













華為諾亞開源首個億級中文多模態數據集,填補中文NLP社區空白
在大數據上預訓練大規模模型,對下游任務進行微調,已經成為人工智能系統的新興范式。BERT 和 GPT 等模型在 NLP 社區中越來越受歡迎,因為它們對廣泛的下游任務甚至零樣本學習任務具有很高的可遷移性,從而產生了 SOTA 性能。最近的工作,如 CLIP、ALIGN 和 FILIP 進一步將這一范式擴展到視覺語言聯合預訓練 (VLP) 領域,并在各種下游任務上顯示出優于 SOTA 方法的結果。這一有希望的方向引起了行業和研究人員的極大關注,將其視為通向下一代 AI 模型的途徑。
促成 VLP 模型成功的原因有兩個。一方面,更高級的模型架構(如 ViT/BERT)和訓練目標(如對比學習)通常能夠提升模型泛化能力和學得表示的穩健性。另一方面,由于硬件和分布式訓練框架的進步,越來越多的數據可以輸入到大規模模型中,來提高模型的泛化性、可遷移性和零樣本能力。在視覺或者語言任務中,先在大規模數據(例如圖像分類中的 JFT-300M、T5 中的 C4 數據集)上預訓練,之后再通過遷移學習或者 prompt 學習已被證明對提高下游任務性能非常有用。此外,最近的工作也已經顯示了 VLP 模型在超過 1 億個來自網絡的有噪聲圖像 - 文本對上訓練的潛力。
因此,在大規模數據上預訓練的 VLP 模型的成功促使人們不斷地爬取和收集更大的圖文數據集。下表 1 顯示了 VLP 領域中許多流行的數據集的概述。諸如 Flickr30k、SBU Captions 和 CC12M 等公開可用的視覺語言(英語)數據集的樣本規模相對較小(大約 1000 萬),而規模更大的是像 LAION-400M 的數據集。但是,直接使用英文數據集來訓練模型會導致中文翻譯任務的性能大幅下降。比如,大量特定的中文成語和俚語是英文翻譯無法覆蓋的,而機器翻譯往往在這些方面會帶來錯誤,進而影響任務執行。
