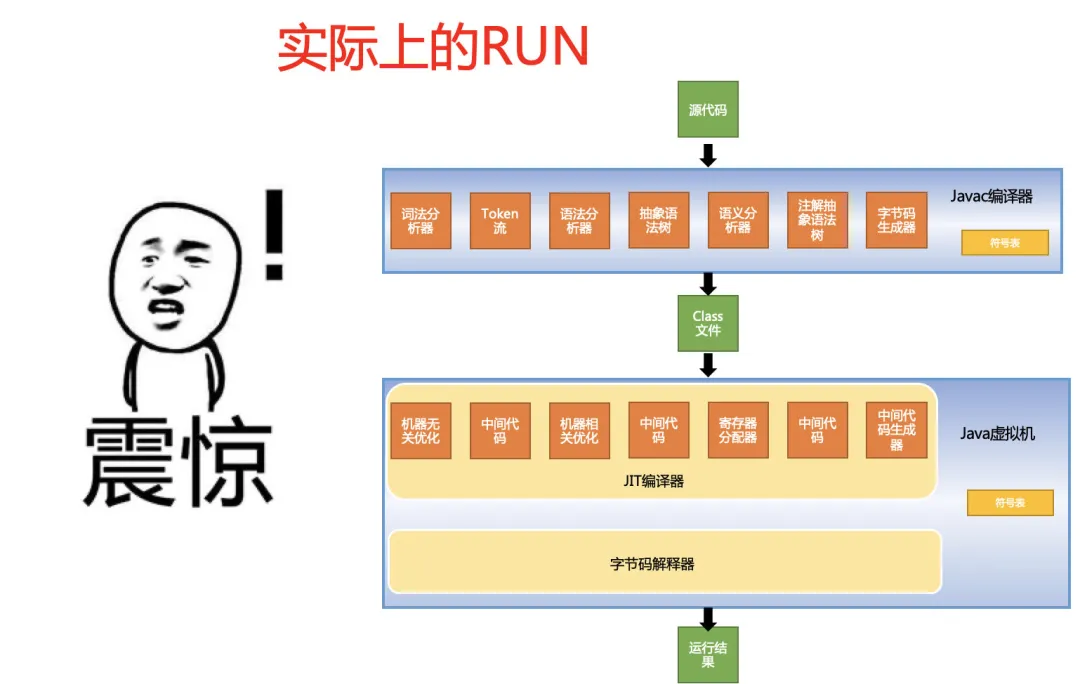
小小的一個RUN,背后卻是很多組件共同努力的結果,它們必須非常努力,才能看起來毫不費力。
今天就讓我們花點篇幅,來好好聊聊,Java代碼RUN起來的背后,那些默默付出的大功臣們。
當我們寫下一行代碼時,我們到底在寫什么?
夜深了,我們在屏幕上打下一段優雅的代碼,一邊擰開泡著枸杞的保溫杯抿了一口熱水,一邊欣賞自己詩一樣的代碼,心里默默地夸了一波自己:不愧是我!

第一個問題來了,計算機真的能看到我們寫的”詩“嗎?
眾所周知,Java是一門"一次編寫,到處運行"的語言,也就是所謂的平臺無關性,不管在哪個平臺都能夠運行,且保證運行的結果與期待的一致。(這是大學老師反復強調的)
Java實現”平臺無關性“的原理也非常簡單,就是利用中間格式來進行過渡,也就是我們常說的字節碼,通過將Java源代碼轉換成字節碼,保證JVM(Java虛擬機)讀取到的一定是自己能夠識別的字節碼格式。

一個通俗的解釋:你不會說法語,法國人不會講中文,但是你們或多或少都會點英語,把英語作為你們的中間格式,保證雙方都能明白對方的意思,這就是所謂的跨平臺。
Java源碼首先被編譯成字節碼,而這個字節碼就是實現平臺無關性的關鍵,無論你是什么類型的平臺,只要你安裝了能夠識別字節碼的JVM(Java虛擬機),通過JVM對字節碼文件進行解析,把字節碼轉換成具體平臺上的機器指令,就可以實現跨平臺的運行了。
因此別說讓計算機底層讀到我們寫的”代碼詩“了,就連Java虛擬機都拿不到我們原汁原味的代碼,在編譯器的努力下,Java源代碼已經變成大白話的class文件了。
所以啊寶,操作系統欣賞不到我們”詩一樣的代碼“,我們所寫的每一行代碼,都會變成一條條指令,對操作系統來說,它看到的不是編程的藝術,只是自己需要完成的一條條KPI罷了。

文本即代碼?
