













百度計算生物研究登Nature子刊!結果超斯坦福MIT,落地制藥領域
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
百度新研究,登上了Nature子刊。
科技公司卷到學術圈頂刊上不算稀奇。
但這次有點不同尋常。
研究領域與生物領域直接相關,接收該論文的期刊Nature Machine Intelligence(NMI),影響因子達到了16.649。

除了專業(yè)度保障,研究的實驗結果也超越MIT斯坦福。
而且更關鍵的在于,跟后者大部分“產(chǎn)學研”模式不同。
百度是實打?qū)嵶约邯毩⒏愠鰜淼摹?/span>
作者全部來自螺旋槳PaddleHelix,百度生物計算團隊。
嗯,還是可復現(xiàn)的那種,目前GitHub上已經(jīng)開源了完整代碼(地址可在文末獲取)。
研究人員表示,相關部分項目已經(jīng)實現(xiàn)了商業(yè)化落地。
來看看究竟是一項什么樣的研究。
小分子3D結構被AI整明白了
此次百度聚焦的研究,是小分子化合物性質(zhì)預測。
簡單來說,通過小分子結構來預測其性質(zhì),幫助藥物研發(fā)的早期探索,從而解決該領域成本高、時間長、成功率低等難題。
小分子藥物結構有良好的空間分散性,其化學性質(zhì)也更有助于成藥,因此相較于大分子藥物(蛋白質(zhì)、核酸等)在藥物研發(fā)上更有優(yōu)勢。市場上大部分藥物也屬于小分子藥物。
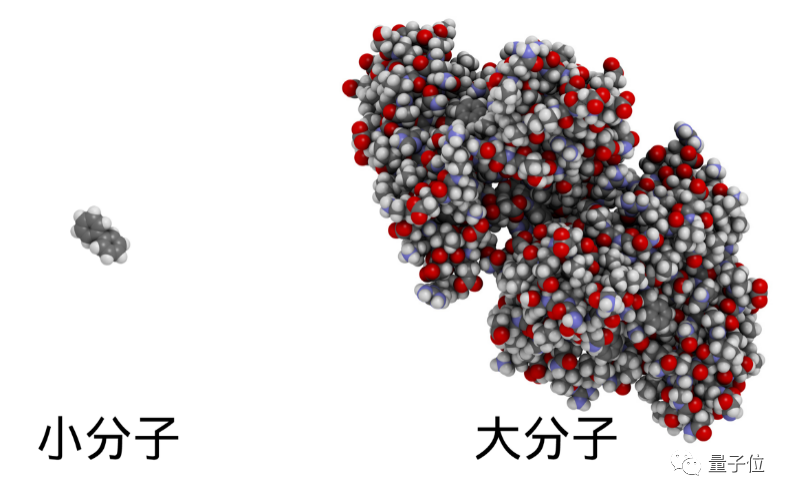
但即便有先天優(yōu)勢,面臨的特殊挑戰(zhàn)也不小。
最大的挑戰(zhàn),莫過于小分子的篩選空間實在是太大了。
早前Nature一篇研究表明,小分子藥物研發(fā)篩選數(shù)量在10的60次方。
什么概念呢?作者形容,“比太陽系的原子數(shù)量還要多”。
要在這樣一個龐大「小分子宇宙」中尋求合適的候選藥物,高效準確的化合物表征就起到關鍵作用。