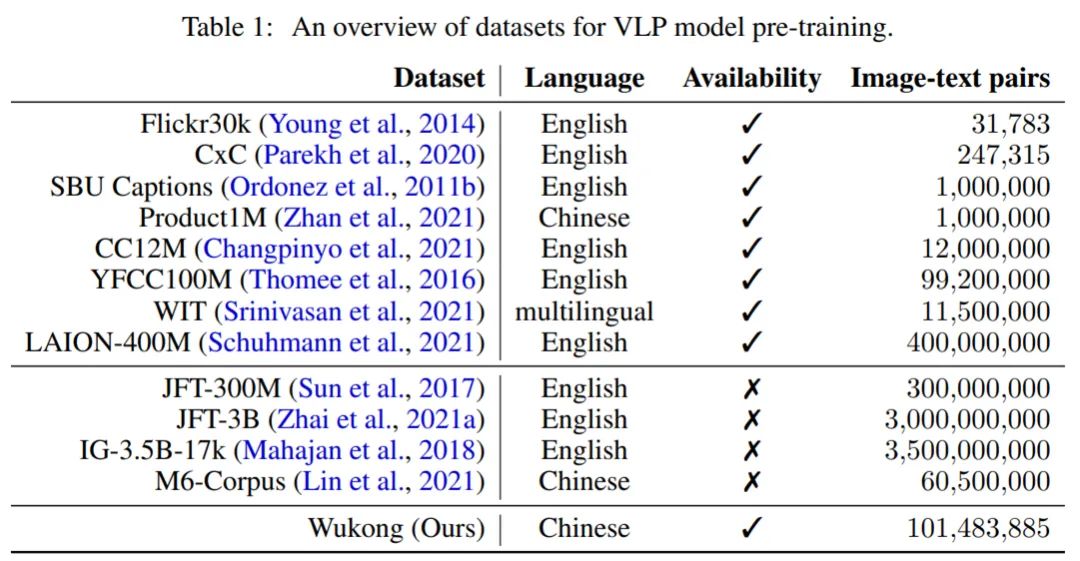
目前,社區缺乏大規模公開可用的中文數據集,不僅導致社區發展受阻,而且每項工作都使用一個私密的大型數據集來實現,達到一個其它工作無法公平比較的驚人性能。
為了彌補這一差距,華為諾亞方舟實驗室的研究者發布了一個名為「悟空」的大型中文跨模態數據集,其中包含來自網絡的 1 億個圖文對。為了保證多樣性和泛化性,悟空數據集是根據一個包含 20 萬個高頻中文單詞列表收集的。本文還采用基于圖像和基于文本的過濾策略來進一步完善悟空數據集,使其成為了迄今為止最大的中文視覺語言跨模態數據集。研究者分析了該數據集,并表明它涵蓋了廣泛的視覺和文本概念。

- 論文地址:https://arxiv.org/pdf/2202.06767.pdf
- 數據集地址:https://wukong-dataset.github.io/wukong-dataset/benchmark.html
研究者還進一步發布了一組使用不同架構(ResNet/ViT/SwinT)和不同方法(CLIP、FILIP 和 LiT)大型預訓練模型。本文的主要貢獻如下:
- 發布了具有 1 億個圖文對的大規模視覺和中文語言預訓練數據集,涵蓋了更全面的視覺概念;
- 發布了一組使用各種流行架構和方法預訓練好的大規模視覺 - 語言模型,并提供針對已發布模型的全面基準測試;
- 發布的預訓練模型在數個中文基準測試任務,例如由 17 個數據集組成的零樣本圖像分類任務和由 5 個數據集組成的圖像文本檢索任務,表現出了最優性能。
「悟空」數據集