如果我們寫了具有同樣內容的Java文件和txt文本,他們在文本編輯器中長得是沒有區別的。

有一句名言是:世界上最好的IDE是txt文本編輯器。現在我們可能用IDE都用順手了,很多的操作我們都習慣于讓IDE給我們提示,依賴于IDE的代碼補全和快捷鍵。
但在傳說中,有一群用記事本就能打出優美代碼的大佬,到了這個境界時,已經是人碼合一,無需語法高亮,無需補全提示,所有的正確語法都了然于心,打出來的每一行代碼都是可以直接編譯run起來且零BUG的好代碼(doge)。
扯得有點遠了,但用記事本確實是可以實現開發功能,只要你自己打的代碼邏輯正確,且沒有語法錯誤,最后保存的后綴是.java,就能作為代碼去運行了。
因此,從本質來說,我們所打出來的txt文本和Java代碼在一開始是沒有多大區別的,用普通的文本編輯器也能打開我們的.java后綴的文件。但是文本編輯器能做到的也僅僅限于看到.java文件里面的代碼文本而已了。
Java編譯器才是最終,能夠識別并理解.java文件的存在。
Java代碼想要運行起來,第一步就是得到編譯器的認可。編譯器的任務很簡單,就是將符合Java語言源碼編譯為符合 Java虛擬機規范的Class文件,如果輸入的Java源碼不符合規范則需要報告錯誤。
可以說,編譯的過程是Java開發的第一小步,但也是程序的一大步。
接下來我們先介紹一下編譯器在Java體系中的位置。
JDK與JRE的愛恨情仇
在我們初學java時,一定安裝過所謂的java環境,當我們自信滿滿地點進了Oracle的Java官網,映入眼簾的是兩個看起來很像的安裝包:
這我就蒙蔽了呀,我就想裝個Java環境,怎么有兩個奇奇怪怪的安裝包,一個叫JDK,一個叫JRE,這兩個安裝包跟俗稱的”Java“又有什么關系?
先理清楚所謂的JDK和JRE到底有什么區別吧,來看一張Java 8的體系架構圖(https://docs.oracle.com/javase/8/docs/):
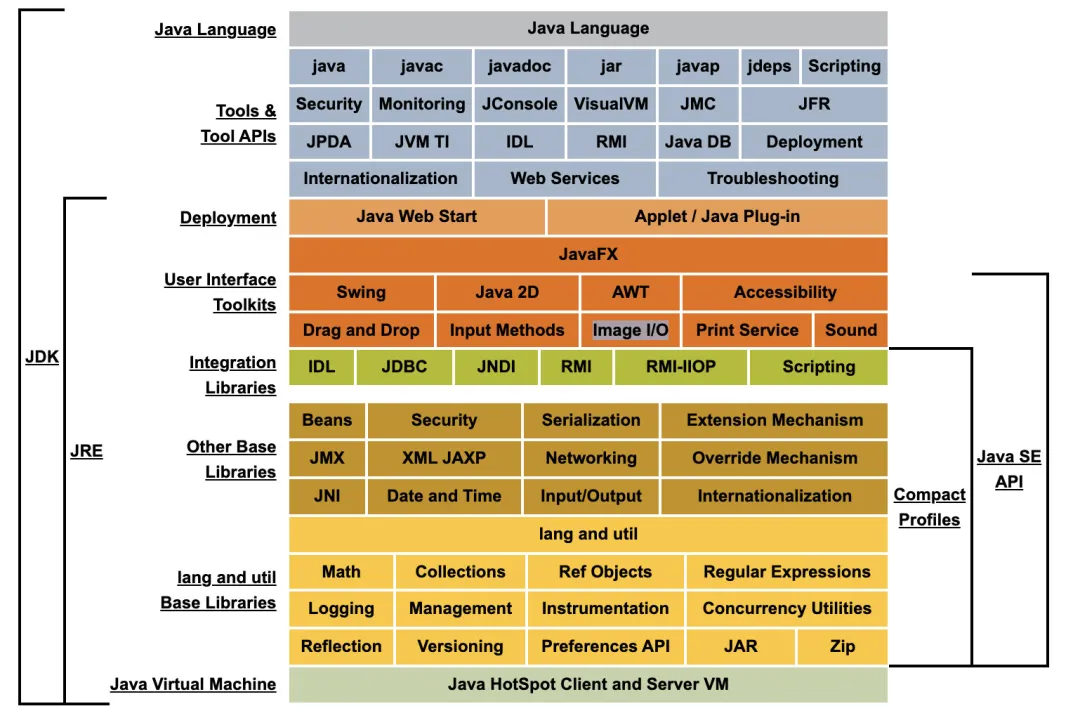
jdk8體系架構圖
JDK全稱是Java開發工具包(Java Development Kit),它包含了Java從開發到運行的各種工具。
JRE指的則是Java運行環境(Java Runtime Environment),它包含了基礎類庫和JVM虛擬機。
上圖展示的是Java 8的體系結構,最左邊的一欄很清晰的表明了JDK和JRE各自的范圍,我們也很容易發現:
JRE是JDK的子集。
既然你要搞開發,肯定得保證自己寫的代碼能運行起來吧,所以當開發人員安裝好JDK之后里面已經包含了一個運行環境JRE,保證自己的代碼能夠得到運行和驗證,這就是為什么JRE被包含在JDK中。
但如果我們是普通用戶,并不關心開發,甚至根本不懂代碼,我只想要代碼跑起來的結果,那只需要本地有JRE運行環境就行了。
如果用過零幾年的按鍵手機,你就會深有體會,那時候很多的手機軟件都是用Java編寫的,只需要一個JAR包,你就能收獲快樂。

手機Java應用
反向思維一下,既然安裝JRE就能運行JAVA代碼,但要需要完整的JDK才能完成開發,那他們之間的差集肯定跟開發的過程有關。
所以接下來,我們來探討一下為什么缺少這一塊內容就只能成為運行環境,而不能承擔開發功能呢?