基于這樣的背景下,研究團隊此次的研究提出了幾何增強型的分子表征方法,簡稱GEM。
這個方法主要包含兩個部分:基于空間結構的圖神經(jīng)網(wǎng)絡GNN、以及多個幾何級別的自監(jiān)督學習。
不難看出,本次研究的亮點在于空間、幾何。
據(jù)介紹,這是業(yè)界首次將空間結構引入到化合物建模當中。
之所以這樣強調(diào),跟他們要解決的問題不無關系,那就是讓AI也能理解小分子的3D結構。
個中原因,需要從現(xiàn)有表征方式說起。
目前研究主要有兩種表征方式:基于序列的一維表征和基于圖形的表征。
一個以字符串作為輸入,利用序列模型比如RNN和Transformer來學習分子表征,但存在一些明顯的局限性,比如字符串語法難以理解,兩個相鄰的原子在文本序列上可能相距甚遠;字符串的一個小變化可能導致分子結構的大變化。
另一個則與今天的研究相關——GNN建模,以圖作為輸入,每個原子是一個節(jié)點,每個化學鍵是一個邊。
嗯,就跟化學書那樣式兒的。
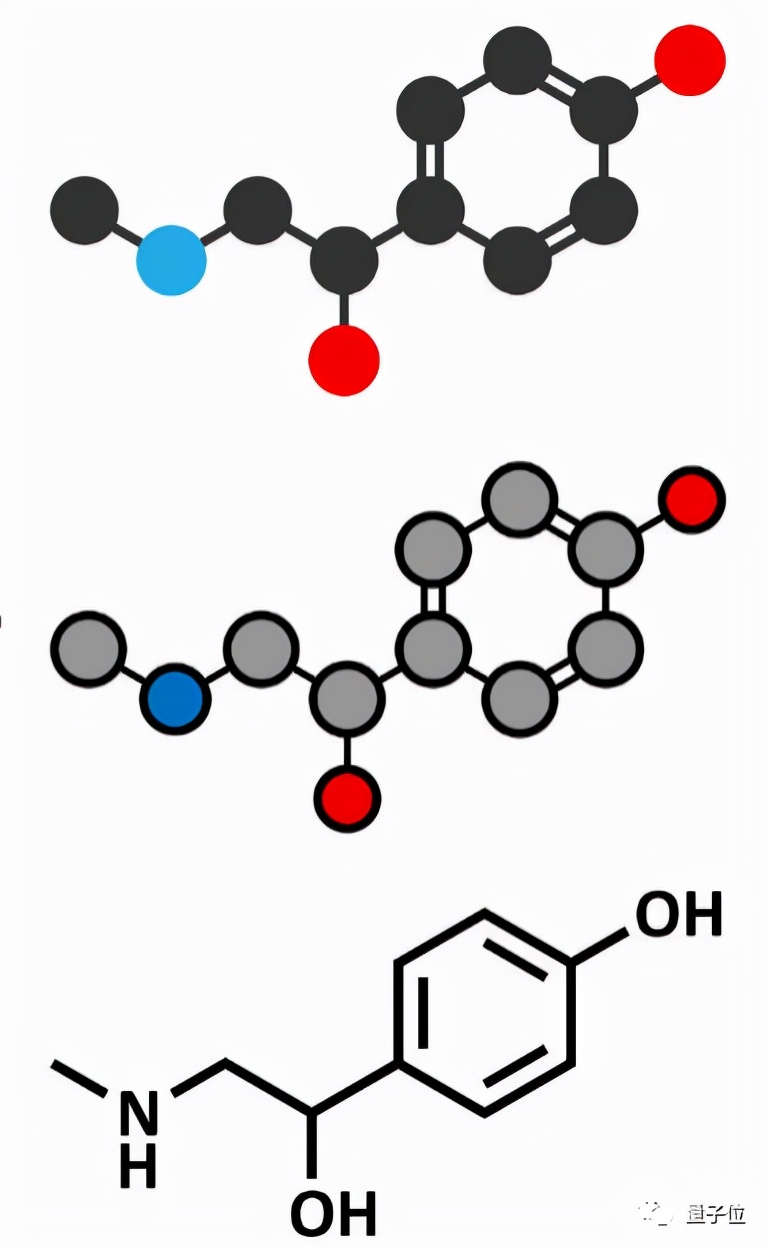
但多數(shù)研究只停留分子的二維信息,忽略了三維空間結構。
這也不難理解,畢竟要想準確獲得分子的三維結構信息其實并不容易。
要是所選描述三維結構的參數(shù)一旦不理想,其性能可能上述兩種表征方法更糟,還將面臨魯棒性不足和預測性能不理想等問題。
但即便如此,三維結構信息卻很關鍵,因為往往決定了分子的物理化學性質(zhì)及生物活性的不同。
最典型的例子,就是高中學的同分異構體。
以二氯乙烯為例,它就有順反式結構,因為幾何結構不同,導致二者的水溶性不同。
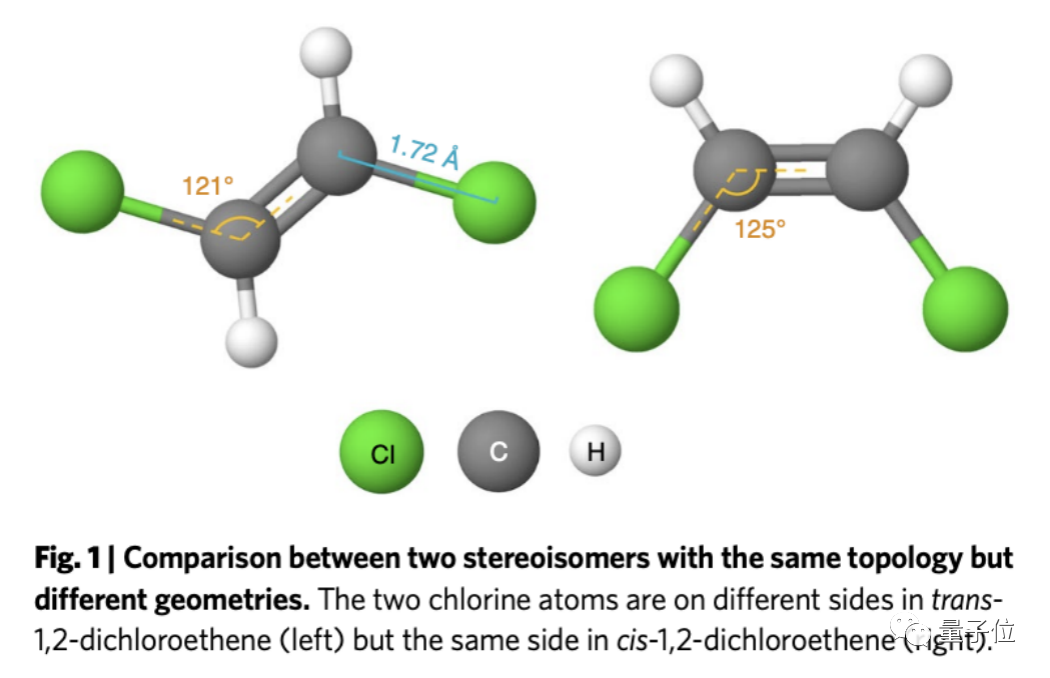
還有像順鉑和反鉑(二氯二氨合鉑),順鉑是一種流行的抗癌藥物;但反鉑有毒卻沒有抗癌活性。
既然如此,那就來看看這項研究是如何解決的。
首先來看圖神經(jīng)網(wǎng)絡,本次研究人員提出了一種GeoGNN。每個分子的輸入包含兩個圖,可同時模擬原子、鍵和鍵角的影響。