研究者構建了一個名為悟空的新數據集,該數據集包含從網絡收集的 1 億個圖文對。為了涵蓋足夠多樣的視覺概念,悟空數據集是由包含 20 萬個詞條的查詢列表里收集的。這個基礎查詢列表取自 Yan Song 等人的論文《Directional Skip-Gram: Explicitly Distinguishing Left and Right Context for Word Embeddings》,然后根據華為的海量新聞文本語料庫中出現的中文單詞和短語的頻率進行過濾后所得。
查詢列表建好后,研究者在百度圖片搜索每個查詢,以獲取圖片 URL 列表和相應的標題信息。為了保持不同查詢結果間的平衡,他們每個查詢最多搜索 1000 個樣本。然后使用先前獲得的圖像 URL 下載圖像,最終共收集了 1.66 億個圖文對。然后按照慣例,研究者通過下文的一系列過濾策略來構建最終的悟空數據集。下圖 2 顯示了悟空數據集中的一些樣本。

基于圖像的過濾
研究者首先根據圖像的大小和長寬比對數據進行過濾。只保留長或寬超過 200 像素且長寬比不超過 3 的圖像。這種方式過濾掉了太小、太高或太寬的圖像,因為這些圖像在預訓練期間經過上采樣和方形裁剪等圖像增強手段后,可能變成低分辨率。
基于文本的過濾
其次,為了使選擇的樣本具有對應圖像的高質量中文描述,研究者根據圖像所附文本的語言、長度和頻率對數據進行進一步過濾。具體來說,他們首先檢查了語言和長度,保留了包含至少一個但少于 32 個漢字的句子。同時還會丟棄無意義的圖像描述,例如「000.jpg」。之后,與太多圖片配對的文字通常與圖片內容無關,例如「查看源網頁」(View source page)、「展開全文」(Expand text)、「攝影部落」(Photography community)。實際中,研究者將此閾值設置為 10,即丟棄掉在收集的整個語料庫中出現超過 10 次的圖文對。
為了保護文本中出現的個人隱私,研究者將人名替換為特殊標記「< 人名 >」,此外,他們還構建了一個中文敏感詞列表,包含敏感詞的圖文對也被丟棄。