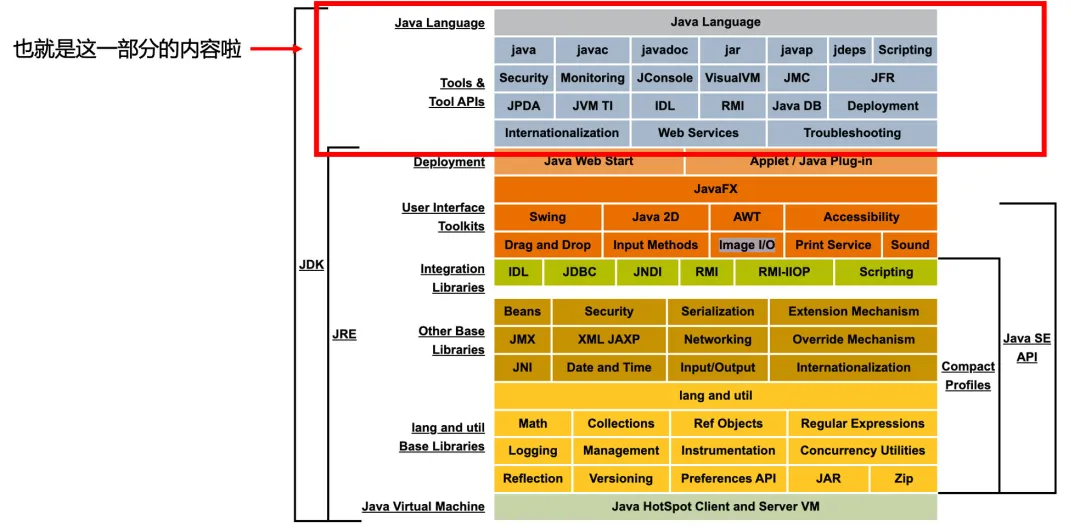
JDK和JRE的差集
這一塊里我們可以看到幾個很熟悉的命令:
- javac:用于編譯java源代碼,生成class文件;
- javap:用于反編譯,根據class文件,反解析出其中的匯編指令和其他信息;
- javadoc:用于生成java文檔的命令。
其中,我們最常用的、最重要的就是javac命令。這是JDK中內嵌的編譯器,通過這個命令,可以將java源文件轉換成class文件。這個javac編譯器就是JRE相比于JDK少了開發功能的決定性元素!!
我們用一個簡單的例子看看,開發者編寫好的java代碼在完整的JDK架構下,經過JDK、JRE以及JVM的運行過程。
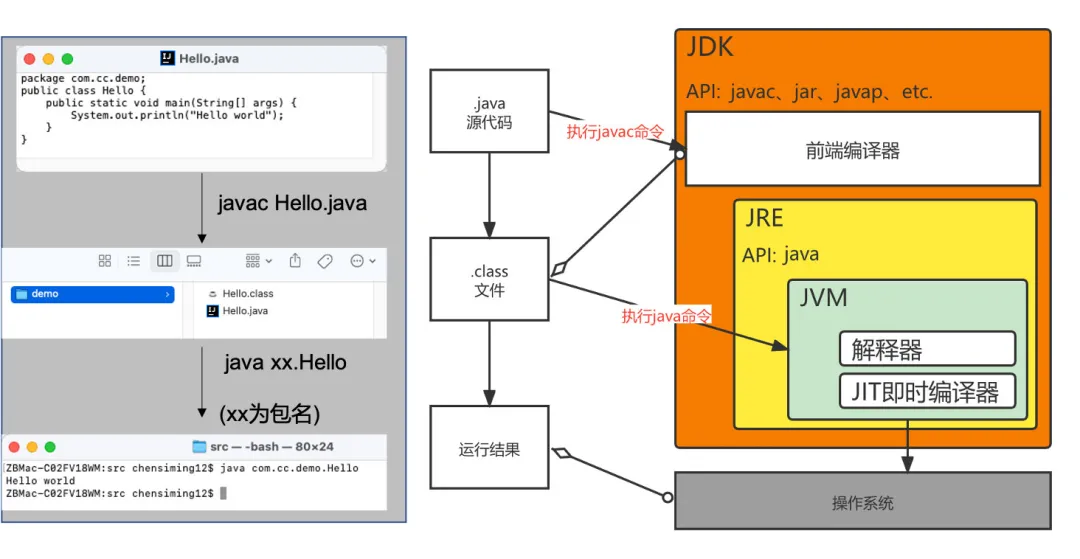
java代碼運行的簡單示例
可以看到,通過JDK中的javac命令,我們才能將java源代碼編譯成class文件,而前面也提到了,這個class文件才是最終放到JVM中運行的文件。
我們把java源碼到class文件的過程稱之為編譯階段,把class文件到JVM中運行得到結果的階段稱為運行階段。
因此,如果只有JRE而沒有完整的JDK的話,相當于就少了編譯源代碼的關鍵工具,你只能依賴人家傳遞的,已經編譯好的class代碼,將程序運行起來,而不具備修改、開發的能力。
聰明的你很快就能發現,既然虛擬機運行需要的其實是class文件,因此它對于最前面用的是什么語言其實并不關心,只要支持生成JVM能夠識別的字節碼就行了。
難道說……
沒錯,恭喜你發現了JVM虛擬機**”跨語言“的特性**。
很多語言依賴了這種特性,將自己本身的源代碼,編譯生成class文件,并基于JVM虛擬機運行。比較常用的有Scala和Kotlin等,它們甚至可以跟Java語言相互調用,因為最終都是要編譯成class文件到虛擬機中運行嘛,所以即使在源代碼階段是不同的語言,經過編譯器之后,大家都變成了一樣的字節碼。
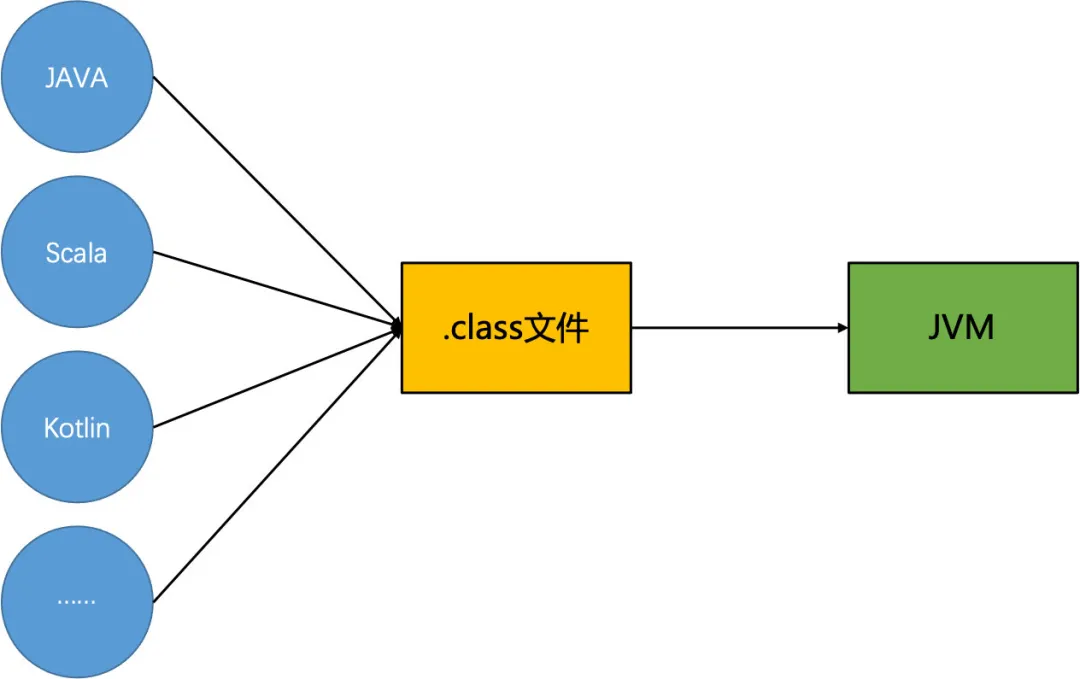
多語言轉換為字節碼
當然,要是再極端一點,由于class文件本質上也是一個二進制的文件,因此只要你足夠強,能夠徒手寫出自己需要的二進制文件,你也就不再需要編譯器了(狗頭保命)。
很多讀者就要說了:”我們是來學技術的,不是來學仙術的“。

先別笑,直接改字節碼并不是什么天上飛的仙術,而是實打實的技術。像我們熟悉的lombok,就能夠根據我們編寫的注解生成字節碼,實現字節碼的修改增強(但lombok也是利用了編譯器的一些特性,是在編譯階段觸發操作的)。
類似的還有諸如ASM等一些字節碼增強技術,也是通過直接操作字節碼來實現的。
