三張圖片生成一個手辦3D模型!南加州大學華人博士提出新模型NeROIC,更真實!
隨著深度學習的加入,計算機圖形學又產生了很多新興領域。 神經渲染(Neural Rendering)技術就是利用各種深度神經網絡進行圖像合成,通過自動化的流程,能夠節省大量從業人員的時間和精力。 例如給定幾張不同角度拍攝的二維圖像,神經渲染模型能夠生成一個三維模型,而無需任何人工的介入。

在現實場景中,可能你會有一堆手辦的照片,如果按照傳統的方式都建成3D模型,那需要耗費的工作量,想想都頭禿。

神經渲染技術可以很容易地把這些模型輸入到計算機中,并讓機器理解這些照片中的物體在三維空間中的實際形狀和物理狀態。 對于人來說,這項任務可以說是十分容易了,因為人眼了解現實世界,也知道圖像的深度,但對于只能看到像素的計算機來說,神經渲染模型的設計還是很有挑戰的。

除了拍手辦以外,游戲從業者還可以利用神經渲染技術,簡單地拍攝一些物體的照片,合成3D模型,然后就可以制作出一個完美的游戲場景。 但模型如果只是看起來準確,形狀更貼合照片,還遠遠不夠,因為一旦把合成后的物體放入到新場景中,因為光影的不同,合成模型在新環境中顯得格格不入,所以一下子就會「露餡」。 針對這個問題,來自SnapChat和南加州大學的研究人員提出了一個新模型NeROIC,能夠解決從圖像中創建虛擬物體所帶來的照明和真實性的問題。

論文地址:https://arxiv.org/pdf/2201.02533.pdf 新模型建立在神經輻射場(neural radiance field)的基礎上,神經輻射場廣泛用于重構中,例如NeRF等模型。但神經輻射場需要在相同的理想條件下才能夠完美建模,但這并不符合真實場景的需求。 研究人員從NeRF模型出發來改進。NeRF神經網絡的訓練輸入為一張圖片,用來推測每個像素的顏色、不透明度和輻射度,并猜測物體中沒有出現在二維圖像中的小部分的缺失像素。但這種方法對大面積的缺失部分或不同的照明條件下沒有作用,因為它只能從輸入的圖像中進行插值。所以新的模型需要更多的信息來推斷,并對某個地方應該出現的東西或這些像素在這種光照下應該是怎樣的做出假設等。
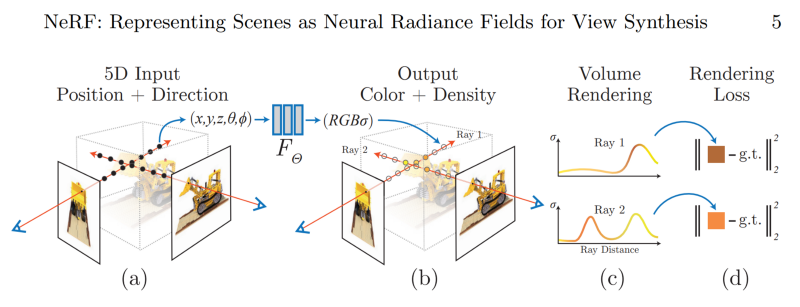
許多方法都是在NeRF的基礎上解決這個問題,但新模型總是需要用戶提供更多的輸入條件,這也并不符合實際場景的需求,并且在很多情況下用戶也并不清除這些數據,特別是當其他人想建立一個好的數據集來訓練模型時,就更加困難了。 總的來說, 之前的NeRF類模型并沒有真正理解物體,也沒有理解物體所處的環境。 所以真正要解決的事又回到照明問題上了。
研究人員的目標是在網絡圖像(online images)中也能使用這種新模型架構,也就是說,具有不同燈光、相機、環境和姿勢的圖像,新模型都應該有能力來處理,這也是NeRF難以做到的真實性。 除了需要物體本身的圖像之外,他們唯一需要的東西是一個粗略的前景分割器和對攝像機參數的估計,這兩個信息都可以通過其他可用的模型獲得。前景分割基本上只是一個遮罩(mask),可以告訴模型用戶感興趣的物體在圖像上的位置。