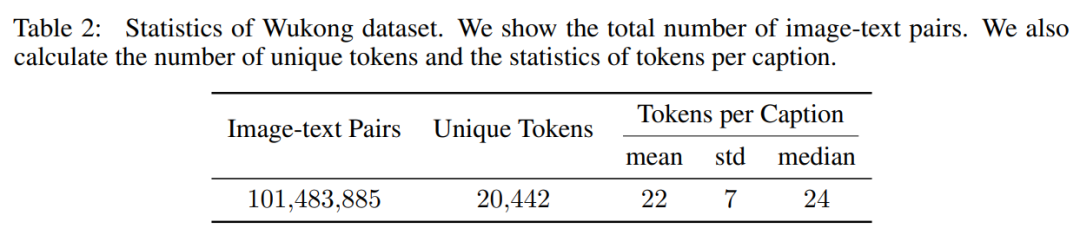
應用上述過濾策略后,研究者最終得到一個約 1 億對的數據集。下表 2 顯示了數據集的統計量:數據集文本中有 20,442 個唯一 token,每個描述中的平均 token 數為 22。
在下圖 3 中,研究者可視化了數據集中單詞(由一個或多個 token 組成)的分布。然后,他們使用中文文本分詞工具 Jieba 來截取單詞并構建數據集的詞云。

方法架構
文本 - 圖像聯合對齊
與最近經過充分驗證的方法類似,研究者采用了對比預訓練架構,如下圖 1 所示。他們使用一個帶有基于 Transformer 的文本和圖像編碼器的雙流模型。這兩個編碼器將文本和視覺輸入 token 轉換為相同維度的嵌入。在這個學習到的聯合嵌入空間中,研究者使用對比損失來鼓勵成對的圖像和文本具有相似的嵌入,而不成對的具有不同的嵌入。
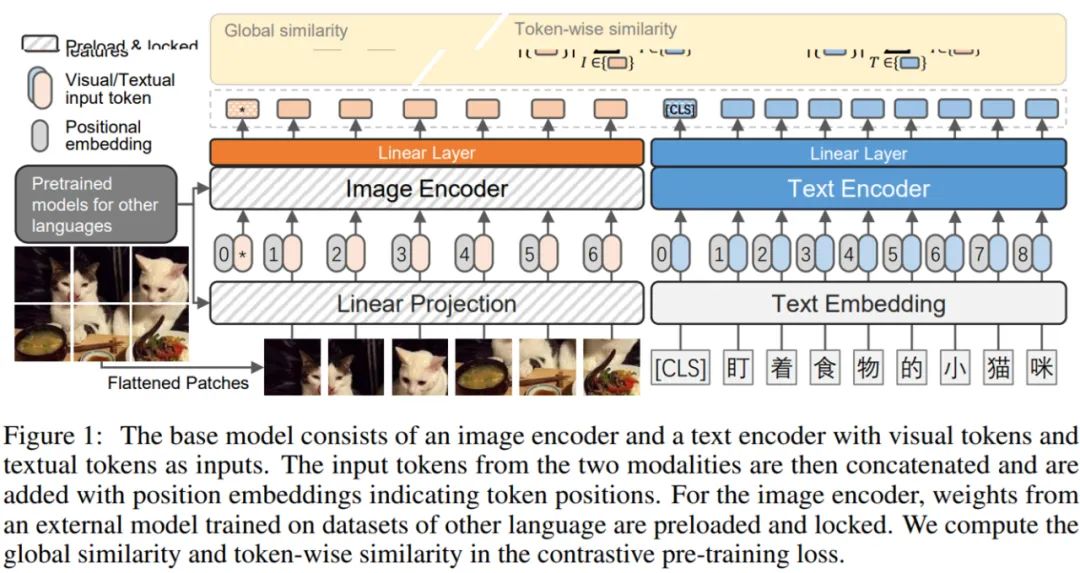
模型架構
由于視覺和文本模態的編碼器是解耦的,因此可以為這兩種模態探索不同的編碼器架構。研究者試驗了三種視覺編碼器變體(即 ResNet、Vision Transformer 和 Swin Transformer)以及一個單一的類 BERT 文本編碼器來訓練中文 VLP 模型。
預訓練目標
跨模態對比學習是一種從成對的圖像 - 文本數據中訓練模型的特別有效的方法,它可以通過區分成對和不成對的樣本同時學習兩種模態的表示。研究者遵循 FILIP(Yao 等人,2022)中的公式標記,使用
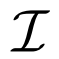
去定義圖像樣本集合,同時
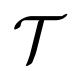
代表文本數據。給定一個圖像樣本