通過字節碼增強技術可以實現熱部署等操作,讓你修改代碼之后無需重啟服務就能生效;也可以實現日志注入等功能,在不需要改變客戶端調用方式情況下完成對指定方法增加緩存或日志的功能。
但對于大部分的普通開發者來說,編譯器還是必不可少的。
編譯階段
當調用javac命令,觸發java代碼的編譯過程,將.java文件編譯成了.class二進制文件。
那么,在編譯器中,源代碼到底是怎么一步步變化的呢。
注意:javac是javac編譯器的自帶的命令,但市面上可用的并不只有javac這一種編譯器,有一些其他的廠商也根據java的標準開發了自己的編譯器。例如Eclipse的ecj(the Eclipse Compiler for Java)等。
只是大部分人用的都是JDK自帶的javac的編譯器,因此下文的討論都是基于javac編譯器展開的。
可以這樣理解,編譯的過程就是”編“和”譯“。
編:將java源代碼的結構組織成合適的格式,包括編譯過程中的抽象語法樹和符號表等,并在最終將源碼編碼成為class文件。
譯:對源代碼中的語義進行解析,并準確地翻譯成另一種形式(字節碼)。這一步既要確保原格式正確(Java源代碼中的語法正確),又要確保翻譯后的字節碼跟源代碼表達的意思一致。
也就是說,編譯的過程要保證 輸入的格式符合Java語言規范,輸出的格式符合Java虛擬機規范。
這個過程說起來復雜,但是讀者可以回憶一下自己經歷過的代碼編譯失敗的場景,每一次編譯失敗都是編譯器在默默工作的結果,不同的錯誤可能是在編譯過程的不同階段被發現并拋出的。
接下來,我們循序漸進地告訴大家編譯的具體步驟,以及編譯過程的各個階段拋出的不同編譯異常。

編譯過程調用圖
東西看起來很多哈,總結起來大概可以分為下面幾個步驟:
1. 詞法分析&語法分析
詞法分析是最開始的一步,主要的作用就是把源代碼的字符流轉換成Token集合,Token是指代碼中具有獨立語義且不可再分的標記。
這里要注意,一個Token指的并不是單個的字符,而是具有實義的詞。而且,編譯器還會識別不同的詞法類型,為它分配對應的Token類型,比如,int就會被識別為Token.INT ,運算符也會被分配為對應的Token類型,例如+就是Token.PLUS:
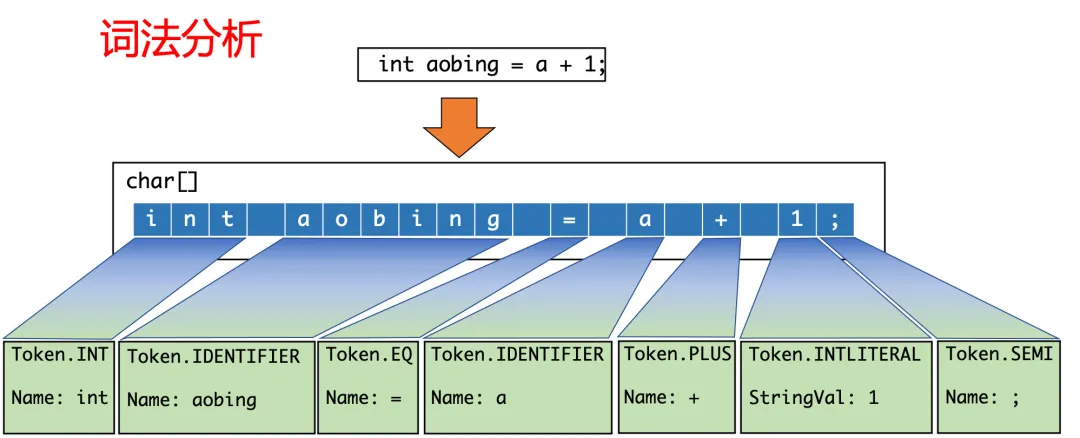
詞法分析
當代碼被解析為一系列的Token集合之后,下一步是進行語法分析。
語法分析是根據解析后的Token集合,解析出抽象語法樹(Abstract Syntax Tree, AST),AST中包含了java代碼中的層級結構。
小知識:在NLP等領域的研究中,語法樹也是用來分析語法規則及原理的重要手段,在這里不過多闡述。

語法分析1
根據這個結構,可以層級地展示代碼中所有的變量、方法甚至是注釋等各種信息。