第一個圖,即二維結構圖,也叫做原子-化學鍵圖,仍以原子為節(jié)點,鍵為邊。
第二個圖,化學鍵-鍵角圖,則是以鍵視作節(jié)點,鍵角視作邊。
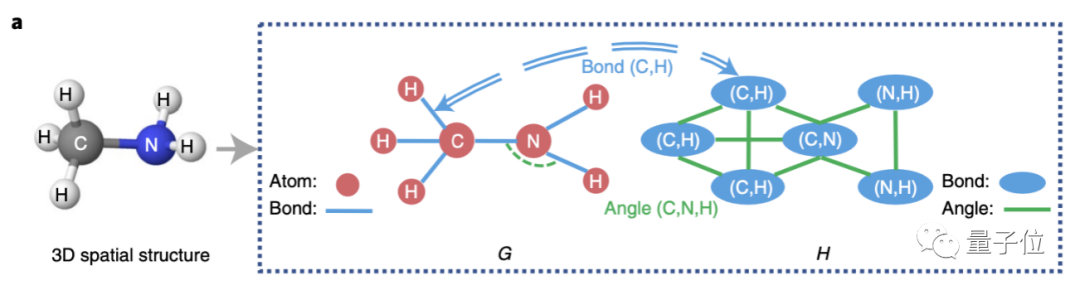
GeoGNN經(jīng)過多輪迭代學習原子和鍵的表征向量,為了連接兩個圖,化學鍵作為每一輪迭代中圖G和圖H的橋梁進行信息互通。
最后通過匯集原子表征得到分子表征,用來化合物性質(zhì)預測。
為了更好的學習分子空間知識,除了以幾何信息作為輸入,進一步地,研究團隊設計了多項自監(jiān)督學習任務。
比如,預測化學鍵的長度、化學鍵組成的鍵角、兩兩原子之間的距離。
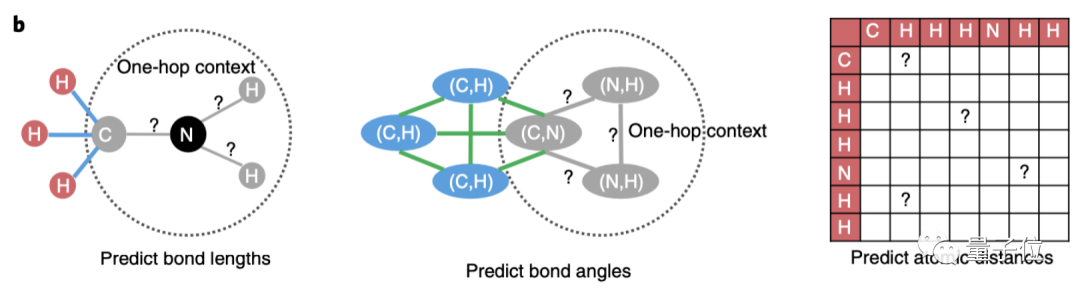
其中,鍵長和鍵角描述化合物的局部結構,兩兩原子之間的距離更關注化合物的全局結構。
局部結構的,就隨機挑選某個原子中心(圖中的N)的子圖進行遮蓋,預測化學鍵的鍵長和之間的鍵角。
全局結構的,則是預測原子距離矩陣中的元素。
預訓練過程中,團隊從一個公開數(shù)據(jù)集Zinc1522中,抽取2000萬個未標記的分子來訓練GeoGNN。
其中90%的分子用來訓練,其余分子進行測試。
最終結果顯示,在當前公認化合物性質(zhì)預測數(shù)據(jù)集MoleculeNet21的15個基準數(shù)據(jù)集中,與現(xiàn)有方法比較,得到了14個SOTA結果。
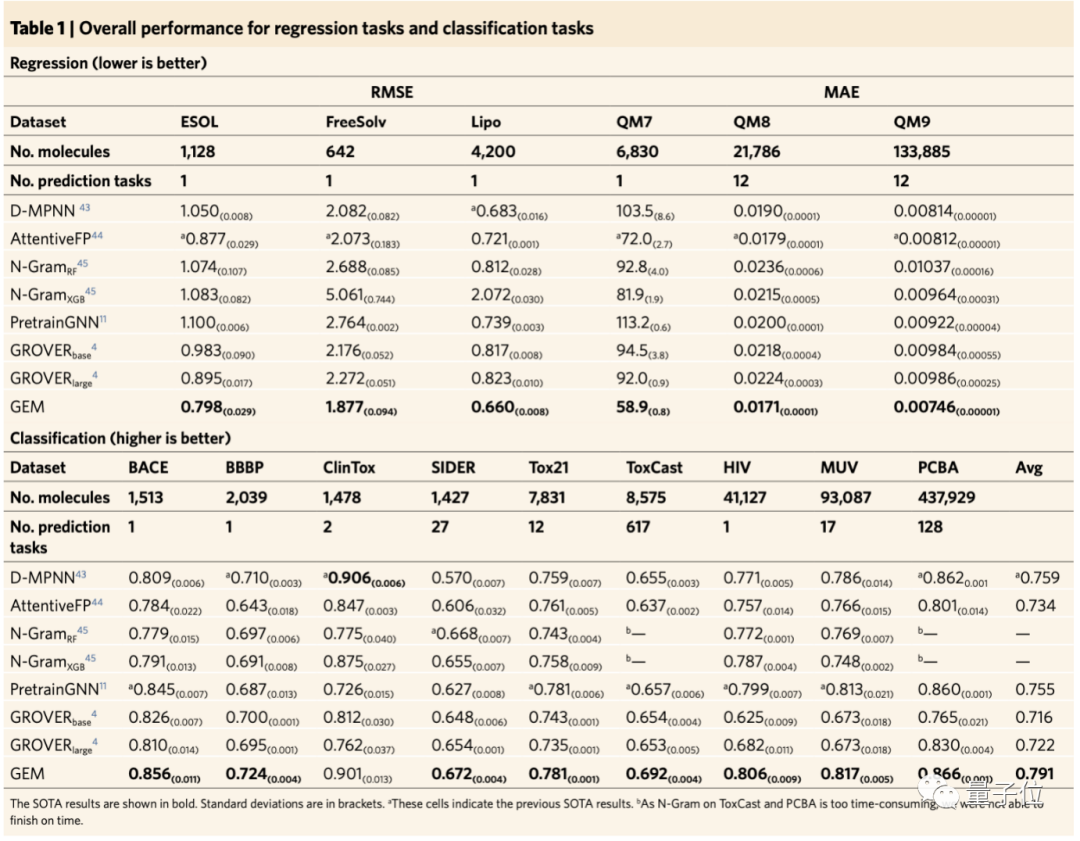
其中,像與毒性相關的數(shù)據(jù)集tox21、toxcast,以及HIV病毒數(shù)據(jù)集,GEM的表現(xiàn)比其他模型要好,比如騰訊的GROVER、斯坦福的PretrainGNN以及MIT的D-MPNN等。
總體而言,百度的GEM模型,在回歸任務上相對現(xiàn)在方法提升8.8%,在分類任務上相對提升4.7%。