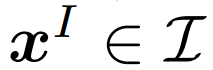
和一個文本樣本
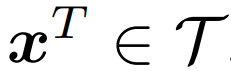
,該模型的目標是讓聯合多模態空間中的配對的圖像和文本表示接近,不配對的則遠離。
在這項工作中,研究者探索了兩種衡量圖像和文本之間相似度的方法。圖像和文本的學得表示分別標記為
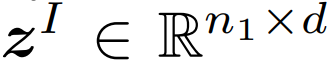
和
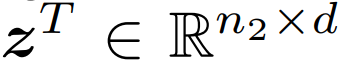
。這里,n_1 和 n_2 是每個圖片和文本中的(未填充的)詞 token 的數量。
LiT-tuning
研究者受到了最近提出的一種微調范式 LiT-tuning(Locked-image Text tuning)的啟發,該范式表明權重固定的圖像編碼器和可學習的文本編碼器在 VLP 模型中效果最好。他們在對比學習設置中也采用了同樣的方式,即只更新文本編碼器的權重,而不更新圖像編碼器的權重。
具體而言,研究者采用的 LiT-tuning 方法旨在教一個中文的文本編碼器從一個現有的圖像編碼器中讀取合適的表示,該圖像編碼器是在英文數據集上預訓練過。他們還為每個編碼器添加了一個可選的可學習線性變換層,它將兩種模式的表示映射到相同的維度。LiT-tuning 之所以效果很好,是因為它解耦了用于學習圖像特征和視覺語言對齊的數據源和技術(Zhai 等人,2021b)。并且,圖像描述器事先使用相對干凈或(半)手動標記的圖像進行了良好的預訓練。
研究者將這一想法擴展到多語言數據源,并嘗試將在英文數據源上預訓練的固定了的圖像編碼器和可訓練的中文文本編碼器對齊。此外,LiT-tuning 方法顯著加快了訓練過程并減少了內存需求,因為它不需要為視覺編碼器計算梯度。
實驗結果
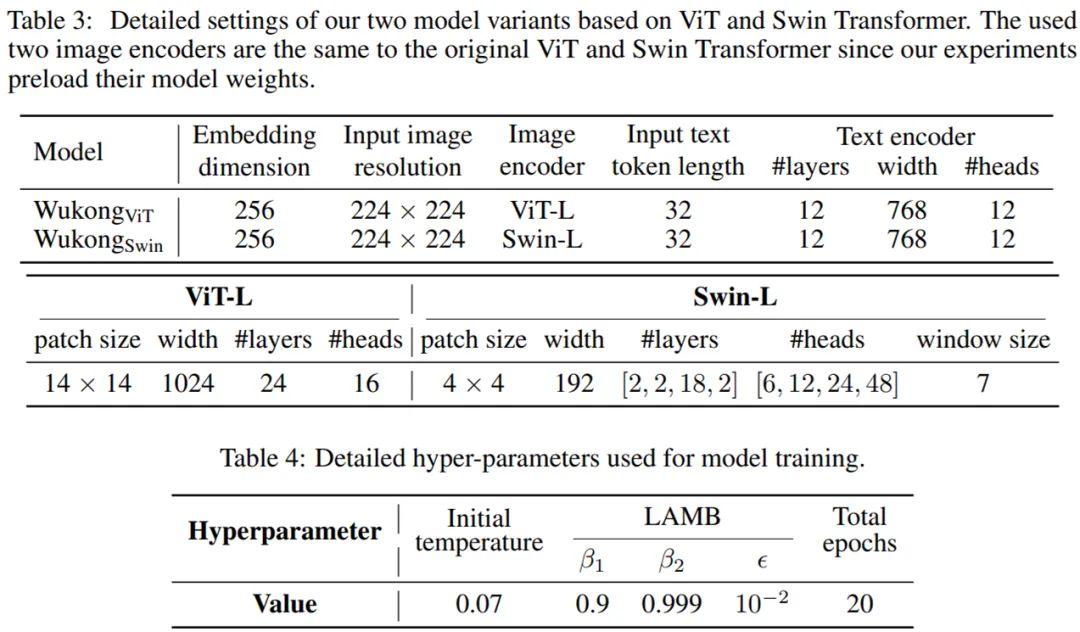
