













兩張照片就能轉視頻!Google提出FLIM幀插值模型
幀插值(Frame Interpolation)是計算機視覺領域的一項關鍵任務,模型需要根據給定的兩個幀,來預測、合成平滑的中間圖像,在現實世界中也有極大的應用價值。

常見的幀插值應用場景就是對提升一些幀率不夠的視頻,一些設備都配有專門的硬件對輸入視頻的幀率進行采樣,使得低幀率的視頻也可以在高幀率顯示上進行流暢地播放,不用「眨眼補幀」了。
隨著深度學習模型越來越強大,幀插值技術可以從正常幀率的錄像中合成慢動作視頻,也就是合成更多的中間圖像。
在智能手機不斷普及的情況下,數字攝影對幀插值技術也有了新需求。
正常情況下,我們拍照片通常都是在幾秒鐘之內連續拍下幾張照片,然后再從這些照片中選出更好的「照騙」。
這類圖片有一個特點:場景基本重復,主體人物只有少量的動作、表情變化。
如果在這類圖片下進行幀插值就會產生一個神奇的效果:照片動了起來,變成了視頻!通常情況下視頻都要比照片更加有代入感和時刻感。
是不是有種「實況照片」的感覺。

但幀插值的一個主要問題就是沒辦法有效地處理大型場景的運動。
傳統的幀插值都是對幀率進行上采樣,基本上就是對近乎重復的照片進行插值,如果兩張圖片的時間間隔超過了1秒,甚至更多,那就需要幀插值模型能夠了解物體的運動規律,也是目前幀插值模型的主要研究內容。
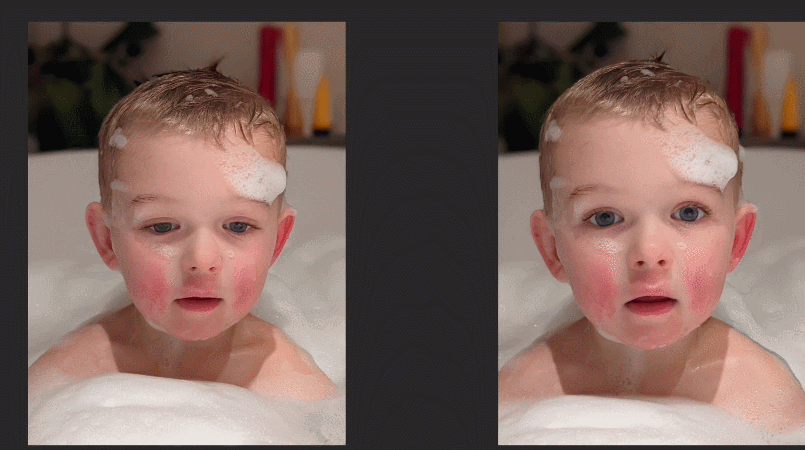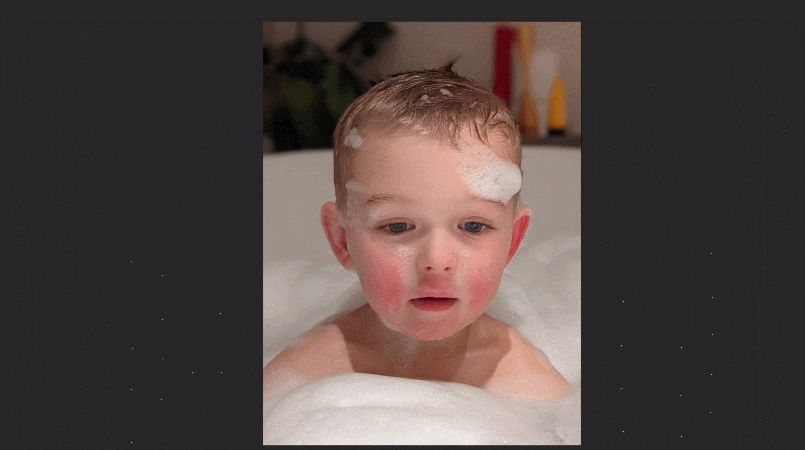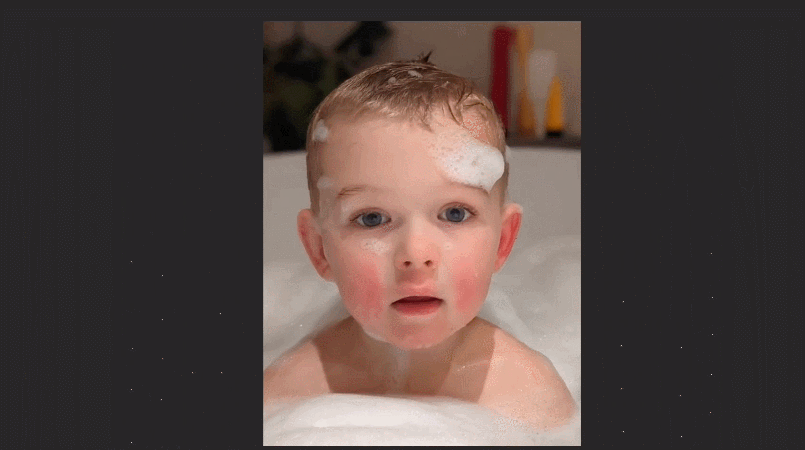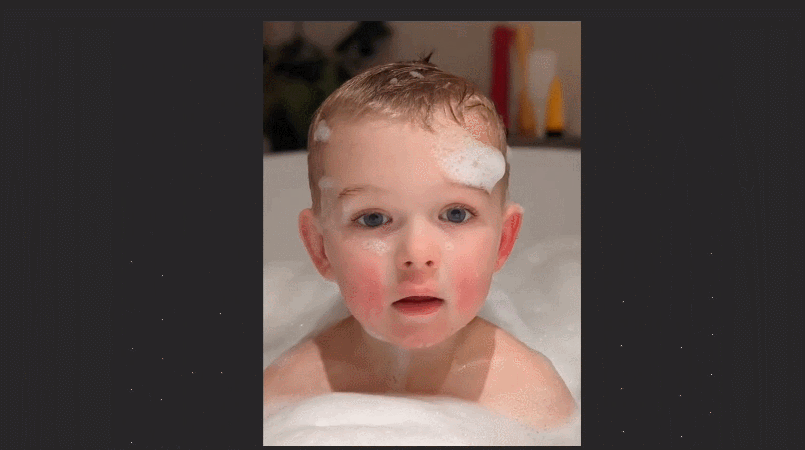
最近,Google Research團隊提出了一個新的幀插值模型FLIM,能夠對運動差別比較大的兩張圖片進行幀插值。