可以看到,在回歸數(shù)據(jù)集上的結果比分類數(shù)據(jù)集上的改進更大。團隊猜測,因為回歸數(shù)據(jù)集的重點是預測量子化學和物理化學特性,而這與分子幾何結構高度相關。
進一步地,團隊研究了GeoGNN在沒有預訓練的情況下,在回歸數(shù)據(jù)集上的表現(xiàn)有何影響。
結果與現(xiàn)有的GNN架構比較,其中包含常用GNN架構、結合三維分子幾何的架構以及分子表征架構。
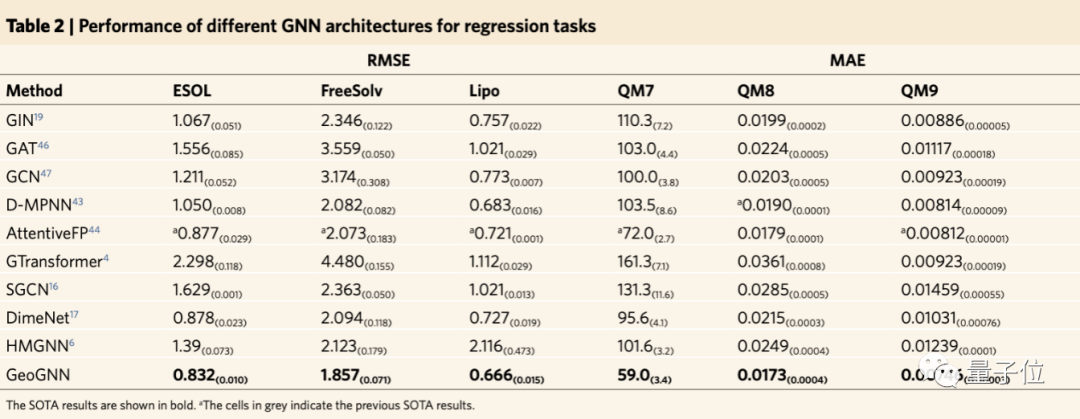
與以往最優(yōu)結果相比,總體改進7.9%。
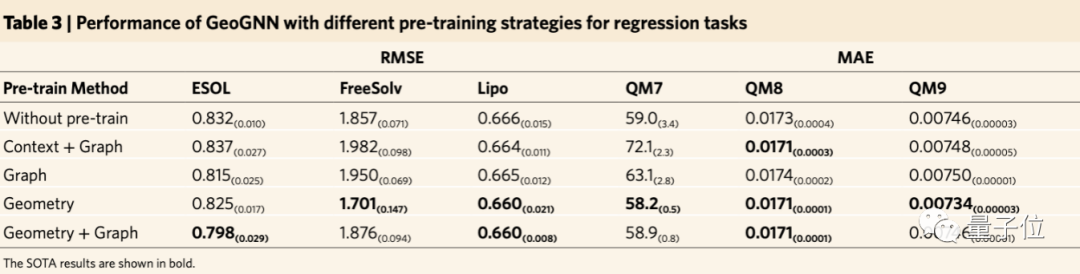
此外,在自監(jiān)督學習方法上的消融實驗也證明了基于空間結構的自監(jiān)督學習方法的有效性。
該項目已經(jīng)在GItHub上開源。
據(jù)介紹,除了在學術期刊亮相外,研究團隊透露,這項研究在藥物研發(fā)領域已經(jīng)實現(xiàn)商業(yè)化落地,在合作伙伴的早期藥物篩選管線上得到應用。
未來,這項技術還有更多可預見的應用價值,比如像化合物成藥性預測、小分子的藥物篩選、藥物聯(lián)用等具體場景。
再拓展一點,沒準兒在蛋白質(zhì)、核酸等領域,也能構建基于大分子的表征模型,有助于更多藥物研發(fā)。

事實上,百度這次在Nature子刊上的亮相,帶來計算生物領域的新進展。
情理之外,卻是意料之中。
不為大多數(shù)人所知道的是,百度在計算生物上的探索,其實早已開啟。
曾在GNN頂賽上超越DeepMind
早在2018年,百度就正式啟動了計算生物方向的研究。
著名的RNA二級結構開源算法LinearFold,將新冠預測從原來的55分鐘提速至27秒(接近120倍),就是百度的研究成果之一。
2020年12月,百度正式將自己研究的一系列生物計算相關技術進行了集成,發(fā)布了螺旋槳(PaddleHelix)。