下表 3 描述了模型參數和視頻編碼器的細節。
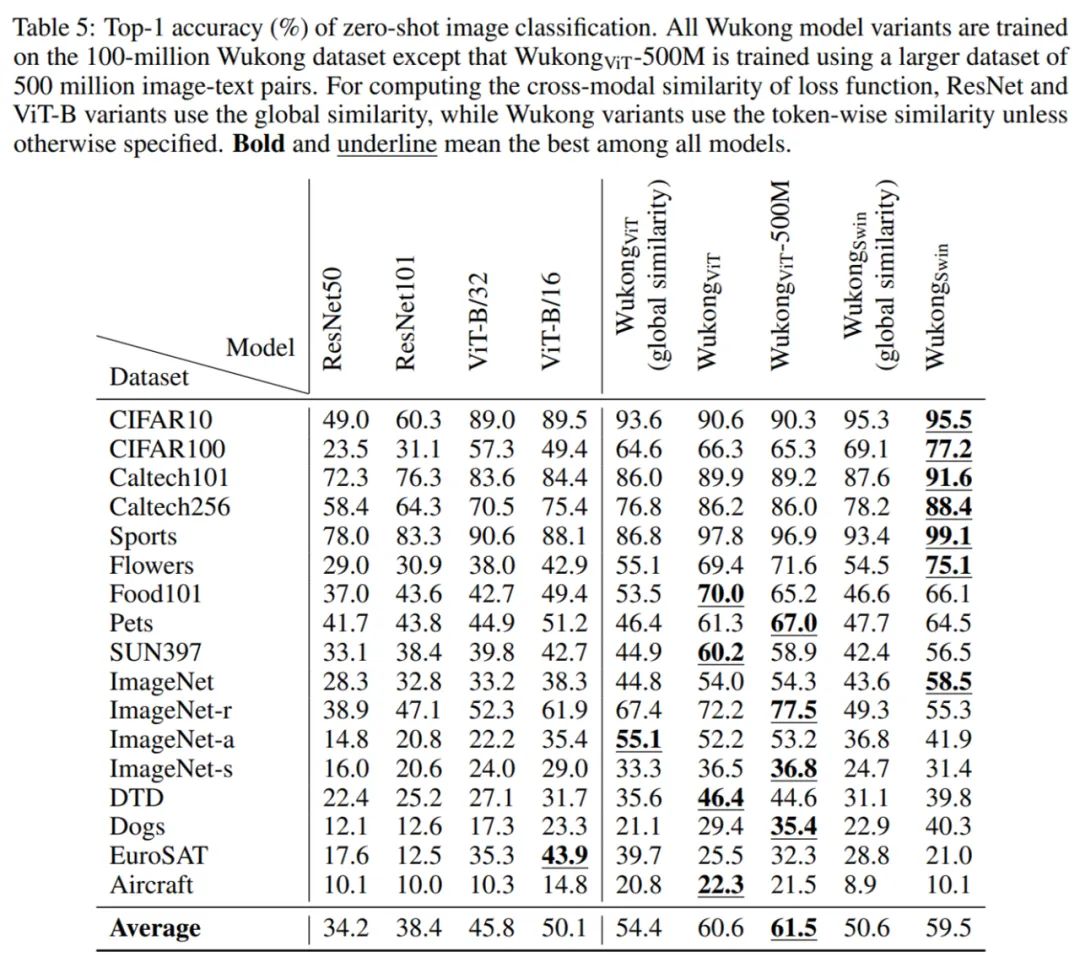
零樣本圖像分類。研究者在 17 個零樣本圖像分類任務上評估預訓練模型。零樣本圖像分類的結果如下表 5 所示。他們比較了使用不同視覺編碼器的多個 LiT -tuning 模型,即從 CLIP 或 Swin Transformer 加載現有的視覺編碼器并在訓練階段固定它們的權重。結果發現,使用 token 水平的相似度比使用全局相似度會帶來更顯著的改進。
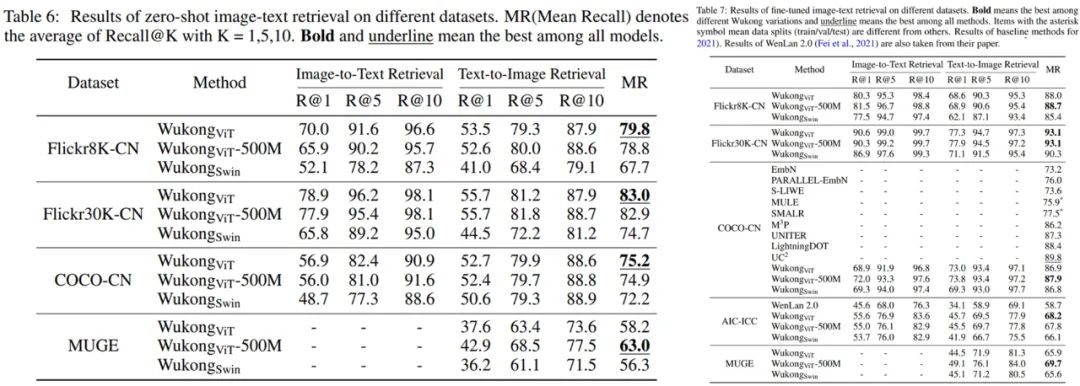
圖文檢索任務。研究者在兩個子任務,即以圖搜文和以文搜圖上做了評估。下表 6 和表 7 分別顯示了零樣本設定和可以微調的圖文檢索的結果。對于零樣本設置,相比其它模型,Wukong_ViT 在 4 個數據集中的 3 個上取得了最好的結果,而 Wukong_ViT-500M 在更大的 MUGE 數據集上取得了最好的結果。對于微調設置,Wukong_ViT-500M 則在除 AIC-ICC 之外的所有數據集上都取得了最好的結果,其中 Wukong_ViT 效果最好。
詞匯 - 圖塊對齊的可視化。研究者使用預訓練模型 Wukong_ViT 和 Wukong_Swin 進 行可視化。如圖 4 所示,其中可視化來自中文的 ImageNet 的六個標簽(即豆娘、救生艇、蜂鳥、平板手機、教堂和電風扇)的圖像。然后應用與 FILIP(Yao 等人,2022)相同的可視化方法來對齊文本和圖塊 token。
從下圖 4 中,研究者發現兩種模型都能夠預測目標物體的圖像塊。對于具有更多圖像塊的 Wukong_ViT,這種詞匯 - 圖塊對齊比 Wukong_Swin 更加細粒度。

























