













元宇宙煉丹要講物理基本法!英偉達副總裁:不用真實世界數據訓練
以下觀點可能有點反直覺:
為了讓AI更好地應對真實世界應用場景,訓練數據集最好別用真實世界數據。

是的,合成數據才是解鎖AI真正潛力的關鍵所在。
顧名思義,合成數據不是從真實世界搜集所得,而是由人工生成的。
但合成數據的使用素來伴隨爭議,業界一直對其能否精確對應現實世界、能否讓受訓AI應對真實狀況存有疑慮。
為此,負責模擬技術與Omniverse引擎建造的英偉達副總裁Rev Lebaredian在專訪中給出了解答。

物理模擬
2021年11月,老黃在GTC大會上推出了Omniverse Replicator,一個強大的合成數據生成引擎,可以產生物理模擬的合成數據,并用于訓練神經網絡。
說到「模擬」,我們最常接觸的其實就是游戲了,而在這其中加入一些現實中的物理學定律可以讓體驗更加真實。
比如,當你用炸藥包去爆破一堵墻時,隨著一聲巨響,這堵墻也跟著轟然倒塌。但如果這堵墻紋絲不動,就會不禁讓人懷疑,是不是又在偷工減料了。
當然了,在大多數情況下,游戲并不會去試圖做到真正100%的還原。畢竟,模擬真實的世界太消耗算力了。
另外,游戲終究是幻想世界的模擬,目的就是為了好玩,所以遵循現實世界的物理準確性不一定是一件好事。
雖然此前有不少研究探討過在游戲中訓練AI,不過效果肯定還是大打折扣的。
而Omniverse的目標就是還原一個完全遵照現實物理學定律的模擬世界。
這里說的模擬,是用剛體物理學、軟體物理學、流體動力學以及其他相關的東西模擬原子如何相互作用。
例如,光是如何與物體的表面相互作用,最終呈現出我們平時所看到的外觀的。

而當我們能足夠近似地模擬真實世界的時候,也就獲得了相應的「超能力」。
預測未來
比如說,把我們所在的這個房間,1:1在虛擬世界中復刻出來,那么我就可以用上帝視角選擇任何想去的地方,然后「瞬移」過去。
再比如,通過在火星上安裝傳感器攝取真實世界的信息,并在虛擬世界中重建之后,那么實際上我就可以在任何時間體驗生活在火星上的感受。
而這,還不是最厲害的。
在足夠精準的模擬下,只需設置一定的初始條件,就能具備預測未來的能力。
還是用這個房間舉例,我正舉著我的手機。此時,就可以模擬我放手的那一刻會發生什么,而不需要我真的松手。
顯然,手機會隨著重力掉落。
在模擬世界中,我就可以預測這部手機會以怎樣的姿態掉下,落地之后屏幕會不會碎,等等。

也就是說,你可以無限次地測試在不同決策和條件下產生的結果,甚至探索所有可能出現的「平行世界」。
如果能據此做出相應的優化,也就能找到最好的未來。
還在用真實數據訓練AI?
在這個AI業勃興的新時代,一個研究生拿臺筆記本電腦就能寫出先進軟件的場景不可能出現了。
可以說,任何先進算法的開發,都需要在海量數據的巨型系統之下訓練。
所以,當下也有著「數據是新時代石油」的說法。
如此看來,方便搜集數據的大型科技企業似乎更占優勢。

不過實情是,現在企業搜集的大數據,對未來將創造的尖端AI并沒有真正用處。
在2017年國際計算機圖形學大會(SIGGRAPH 2017)上,我就注意到了這一點。
當時我們開發了可以玩多米諾骨牌的機器人,還開發了好幾個用來訓練機器人的AI模型。其中最基礎的一個是能偵測攤在牌桌上的多米諾牌的計算機視覺模型,能夠分辨骨牌的指向與牌面花色、點數。

用谷歌總能找到足夠的訓練數據吧?
確實,用谷歌圖像搜索是可以找到一大堆多米諾骨牌圖像,但你會發現:
- 這些圖像都沒標注,所以要費大量人工去逐個標注每張圖中的骨牌。
- 就算標注完了,你又會發現這些數據缺乏必要的多樣性。
應用于真實場景的圖形識別算法若要足夠穩健,就必須在不同的光照條件、攝像頭/傳感器狀態下都能成功運行。而識別多米諾骨牌的算法還要對所有材質的骨牌都能成功區分。
所以說,就算如此簡單的訓練要求,必要的足夠數據都不存在。