這是一個囊括了各種各樣“AI+計算生物”開源工具的生物計算平臺,基于百度飛槳框架開發(fā),可以被用于藥物研發(fā)、疫苗設計和精準醫(yī)療等領域。

而這次的研究,正是來自百度螺旋槳團隊。
在發(fā)表這項研究之前,螺旋槳團隊就已經(jīng)在包括像KDD、NeurIPS、IEEE BIBM等頂會上發(fā)表過不少“AI+生物”的研究成果。
例如,一篇用采用多任務學習訓練ML模型進行藥物虛擬篩選的研究,就于去年年底被生物信息與生物醫(yī)學頂會IEEE BIBM 2021接收;
除此之外,包括蛋白質(zhì)、mRNA也有不少研究成果,例如一篇基于蛋白質(zhì)序列預測蛋白質(zhì)間相互作用的多模態(tài)預訓練模型就入選MLCB的Spotlight;
關于圖神經(jīng)網(wǎng)絡預測分子性質(zhì)的相關模型,則更是在全球性的頂會賽事上取得過數(shù)一數(shù)二的成績。
例如,去年6月KDD CUP與OGB(Open Graph Benchmark)聯(lián)合舉辦了首屆圖神經(jīng)網(wǎng)絡大賽OGB-LSC,共有包括DeepMind、微軟、螞蟻金服等來自全球的500多個著名高校&機構參與。

其中,OGB是圖神經(jīng)網(wǎng)絡的通用性能評價基準數(shù)據(jù)集,素有“圖神經(jīng)網(wǎng)絡的ImageNet”之稱;KDD CUP則是目前數(shù)據(jù)挖掘領域水平最高的頂尖國際賽事。
這場比賽一共分為三場,包括大規(guī)模節(jié)點分類、大規(guī)模圖關系預測和化學分子圖性質(zhì)預測。
在化學分子圖性質(zhì)預測賽事中,百度螺旋槳生物計算團隊取得了亞軍的成績,冠軍來自MSRA和北大等高校機構聯(lián)合團隊,第三名則是DeepMind。
這還只是三場GNN比賽中,與生物計算相關的那場。
在同一賽事的另外兩場圖神經(jīng)網(wǎng)絡比賽,節(jié)點分類和圖關系預測中,螺旋槳生物計算平臺背后的百度飛槳框架,又接連取得了2個冠軍,同樣超越了DeepMind等團隊。