構建AST的過程會判斷Token的類型與其在樹中的位置是否匹配,這一步我們很好理解哈,你用關鍵字作為變量名稱的時候編譯會不通過,就是在這一步被逮到的。
例如,你用這樣一段代碼去編譯:
- public class Hello {
- public static void main(String[] args) {
- String enum = "world";
- System.out.println("Hello world");
- }
- }
會報如下的錯誤:
- error: as of release 5, 'enum' is a keyword, and may not be used as an identifier
因為enum是關鍵字,構建語法樹的時候發現堂堂一個關鍵字居然出現在了標識符的位置,這可使不得啊!
因此AST樹構建失敗,編譯報錯。
詞法分析&語法分析是對源代碼中文本的抽象,將.java源代碼中的文本結構按照編譯器特定的規則拆分、解析,為后續的編譯工作鋪平了道路,后面的操作都離不開這個AST。
2. 填充符號表符號表
就是由符號地址(位置)和符號信息構成的”表格“,它存儲的是標識所對應的類型、作用域等。
這里說它是”表格“可能會對讀者產生一定的誤解,實際上它不是像我們想象的那種二維的表格,而是更接近hashTable那樣的鍵值對結構,符號表可以由數組、樹狀結構或者棧等各種結構來實現。
這個符號表在后續的很多步驟都能發揮作用,例如:
- static char x;
- int foo() {
- int x;
- {
- float x;
- }
- }
這段代碼有三個同名變量,聰明的讀者肯定能夠分辨它們各自的作用域,但是笨笨的計算機沒辦法那么快分清它們的區別。
為了在解析符號和類型的時候分清它們的作用域而不產生使用沖突,就需要通過符號表來記錄關系。
填充符號表的過程可以描述為:
- 將每個AST的頂層節點都放到待處理的列表中,并逐個處理;
- 將所有的類符號(類的聲明,名稱)都輸出到外層的作用域的符號表中;
- 如果發現有package-info.java文件(描述整個包的信息和包內的常量),將其頂層節點放到待處理的列表中;
- 明確泛型類型的真實類型;
- 如果類中沒有任何構造器,則添加默認的無參構造器;
- 將類中符號輸入到類自身的符號表中。
這一步有點抽象了,大家也不用太糾結于細節,能夠明白大概的流程和目的就行了,只需要理解,這一步就是為了生成記錄了類中符號的類型、屬性等信息的符號表,方便后續流程中的應用。
強調一下5,學過java基礎的都知道,如果一個類沒有定義構造器,則會默認一個默認構建無參構造器,添加默認構造器的操作也是在填充符號表時完成的。
為什么呢?