真要在現實中搜集好必要數據,那就先得買幾百副不同的多米諾牌、在不同打光下用不同的攝像頭去拍。
因此在2017年,我們直接用一個游戲引擎編碼出隨機的多米諾牌生成器,所有訓練數據都用它來生成,一晚上就訓練出能穩健工作的圖像分辨模型了。
該模型在大會現場處理用不同攝像頭拍攝圖像后的工作狀況也很滿意。
這只是個簡單例子,對于自動駕駛汽車或全自動機器等遠為更復雜的場景,所需訓練數據的體量、準確度、多樣性,全從真實世界搜集是不可能滿足的。
除非生成物理上足夠精確的AI訓練數據,否則沒有繼續進步的空間。

能否覆蓋訓練所需的危險狀況?
在Omniverse里,日夜可以隨時倒換,并且可以模擬包括冰雪環境、急速過彎等情景。
行人與動物也可以安置在真實世界中絕不會安排的危險場景內。
沒人會愿意真正將人或動物置于高危中,但自動駕駛汽車生產者肯定需要了解產品在各種危險邊緣環境里將如何表現。

所以在虛擬世界中訓練AI,各得其便。
合成數據是最好的訓練策略?
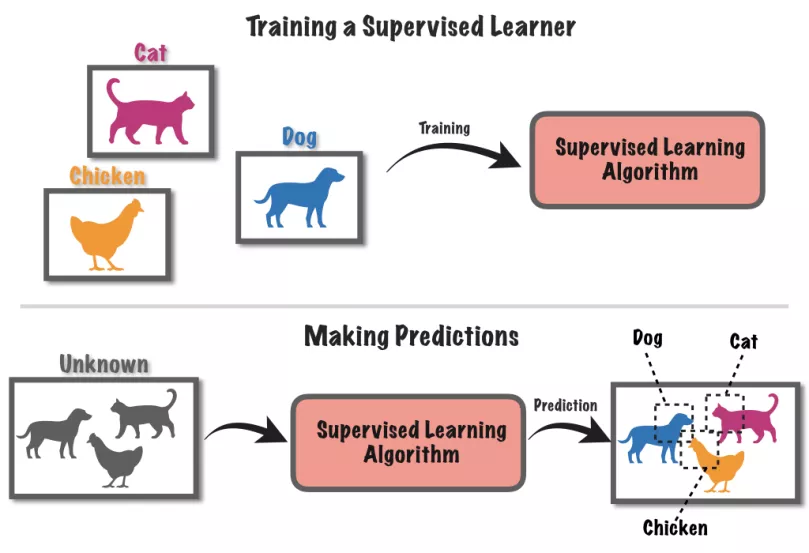
當下大部分AI還是通過「監督學習」方式創造的。例如讓神經網絡AI分別貓狗,先得用標注好的圖片教AI何為貓何為狗,然后才能應用在未標注的新圖片上。
而用于訓練AI的合成數據,由于內置了超級精確的數據標注,是可以作為「基準真相數據」使用的。
在自動駕駛汽車場景中,用戶需要讓智能汽車通過真實世界的傳感器了解到路面各種車輛和行人相對于自身的3D位置。但其實傳感器給AI的信息是除了像素啥都沒有的2D圖像。
如果要訓練AI推斷出物體3D信息,首先得在2D圖像的物體周圍畫框,告知AI「這是基于某傳感器的某鏡頭得到的某物相對距離」。
不過若在Omniverse合成數據的話,就可以省略此步驟直接得到有完全物理精度的物體3D位置信息了,如此可以避免人工引入數據產生的錯誤標注。用來訓練神經網絡也會得到更智能和更精確的效果

會不會出現過擬合的問題?
合成數據其實是解決過擬合難題的有效途徑之一,因為生成多樣性數據集遠為更方便。
如果要訓練一個識別面部表情的神經網絡AI,但訓練數據集全來自白人男性,那這個AI就在白人男性數據上過擬合了,識別多種族裔面部表情時會失敗。
合成數據不會惡化這種狀況,只會更容易地在數據中創造多樣性。
如果要生成人像時有個能改變人臉參數的合成數據生成器,那么膚色、瞳色、發型等各種信息就能有豐富的多元區別,用來訓練AI就避免了上述過擬合狀況。

一個沒有偏見的烏托邦?
AI誕生的環境就是合成的。它們在電腦中出世,然后只靠人類輸入的任何數據受訓。所以建構訓練AI的完美虛擬世界是可行的。
在如此世界中完成訓練的AI,會比靠真實數據訓練的AI更智能,在真實世界中的運行狀態也會更好

不過,合成數據的難點在于生成優質數據不容易。需要有個如Omniverse一般能物理上精確對應真實世界的模擬器。
如果合成數據生成器的生成圖像質量有如卡通畫,那顯然難以勝任。
沒人愿意把用卡通畫訓練出的AI搭載在服務于真實醫院的機器人上,這種機器人照顧起病弱老幼的結果可太嚇人了。
模擬器因此也需要盡可能地極度物理精確,但做到這點真的很不容易。