之前的幀插值模型往往很復雜,需要多個網絡來估計光流(optical flow)或者深度,還需要一個單獨的網絡專門用于幀合成。而FLIM只需要一個統一網絡,使用多尺度的特征提取器,在所有尺度上共享可訓練的權重,并且可以只需要幀就可以訓練,不需要光流或者深度數據。
FLIM的實驗結果也證明了其優于之前的研究成果,能夠合成高質量的圖像,并且生成的視頻也更連貫。代碼和預訓練模型都已開源。

論文地址:https://arxiv.org/pdf/2202.04901代碼地址:https://github.com/google-research/frame-interpolation
模型架構
FLIM模型的架構中包含三個主要的階段。
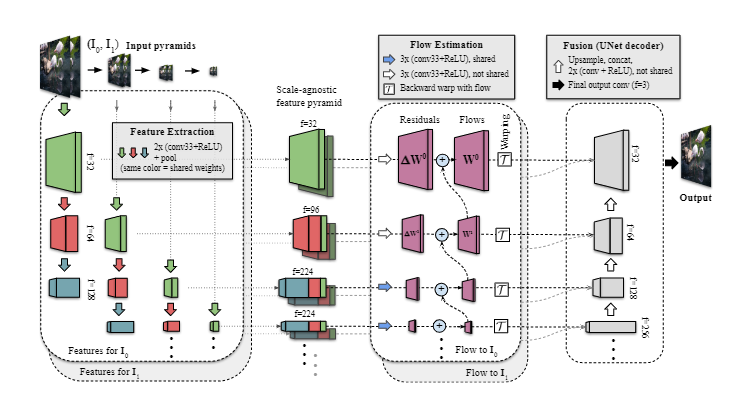
1. 尺度無關的特征抽取(scale-agnostic feature extraction)
FLIM的特征抽取器的主要特點就是在流預測階段(flow prediction stage)權重共享,能夠同時在粗粒度和細粒度的分辨率下得到權重。
首先對兩個輸入圖像創建一個圖像金字塔,然后在每層圖像金字塔使用一個共享的UNet編碼器構建特征金字塔,并且使用卷積層抽取了4個尺度的特征。 需要注意的是,在同一個深度的金字塔層級上,都使用相同的卷積權重以創建兼容的多尺度特征(compatible multiscale features)。
特征提取器的最后一步通過連接不同深度但空間維度相同的特征圖,構建了尺度無關的特征金字塔。最細粒度的特征只能聚合一個特征圖,次細粒度是兩個,其余的可以聚合三個共享特征圖。
2. 運動/流估計(motion/flow estimation)
提取特征金字塔后,需要用它們來計算每個金字塔的雙向運動,和之前的研究相同,從最粗粒度的一層開始進行運動估計。與其他方法不同的是,FLIM從中間幀到輸入,直接預測面向任務的流。
如果按照常規的訓練方法,使用ground truth光流來計算兩個輸入幀之間的光流是無法實現的,因為無法從尚待計算的中間幀預測光流。但在端到端的幀插值系統中,網絡實際上已經能夠基于輸入幀和對應的特征金字塔很好地預測了。
所以在每個層級上計算面向任務的光流就是從更粗的粒度上預測的殘余和上采樣的流之和。 最后,FLIM在中間時間t創建一個特征金字塔。
3. 融合:輸出結果圖像(fusion)
FILM的最后階段在每個金字塔層級處將時間t處的尺度無關的特征圖和雙向運動連接起來,然后將其送入UNet-like解碼器以合成最終的中間幀。
在損失函數的設計上,FLIM只使用圖像合成損失(image synthesis losses)來監督訓練最終的輸出,沒有在中間階段使用輔助的損失項。
首先使用一個L1重構損失,最小化插入幀和標準幀之間像素級RGB的差別。但如果只用L1損失,生成的插入幀通常都是比較模糊的,使用其他相似的損失函數訓練也會產生類似結果。
所以FLIM添加了第二個損失函數感知損失(perceptual loss)來增加圖像的細節,使用VGG-19高級別特征L1正則表示。由于每層的感受區,感知損失在每個輸出像素周圍的小范圍內強制執行結構相似性,實驗也證明了感知損失有助于減少各種圖像合成任務中的模糊偽影(blurry artifacts)。
