













一張照片就能生成3D模型,GAN和自動編碼器碰撞出奇跡
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
2D圖片“腦補”3D模型,這次真的只用一張圖就行了——
只需要給AI隨便喂一張照片,它就能從不一樣的角度給你生成“新視圖”:

不僅能搞定360°的椅子和汽車,連人臉也玩出了新花樣,從“死亡自拍”角度到仰視圖都能生成:

更有意思的是,這只名叫Pix2NeRF的AI,連訓練用的數據集都有點“與眾不同”,可以在沒有3D數據、多視角或相機參數的情況下學會生成新視角。
可以說是又把NeRF系列的AI們卷上了一個新高度。
用GAN+自動編碼器學會“腦補”
在此之前,NeRF能通過多視圖訓練AI模型,來讓它學會生成新視角下的3D物體照片。
然而,這也導致一系列采用NeRF方法的模型,包括PixelNeRF和GRF,都需要利用多視圖數據集才能訓練出比較好的2D生成3D模型效果。
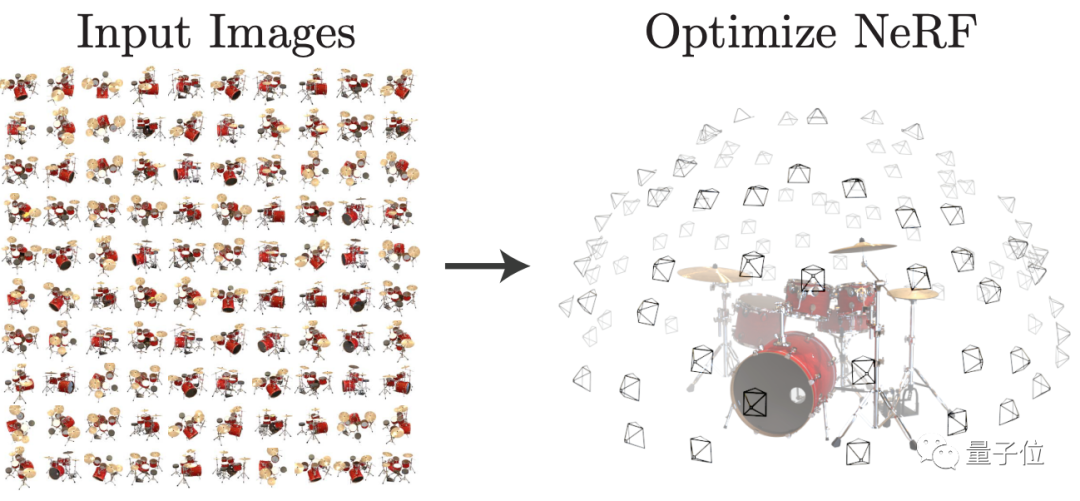
而多視圖數據集往往有限,訓練時間也比較長。
因此,作者們想出了一個新方法,也就是用自動編碼器來提取物體姿態和形狀特征,再用GAN直接生成全新的視角圖片。
Pix2NeRF包含三種類型的網絡架構,即生成網絡G,判別網絡D和編碼器E。
其中,生成網絡G和判別網絡D組成生成對抗網絡GAN,而編碼器E和生成網絡G用于構成自動編碼器:
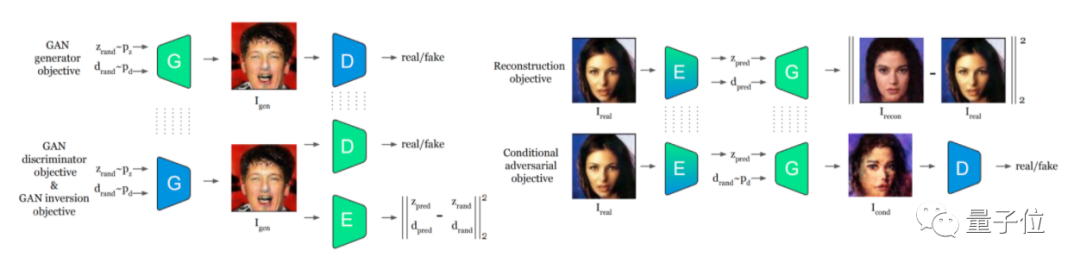
首先,自動編碼器可以通過無監督學習,來獲取輸入圖像的隱藏特征,包括物體姿態和物體形狀,并利用學習到的特征重建出原始的數據;
然后,再利用GAN來通過姿態和形狀數據,重構出與原來的物體形狀不同的新視圖。
這里研究人員采用了一種叫做π-GAN的結構,生成3D視角照片的效果相比其他類型的GAN更好(作者們還對比了采用HoloGAN的一篇論文):

