













MIT斯坦福Transformer最新研究:過度訓練讓中度模型「涌現」結構泛化能力
對于人類來說,句子是分層的。
句子的層次結構對于表達和理解都相當重要。
但是在自然語言處理中,之前的研究認為,在泛化到新的結構輸入時,以Transformer為代表的神經序列模型似乎很難有效地捕捉到這種句子的層級結構。
但是斯坦福和MIT的研究人員在最近的研究中發現。
如果對Transformer類的模型進行長時間的訓練之后,它能獲得這種結構性的泛化能力。
研究人員將這種現象稱為:結構頓悟(Structural Grokking,SG)
Grokking這個詞是一個作家在書中造出來的詞,中文大概翻譯成「頓悟」。
微博網友木遙老師把這個詞解釋為:一個高度復雜的神經網絡在漫長的訓練期內一直只能記住訓練樣本的信息,幾乎沒有泛化能力,但到了某一刻,它的泛化水平忽然跳了出來,而且非常完美。
可以想象成一個神經網絡經歷了一個「aha moment」,像是內部的某個齒輪忽然對上了一樣。

論文地址:https://arxiv.org/abs/2305.18741
研究人員在不同的數據集中發現,SG在模型的深度(Model Depth)上呈現倒U縮放。
中深度模型的泛化能力比非常深和非常淺的模型都要好。
總體上看,如果能對模型進行更多的擴展訓練,普通的Transformer能夠展現出層級結構。
背景
在之前的類似研究中,研究人員認為Transformer在分層級泛化測試中是失敗的。
Transformer模型中的分層級結構
為了了解給定的模型是否對獲取層次結構有偏見,斯坦福的研究人員按照之前的實驗流程,評估了模糊任務上訓練的模型的泛化性。
在這些任務中,訓練數據與“層次規則”和“非層次規則”相一致的。
為測試是否獲得了分層規則,研究人員在一個單獨的分布外測試集上測試泛化性。
頓悟(Grokking)
之前的研究表明,在小型算法數據集上會出現頓悟現象,他們發現在訓練性能飽和后的很長時間里,模型測試性能繼續提高。
因此研究人員就假設存在一個類似的結構頓悟,在域內驗證性能飽和后很長時間內,模型對于分層結構依然可以繼續頓悟。
因此,分層泛化可以通過擴展訓練繼續提高。
實驗
數據集
研究人員的目標是理解transformer中的分層泛化 , 使用了來自之前研究中的兩個數據集,并在一個簡單的括號跟蹤任務上進行了評估。