很簡單,因為類的構造方法也是需要放到符號表里記錄的,而且不能為空,既然你沒有指定,那我就給你放一個默認的空參構造器,然后記錄到符號表咯。
相關的源碼就放著這里了,大家有興趣可以深挖一下。http://hg.openjdk.java.net/jdk8u/jdk8u/langtools/file/2baeb96fa198/src/share/classes/com/sun/tools/javac/comp/Enter.java
3. 注解處理
自從JDK 5以來,Java提供了對注解的支持,現在程序中使用注解已經是非常常規的操作。
然而要注意的是,并不是所有的注解都是在編譯期起作用的,我們平時用反射處理的注解主要是指運行時注解,運行時注解在編譯期不受影響,在編譯之后的class文件中還是會保留,最終要在class文件到JVM運行的過程中才生效。
而編譯期注解是指以@Retention(RetentionPolicy.SOURCE)定義的,在編譯期就處理了的注解,這一類注解不會保留到class文件中。
聽起來很懵,但其實編譯過程中這一步注解處理其實大家在無意中已經接觸過很多次了,比如大家常用的lombok,就是在這一步起作用的。
lombok采用的就是編譯期注解處理的方法,因此當我們編譯好用了lombok注解的.java文件后,打開生成的class文件就可以看到lombok相關的注解已經消失,而相應的getter、setter方法則已經被注入到class文件中。
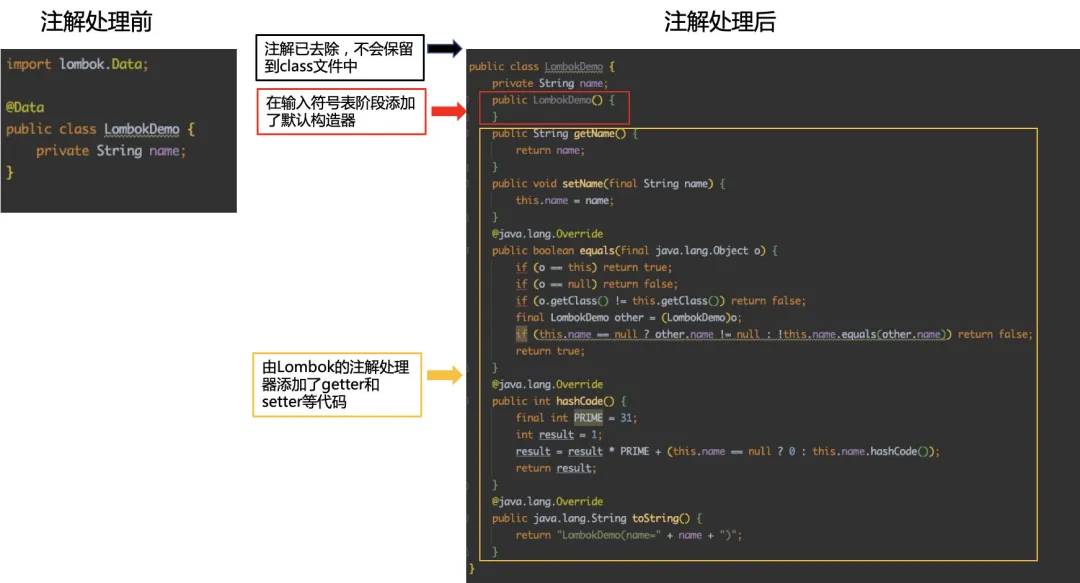
上圖中右圖展示的并不是class文件,而是與添加lombok注解等效的源代碼,左右兩側的代碼生成的字節碼是一致的。
在這一步,lombok的注解處理器生效,并對我們前面所說的抽象語法樹AST進行增強處理。
首先找到@Data注解所在類對應的語法樹(AST),然后修改該語法樹(AST),增加getter和setter方法定義的相應樹節點,實現我們所需的功能。
這一步也是為數不多的,編譯器留給程序員自己編寫代碼來影響源代碼編譯過程的機會。
注解處理完成后,可能又會產生新的符號,因此如果執行了注解處理,需要再執行一次解析和填充符號表的操作(回到第2步)。
4. 語義分析
語義分析聽起來跟第一步詞法分析&語法分析看起來很像,但其實是有很大區別。
我們類比成語文來解釋:
敖丙說:”吃你飯今天了嗎?“。
詞法分析的步驟相當于把這一句話拆成了你、吃、今天、飯、了、嗎、?,這幾個詞語。每個詞都沒問題。
可是到了語義分析階段,我們再根據規則檢查這句話的語義,發現這句話其實是不通順的。
回到編譯過程中來解釋,語義分析的功能就是從結構和規則上對源代碼進行檢查,包括聲明檢查和類型檢查等等。
這里我們用周志明老師書中的一個例子來說明:
假設有如下3個變量定義的語句:
- int a = 1;
- boolean b = false;
- char c= 2;
- int d =a + c;
- int e = b + c;
- char f = a + c;
這一段代碼能夠通過第一步的詞法分析和語法分析,并構成正確的AST,但是在語義分析中會報錯。因為編譯器發現變量e和f的運算都是不符合規范的,參與運算的兩個值的類型不匹配該運算符的邏輯。
語義分析更進一步檢查上下文中變量的規范性,例如變量是否已經聲明,變量的數據類型與其參與的運算是否匹配等等。