這些模型與研究并非“紙上談兵”,有不少成果都已經(jīng)被落地。
例如,百度與斯微生物合作,針對LinearDesign的mRNA疫苗序列設計算法進行了生物實驗,證明模型的關鍵指標超出基準序列20倍,在疫苗研發(fā)中確實有更高的實用價值;
隨后百度也與藥企賽諾菲簽訂協(xié)議,將LinearDesign用于優(yōu)化mRNA疫苗的設計研發(fā)。
至于更早的研究LinearFold開源算法,則已經(jīng)被上百家企業(yè)用于疫苗設計研究中。
種種跡象都在表明,百度進軍生物計算并非一日之談。
恰恰相反,這項發(fā)表在Nature子刊上的研究,正是它在生物計算方面布局了很多年的成果力證。
數(shù)據(jù)爆炸下的生物科技
百度走的生物科技這條路,其道不孤。
放到整個更大的計算生物領域來看,不止是百度,這幾年的國內(nèi)外科技公司,包括騰訊、阿里、英特爾、三星、谷歌母公司Alphabet等,其實都在加大布局。
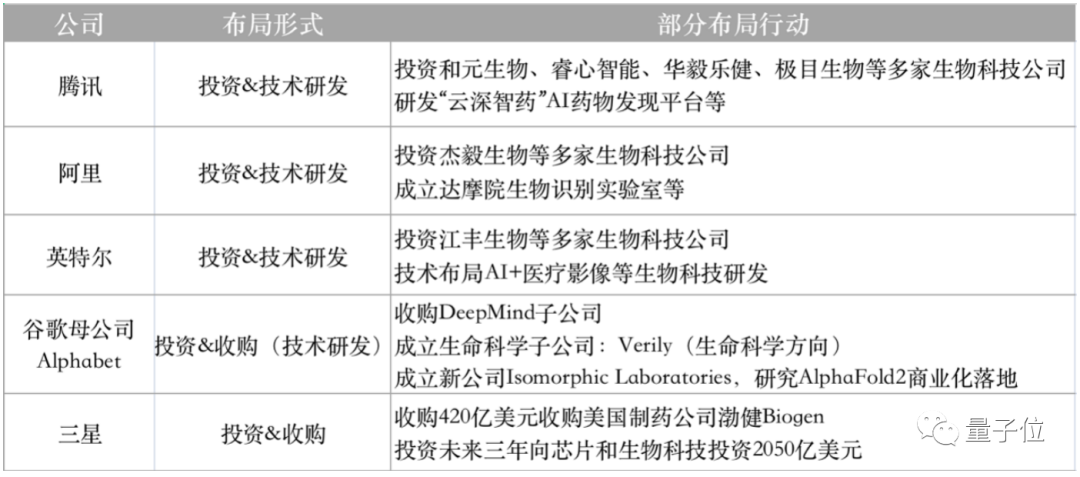
這也與當前所處的科技生長態(tài)勢有關——生物領域的發(fā)展,恰好趕上了數(shù)據(jù)爆炸的時代,以及AI對過去研究方式的變革。
從技術應用來看,典型代表之一就是AI+新藥研發(fā)。
數(shù)據(jù)驅(qū)動導向的深度學習技術,給傳統(tǒng)的新藥研發(fā)帶來了大量的潛力。
制藥領域有一個知名的反摩爾定律:每隔9年,投資10億美元產(chǎn)出的上市新藥就減少一半。更為常見的是,首創(chuàng)藥物(First-in-Class)占獲批新藥總數(shù)量不足一半。
相比之下,利用AI則能在包括用ADMET來做性質(zhì)預測以篩選藥物等在內(nèi)的步驟中,節(jié)省大量的人力和物力,包括輝瑞、阿斯利康等傳統(tǒng)藥企,也開始紛紛增加AI研發(fā)投入、或是尋求與AI公司進行合作。