那么,這樣“混搭”出來的AI模型,效果究竟如何?
用糊圖也能生成新視角
作者們先是進行了一系列的消融實驗,以驗證不同的訓練方法和模型架構,是否真能提升Pix2NeRF的效果。
例如,針對模型去掉GAN逆映射、自動編碼器,或不采用warmup針對學習率進行預熱等,再嘗試生成新視角的人臉:

其中,GAN逆映射(inversion)的目的是將給定的圖像反轉回預先訓練的GAN模型的潛在空間中,以便生成器從反轉代碼中重建圖像。
實驗顯示,除了完整模型(full model)以外,去掉各種方法的模型,生成人臉的效果都不夠好。
隨后,作者們又將生成照片的效果與其他生成新視圖的AI模型進行了對比。
結果表明,雖然Pix2NeRF在ShapeNet-SRN的生成效果上沒有PixelNeRF好,但效果也比較接近:
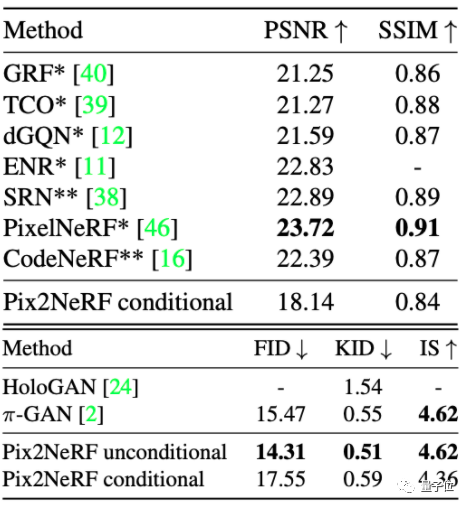
而在CelebA和CARLA數據集上,Pix2NeRF基本都取得了最好的效果。
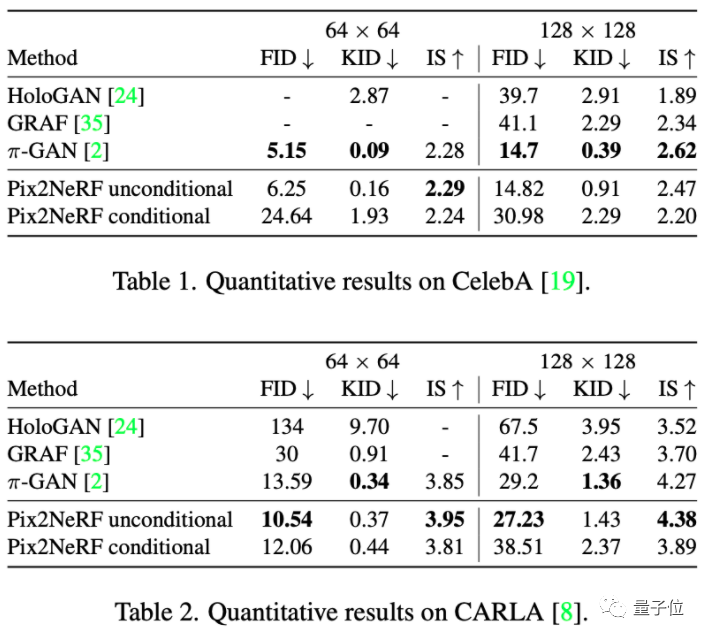
而且模型還自帶一些“美顏”功能,即使是糊圖送進去,也能給GAN出更絲滑的輪廓:

整體而言,除了人臉能生成不同角度的新視圖以外,物體還能腦補出360°下不同姿態的效果:

看來,AI也和人類一樣,學會“腦補”沒見過的物體形狀了。
作者介紹
這次論文的作者均來自蘇黎世聯邦理工學院(ETH)。
論文一作Shengqu Cai,ETH碩士研究生,本科畢業于倫敦國王學院,研究方向是神經渲染、生成模型和無監督學習等,高中畢業于遼寧省實驗中學。
Anton Obukhov,ETH博士生,此前曾在英偉達等公司工作,研究方向是計算機視覺和機器學習。
Dengxin Dai,馬普所高級研究員和ETH(外部)講師,研究方向是自動駕駛、傳感器融合和有限監督下的目標檢測。
Luc Van Gool,ETH計算機視覺教授,谷歌學術上的引用量達到15w+,研究方向主要是2D和3D物體識別、機器人視覺和光流等。
目前這項研究的代碼還在準備中。

感興趣的小伙伴可以蹲一波了~
論文地址:
https://arxiv.org/abs/2202.13162
項目地址:
https://github.com/sxyu/pixel-nerf
