如果要對語義分析做細分的話,可以分為以下幾個小階段:
4.1 標注檢查
這就是剛才說的,檢查變量是否事先聲明以及運算類型是否匹配的步驟,而且這一步的處理會影響到AST的結構:
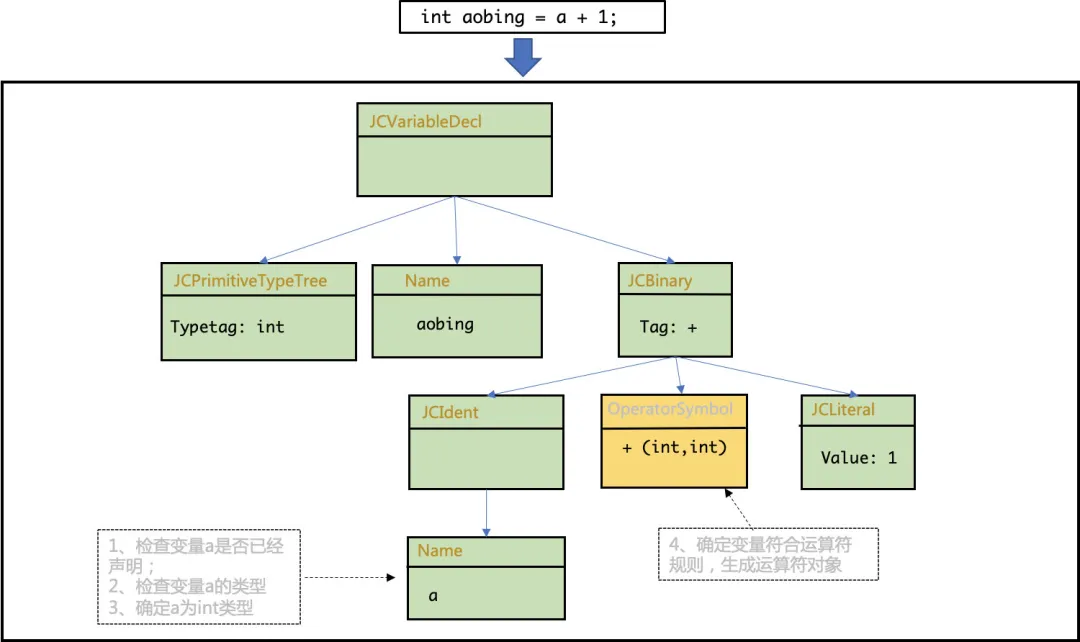
注意圖中所示,我**們首先需要檢查變量a有沒有聲明(聲明檢查),并檢查a的類型(類型檢查),這兩個檢查都需要用上我們前文已經填充完成的符號表,從符號表中查詢變量的作用域和類型,**完成語義分析的檢查。
然后判斷運算符和另一個運算值的類型,檢查左右運算值的類型是否匹配,能否參與運算。
看到了嗎,在這里AST和符號表就共同發揮作用啦。
此外,標注檢查步驟還有兩個很重要的操作:
泛型方法類型的推導:
在這一步就需要明確泛型方法傳遞的真實類型是什么了;
常量折疊(Constant Folding):
這是一個很有意思的操作,它會進行一些簡單的常量計算,例如:int a = 1 + 2;在這一步就會被優化為a = 3,優化之后在AST中還是能夠看到int、a、1、+、2、;這幾個標記,但是這個表達式的值已經被計算出來了,并在AST上進行了標注。也就是說,現在的AST既保留了表達式的結構,也記錄了表達式的結果。
當后續到虛擬機中去執行字節碼的時候,由于編譯期常量折疊的優化,int a = 3和int a = 1 + 2的運行效率其實是一樣的,因為這一個常量的運算在編譯期已經做完,不會再額外消耗運行期的處理時間。
一般的代碼優化都是要到生成字節碼之后,等到運行期在虛擬機的解釋器中再進行的。而常量折疊是javac編譯器對源代碼做的極少量的優化措施之一,也是為數不多的編譯期對代碼進行優化的操作。
4.2 數據流分析
數據流分析是在標注檢查之后的進一步檢驗,主要檢驗是局部變量在使用前是否確定性賦值、聲明有返回值的方法是否有確定性的返回值等。
值得注意的是,final變量不可重復賦值的性質也是在這一步檢查,如果一個final變量被重復賦值,編譯器會發現并報錯的。也正是因為這個特性,用final關鍵字局部變量只會在編譯期去校驗,不會對在運行期產生任何作用 。
有如下的例子:
- // 方法1
- public void aobingTest(final int nezha){
- final int a = 0;
- }
- // 方法2
- public void aobingTest(int nezha){
- int a = 0;
- }
這兩個方法產生的字節碼是一模一樣的,沒有任何的差別。因此所有的final不可重復賦值的限制,都在編譯期得到了檢驗,如果聲明為final的局部變量被重復賦值,在編譯期就會報錯,如果沒有發現有final重復賦值的錯誤,才會成功生成字節碼。
因此對于運行期來說,局部變量是否聲明為final,不會有任何校驗的步驟(因為局部變量不管有沒有用final限制,生成的字節碼都是一樣的,字節碼中不會保留局部變量是否聲明為final的信息)。
5. 解語法糖
簡單地來說,語法糖就是方便程序員編寫的便捷寫法,這種語法不會對最終的結果產生實際影響,但能夠減少程序編寫者的工作量。
例如,java中的自動拆箱裝箱功能、foreach循環功能等,都是為了程序員能夠更寫出更簡潔流程的代碼而封裝的語法糖。
但是到了程序運行階段,這樣的語法糖對計算機來說是不可識別的。因此需要在編譯階段先解語法糖,將語法還原為它本來”笨拙“的樣子。