我們評估了Dyck20,10中結構上未觀察到的字符串的泛化能力,以下圖為例。

模型
研究人員訓練了有{2,4,6,8,10}層的transformer語言模型。
對于每個深度,研究人員用10個隨機種子來訓練模型,300k steps。(Dyck為400k)
給定輸入句子(或在Dyck的情況下前綴),研究人員在測試時從模型中解碼。
對于Dyck,研究人員報告準確性是通過在給定語言的輸入前綴的情況下,通過對右括號進行排名來生成正確的右括號類型。
和之前已經進行的研究類似,對于Question-Formation,研究人員報告解碼問題的第一個單詞的準確性。
對于Tense-Inflection,研究人員報告的是目標動詞詞形變化正確的測試輸入的分數。
主要結果
Transformers展現出了結構頓悟。
研究人員在下圖中展示了在所有數據集上使用最佳模型深度所獲得的結果。
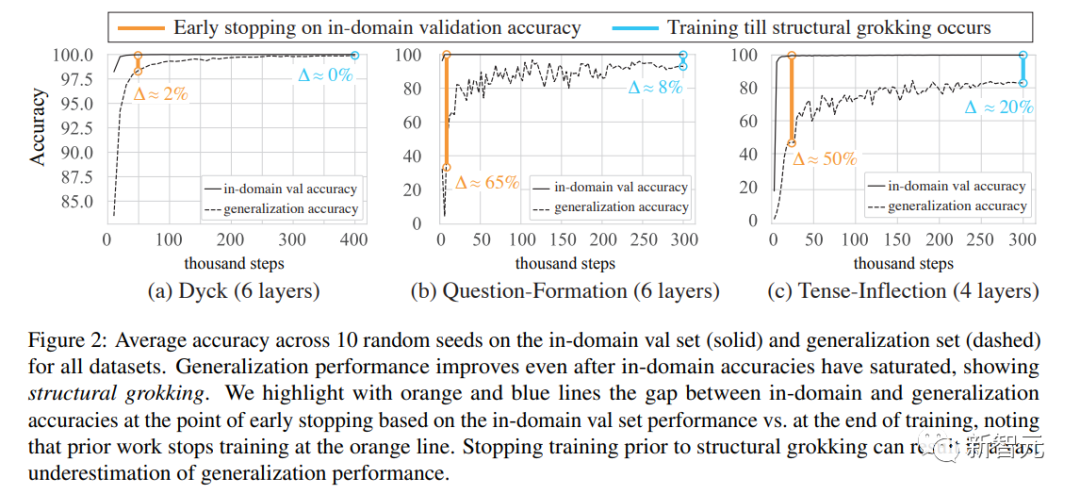
他們發現了明確的結構頓悟證據:在各個數據集上,在分布內準確率飽和之后的訓練步驟中,泛化性能得到改善,有時甚至接近完美的準確率。
提前停止是有害的
接下來,研究人員將通過在域內驗證準確率上進行提前停止而獲得的泛化準確率,與更長的訓練流程(如下圖)的泛化準確性進行了比較。
提前停止會導致泛化性能被嚴重低估。
例如,在Question-Formation和Tense-Inflection兩個任務上,平均泛化性能從不到40%、不到50%提高到分別不到90%、不到80%。
倒U形分布
在Question-Formation和Tense-Inflection任務中,研究人員從2層到10層逐漸增加深度進行模型訓練。
對于每個深度,在下圖中報告了最終泛化準確率超過80%的種子數(10個種子中的比例)。
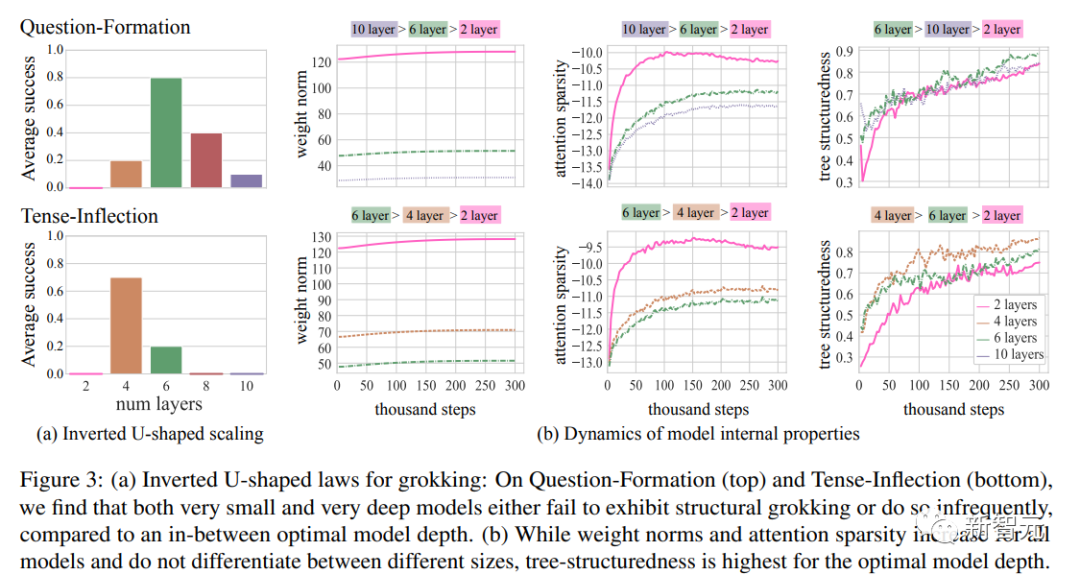
他們發現了一個倒U形的分布狀態——非常淺和非常深的模型效果不佳,而大多數種子在中等深度的模型中表現出較好的泛化性能。
這也可以解釋為什么之前的研究要么使用非常淺的模型(1-3層的Transformer),要么使用非常深的模型(Mueller等人論文中的12層Transformer),都無法很好地泛化。
分析
鑒于結構頓悟僅在一部分模型架構中發生,研究人員能否確定它何時發生(或預測何時會發生)?