而AI+新藥研發(fā),還只是生物科技爆發(fā)中的一小部分技術應用。
放大到整個行業(yè)來看,科技對生物領域的促進,本身就正在成為不可抵擋的趨勢之一。
此前量子位智庫發(fā)布的“2021十大前沿科技趨勢”中,與生物相關的技術突破就占據(jù)了接近一半:
除了利用AI助力新藥研發(fā)以外,還有CRISPR基因編輯、侵入式腦機接口的落地應用、利用AI預測蛋白質(zhì)結構的模型AlphaFold2。

從產(chǎn)業(yè)來看,像百度這樣的AI公司重倉研究,反過來又說明了AI給生物科技領域帶來的潛力和價值。
2018年開始,百度就研發(fā)RNA二級結構預測等算法,到后來李彥宏親自創(chuàng)立百圖生科公司,再到與傳統(tǒng)藥企賽諾菲等合作進行算法研究落地;
李彥宏也不止一次強調(diào)過自己對這一領域的看好:
依靠生物計算引擎,能夠有效利用大量的生物數(shù)據(jù),把藥物發(fā)現(xiàn)的“大海撈針”變成“按圖索驥”。

不止百度。春江水暖總是技術公司先知。
谷歌母公司Alphabet就在不久前,宣布成立一家新公司Isomorphic Laboratories,研究如何將AlphaFold2在AI+新藥研發(fā)方向的能力進行商業(yè)化落地。
OpenAI也在嘗試利用AI模型,訓練出能夠診斷疾病和預測復雜蛋白質(zhì)結構等能力的復雜系統(tǒng)……
AI+生物科技,正在成為產(chǎn)業(yè)界落地趨勢的一種新“共識”。
21世紀是生物的世紀。誠不我欺?
論文鏈接:
??https://www.nature.com/articles/s42256-021-00438-4??
GitHub鏈接:https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/pretrained_compound/ChemRL/GEM




