例如,將包裝類型拆成普通類型,將增強for循環替換為普通的for循環。
6. 生成Class文件
終于到了生成最終需要的class文件的一步了,前面所構建的語法樹、符號表等信息,在這一步被轉換成字節碼指令寫到class文件中,除此之外,還有兩個非常重要的方法被添加到語法樹中,他們分別是和方法。
注意,這兩個長得像init的方法指的并不是類中的構造函數。
方法是一個類的構造器,它的作用是初試化所有的靜態變量并執行用static {}包裹的代碼塊,而且該方法的收集是有順序的:
將這些與類相關的初始化代碼按順序收集在一起生成了函數,在類加載的時候按順序運行,所以方法相當于是把靜態的代碼打包在一起,等待后續統一執行。
- 父類靜態變量初始化
- 父類靜態語句塊
- 子類靜態變量初始化
- 子類靜態語句塊
方法其實是一個實例構造器,它的作用是初始化類中的成員變量,例如成員變量的賦值操作,以及被{}符號包裹的代碼塊,這些方法都會被收斂到方法中成為一個跟對象初始化相關的方法。該方法的收集也是有順序的:
- 父類代碼塊
- 父類構造函數
- 子類變量初始化
- 子類代碼塊
- 子類構造函數
- 父類變量初始化
通俗來說,這兩個方法就是將源代碼中的代碼塊和變量初始化的步驟按照靜態與非靜態分為了兩類,并按一定順序打包好,等待合適的時機執行。
對方法來說,這個合適的執行時機就是在類被加載的時候;
而對方法來說,執行的時機就是在該類new一個對象的時候。
由于類加載過程優先于對象實例化過程,所以方法一定比方法先執行。因此它們完整的執行順序就是:
- 父類靜態變量初始化
- 父類靜態語句塊
- 子類靜態變量初始化
- 子類靜態語句塊
- 父類變量初始化
- 父類語句塊
- 父類構造函數
- 子類變量初始化
- 子類語句塊
- 子類構造函數
發現了嗎,這就是常見的面試題:”java代碼的加載順序“的標準答案。
這個問題的本質其實在于:Java代碼能夠保持加載順序的原因就是在生成class文件時,將按順序拼接好的和方法添加到了class文件中,在后續的運行過程中再按順序執行。
以后面試遇到這個問題知道怎么答了嗎。
除了生成構造器之外,生成class文件時還會優化某些代碼邏輯的實現方式,比如,將字符串的+運算操作,替換為StringBuffer或者StringBuilder的append()方法。
到此為止,java源代碼到class文件的編譯過程進入了尾聲。
由于篇幅原因,今天暫時講到Java代碼編譯為class文件的過程,后續我們再繼續鉆研class文件中的細節以及字節碼最終在JVM中運行的流程。
一些思考
對了,還有一個問題可能是大家理解上的誤區。
很多人會認為class文件 = 字節碼,這是不對的,class文件并不等于字節碼。我們從class文件的結構中可以窺見端倪,class文件中記錄了如下的一些信息:
- 結構信息:class文件格式版本號;
- 元數據:主要對應的是Java源代碼中”聲明“和”常量“對應的信息,包括類的聲明信息、類中屬性域與方法的聲明信息、常量池等;
- 方法信息:主要對應Java源代碼中”語句“和”表達式“對應的信息,包括 字節碼、異常處理器表、操作數棧和局部變量區的大小等;
這下就很清晰了,字節碼是Class文件的一個子集,只是class文件中眾多組成部分的其中之一。
乖,以后別再以為Class文件就是字節碼了。


