幾個模型內部屬性與結構性理解或Transformer中出現的新興分層結構或許有關。
Weight Norms
最近的研究將認為參數權重的L2 norm是結構頓悟的重要量。
但總體上來說,訓練過程中范數(Norms)增長被作為神經網絡泛化的關鍵因素之一進行了研究。
注意力稀疏性
Merrill等人(2021年)證明了Transformer中的范數增長導致了注意力的飽和,這是新興語言結構的重要特性(Merrill等人,2022年)。為了衡量fLθ的注意力稀疏性,我們計算了所有分布{apk}的負均熵。
樹結構
之前有研究展示了樹結構編碼器表現出接近完美的分層泛化。
雖然Transformer相對較為自由,但最近的證據表明,當在語言數據上進行訓練時,它們隱含地實現了(近似)樹結構計算。
而且,之前研究中樹投影方法精確地描述了Transformer對輸入進行的內部計算可以用樹結構神經編碼近似的程度,為任何Transformer提供了樹結構度量分數(tscore),并提供了一個在輸入字符串上最佳近似其計算的二叉樹。
為了評估這些樹是否與人類的句法概念相對應,我們還將恢復的樹與黃金標準樹進行比較。
結果
在Question-Formation和Tense-Inflection任務中,研究人員通過每隔3k steps更新計算一次這些量的方式來描述權重范數(通過層數統一化來比較不同模型深度)、注意力稀疏性和樹結構性的動態變化情況。
對于依賴于數據的屬性,如注意力稀疏性和樹結構性,我們從訓練數據中隨機抽取了10k個樣例。
研究人員在下圖中繪制了這些量在最小模型、最大模型(其中至少有一個運行顯示成功的結構頓悟)以及最佳模型深度的情況。
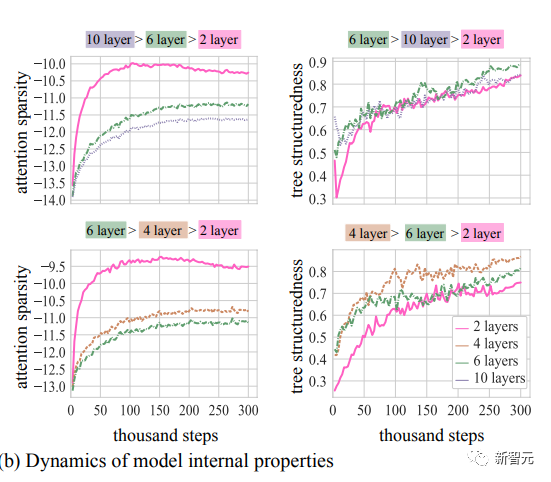
樹形結構是最佳的模型
在兩個數據集的所有模型設置中,權重范數和注意力稀疏性都會增長。
然而,僅憑這些屬性本身無法預測淺層和深層模型的失敗 - 淺層模型學習到了最稀疏的解以及具有最大權重范數的解,但從未進行分層泛化。
正如之前的研究中所指出的,tscore隨時間的推移對于所有模型都有所改善,表明隨著時間的推移,樹結構性增加。
對于這兩個數據集,與深層和淺層模型相比,“最佳”模型學習到了最多的樹結構解。
在算法任務中,結構性理解“與嵌入中結構的出現相吻合”。
類似地,在語言任務中,我們發現結構性理解與樹狀內部計算的出現相吻合。
Transformer在誘導結構方面表現出驚人的效果
從下圖的tparseval的動態變化中,研究人員注意到所有模型,無論它們是否進行泛化,都學習到了接近于真實句法的結構,有時表現優于右分支基線。
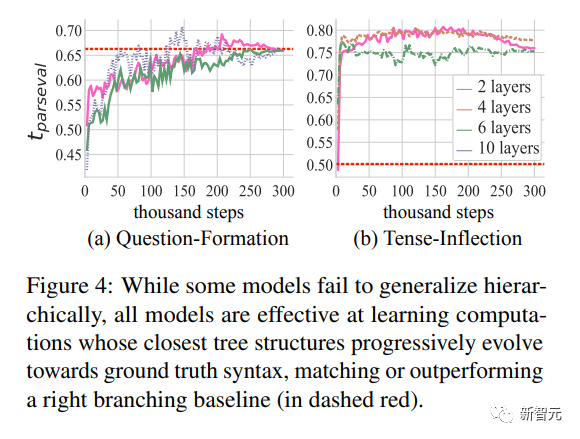
之前的研究認為,只有樹結構編碼器根據正確的句法分析樹進行結構化時才能進行泛化。
研究人員發現所有Transformer都學習到了正確的樹結構,但只有最具樹結構性的模型表現出最好的泛化能力。
結論
這項研究表明,通過結構頓悟機制,Transformer能夠展現出對結構敏感的“分層泛化”。
它們的整體學習行為逐漸從記憶(領域內高準確率,領域外準確率較差)向泛化(領域內和領域外準確率高)轉變。
雖然研究人員在相對較小的數據集和小型模型上展示了這種行為,但這些結果可能具有更廣泛的意義。
因為已經證明長時間的訓練即使對于規模龐大的語言建模和組合泛化任務也有幫助。
結構頓悟在“中等規模”的模型深度最常發生,而非常淺和非常深的模型則無法展現出這種行為。
雖然以往與Transformer中的語言泛化相關的屬性,如權重范數和注意力稀疏性,不能區分好的架構和壞的架構,但Transformer的功能性樹結構可以很好地預測最佳模型深度。
雖然Transformer架構存在一些明顯的限制(例如無法實現無限遞歸),但研究人員的結果表明它可能具有比以前認為的更強的歸納偏好:通過充分的訓練,Transformer能夠表示分層的句子結構并利用這種結構進行正確的泛化。






