新模型所做的不同之處在于,他們將物體的渲染與輸入圖像中的環境照明分開,將這兩個任務獨立出來,在兩個階段內完成。
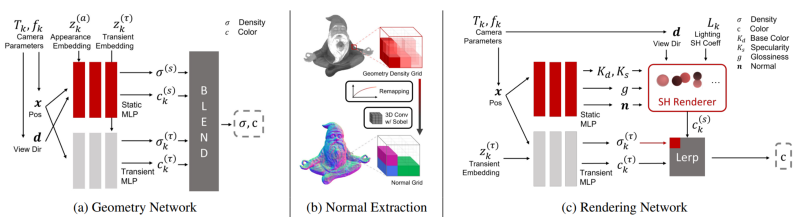
首先,(a)網絡獲取的是物體的幾何形狀,這是與NeRF最相似的部分,文中稱為幾何網絡(Geometry Network)。它將輸入圖像、分割遮罩和相機參數估計結合起來建立一個輻射場,并找到每個像素的密度和顏色的猜測結果,整體流程和NeRF基本相同,但新模型需要適應輸入圖像中不同的照明條件。 這種差異來源于模型中的兩個分支,使得模型能夠將靜態內容與攝像機或陰影等變化的參數分開,從而能夠訓練模型如何正確地將靜態內容與其他不需要的參數(如照明)隔離開來,但只有這些還無法完美還原模型的空間結構。 在(b)中,研究人員將從這個學到的密度場(density field)中估計表面法線(surface normals)作為物體的形狀紋理。換句話說,在(a)中產生的結果能夠幫助找到物體對光線的反應。 在這個階段可以找到物體的無偏材料屬性(unbiased material properties),或者是使用一個帶有Sobel kernel的三維卷積得到對屬性的估計值。整個過程基本上就是一個filter,可以在三維空間中使用它來找到所有的物體邊緣和確定邊緣的銳利程度,可以提供關于物體的不同質地和形狀的基本信息。

階段(c)是調整模型學到的幾何體,并優化剛剛使用這個渲染網絡產生的法線。 同樣包含兩個分支,一個是材料(material),另一個是照明(lighting)。他們將使用球面諧波(spherical harmonics)來表示照明模型,并在訓練中優化其系數。 研究人員在論文中解釋稱,球面諧波在這里可以被用來代表一組定義在球面上的基礎函數,定義在球體表面的每個函數都可以寫成這些球面諧波的總和。這種技術經常被用于計算3D模型的照明。 這種方法能產生高度逼真的陰影和陰影,而且開銷相對較小。簡而言之,它將簡單地減少需要估計的參數數量,但保持相同的信息量。 因此,與其從頭開始學習如何為整個物體渲染適當的光照,文中提出的新模型將轉而學習正確的系數以用于估計每個像素表面的光照,將問題簡化為幾個參數。 另一個分支被訓練來改善物體的表面法線,遵循同樣的技巧,使用標準的Phong BRDF將基于幾個參數找到物體的材料屬性模型。 最后渲染和照明兩個分支被合并,以預測每個像素的最終顏色。 文章中的實驗部分和NeRF模型進行對比,評價指標為峰值信噪比(PSNR)和結構相似性指數測量(SSIM)平均分。
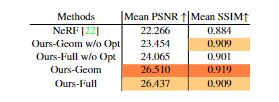
考慮到測試圖像的照明條件是未知的,研究人員從同一場景下的另一張訓練圖像中挑選照明參數(嵌入式矢量或SH系數),并凍結網絡,用隨機梯度下降優化器對照明參數進行1000步優化。 實驗結果中可以看到,新模型以相當大的優勢勝過了NeRF,并且在實際效果上,也比NeRF產生的結果更加一致和平滑。

文章的第一作者是匡正非,南加州理工的博士生,主要研究領域包括神經渲染、3D重構、人類數字化和動畫、基于物理的模擬等,2019年本科畢業于清華大學。
?
 ?
?