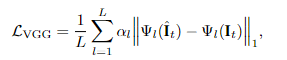
第三個損失為風格損失(Style loss),也稱為Gram矩陣損失,能夠進一步擴大VGG損失中的優勢。
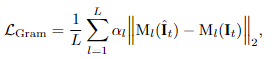
FLIM也是第一個將Gram矩陣損失應用于幀插值的工作。研究人員發現這種損失能有效地解決圖像的銳度,以及在不透明的情況下保留圖像細節,還能夠在具有大運動量的序列中消除干擾。 為了達到高基準分數以及高質量的中間幀合成,最終的loss同時使用三個損失加權求和,具體每個loss的權重由研究人員經驗性地設置。在前150萬輪迭代的權重為(1, 1, 0),在后150萬輪迭代的權重為(1, 0.25, 40) ,超參數通過grid search自動調參獲得。 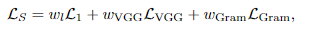
實驗部分
研究人員從指標量化和生成質量兩方面來評估FLIM網絡。 使用的數據集包括Vimeo-90K , UCF101 和 Middle- bury,以及最近提出的大運動數據集 Xiph。
研究人員使用Vimeo-90K作為訓練數據集。 量化指標包括峰值信號噪聲比(PSNR)和結構相似性圖像(SSIM),分數越高代表效果越好。
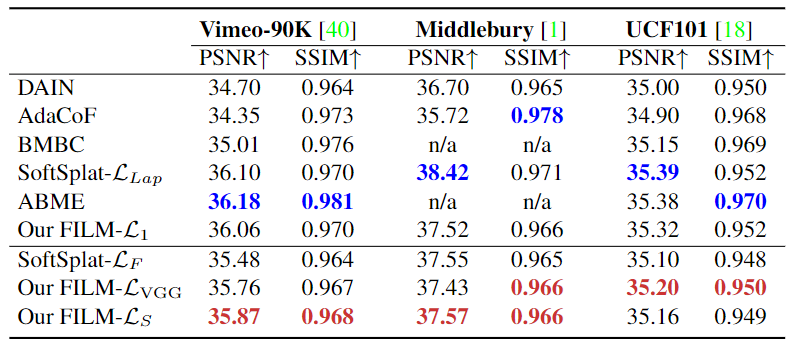
感知-失真權衡表明,僅靠最小化失真指標,如PSNR或SSIM,會對感知質量產生不利影響。幀插值研究的多重目標是實現低失真、高感知質量和時間上連貫的視頻。因此,研究人員使用文中提出的基于Gram矩陣損失LS來優化模型,對失真和感官質量都有好處。
當包括對感知敏感的損失時,FILM在Vimeo-90K上的表現優于最先進的SoftSplat。在Middlebury和UCF101上也取得了最高分。
在質量的對比上,首先從銳度(Sharpness)來看,為了評估基于Gram矩陣的損失函數在保持圖像清晰度方面的有效性,將FLIM生成的結果與用其他方法呈現的圖像進行了視覺比較。與其他方法相比,FLIM合成的結果非常好,面部圖像細節清晰,并保留了手指的關節。

在幀插值中,大部分的遮擋的像素應該在輸入幀中是可見的。一部分像素,取決于運動的復雜度,可能無法從輸入中獲得。因此,為了有效地掩蓋像素,模型必須學習適當的運動或生成出新的像素。結果可以看到,與其他方法相比,FILM 在保持清晰度的同時正確地繪制了像素。它還保留了物體的結構,例如紅色玩具車。而SoftSplat則變形了,ABME產生了模糊的畫中畫 。

大運動(large motion)是幀插值中最具難的部分之一。為了擴大運動搜索范圍,模型通常采用多尺度的方法或密集的特征圖來增加模型的神經能力。其他方法通過訓練大型運動數據集來實現。實驗結果可以看到,SoftSplat和ABME能夠捕捉到狗鼻子附近的運動,但是它們在地面上產生了很大的偽影。FILM的優勢在于能夠很好地捕捉到運動并保持背景細節。






















