自動化測試:Python常見的幾種編程模式

本章節給大家更新一下“Python語法規范與數據類型”相關內容,主要是為了讓大家了解Python有什么類型的編程模式,掌握Python的基本語法,清楚怎么輸出及命令行參數的基本應用,對Python的數據類型了解后,以便做更多的相關操作。
常見的編程模式
①Python交互式命令編程。
②Python腳本編程。
③中文編碼處理。
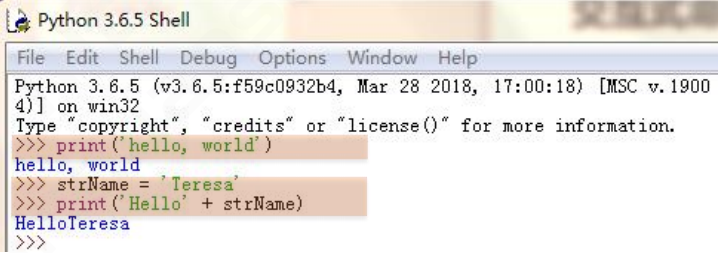
1、交互式命令編程模式
交互式命令編程模式就是一種典型逐行讀取執行模式。
當程序只有一行或較少的時候,這種編程模式是比較典型的應用方式。
下圖使用PythonIDLE編輯器進行編程,而該編輯器的編程模式就是典型的交互式命令編符號。
>>>就是輸入交互命令的提示符,每次輸入完畢后回車,該命令就被Python解析器執行。
2、腳本編程模式
當我們需要編寫較為復雜或大段的代碼的時候,命令式編程就顯得不夠方便。
因此,Python提供了腳本編程模式。可以創建一個后綴名為*.py的腳本文件,將大量的代碼編寫到該文件中,這樣便于代碼的維護和更新,之后再使用交互命令執行或IDE 工具運行即可。
3、字符編程
字符串是一種數據類型。但是,字符串還有一個比較特殊的編碼問題。
因為計算機只能處理數字,如果要處理文本,就必須先把文本轉換為數字才能處理。
補充:字符編碼發展史
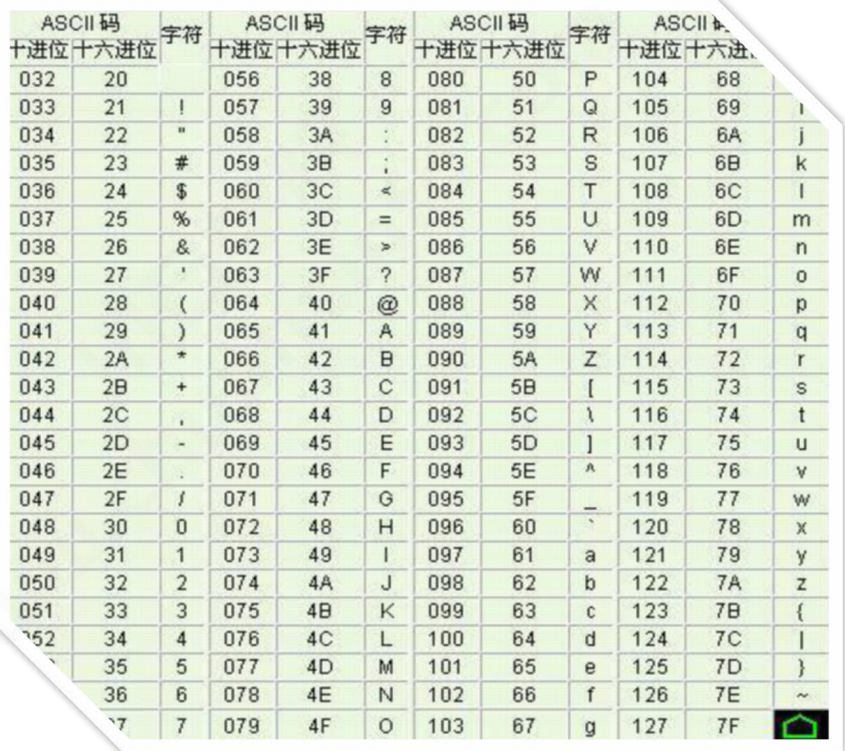
最早的計算機在設計時采用8個比特(bit)作為一個字節(byte),所以,一個字節能表示的最大的整數就是255(二進制11111111=十進制255),如果要表示更大的整數,就必須用更多的字節。比如兩個字節可以表示的最大整數是65535,4 個字節可以表示的最大整數是4294967295。
由于計算機是美國人發明的,因此,最早只有127個字符被編碼到計算機里,也就是大小寫英文字母、數字和一些符號,這個編碼表被稱為ASCII編碼,比如大寫字母A的編碼是65,小寫字母z的編碼是122。
擴展:unicode字符集
Python3之所以能夠很好地解決中文亂碼問題,在于其將所有的字符串都是用unicode進行字符編碼。
● Unicode把所有的語言統一到一套編碼里,這樣就不會有亂碼了。
● Unicode也在不斷的發展,但最常用的是用兩個字節表示一個字符(如果遇到非常生僻的字符,就需要4字節)。現在我們見到的大多數操作系統和大多數編程語言都支持unicode。
ASCII編碼是1個字節,而Unicode編碼通常是2個字節。
擴展:UTF-8字符集
新的問題又出現了:如果統一成Unicode編碼,亂碼問題從此消失了。但是,如果你寫的文本基本上全部是英文的話,用Unicode編碼比ASCII編碼需要多一倍的存儲空間,在存儲和傳輸上就十分不劃算。
解決辦法的誕生:又出現了把Unicode編碼轉化為“可變長編碼”的UTF-8編碼。
● UTF-8編碼把一個Unicode字符根據不同的數字大小編碼成1-6個字節,常用的英文字母被編碼成1個字節,漢字通常是3個字節,只有很生僻的字符才會被編碼成4-6個字節。
● 如果你要傳輸的文本包含大量英文字符,用UTF-8編碼就能節省空間。
● UTF-8編碼有一個額外的好處,就是ASCII編碼實際上可以被看成是UTF-8編碼的一部分,所以,大量只支持ASCII編碼的歷史遺留軟件可以在UTF-8編碼下繼續工作。
特別注意:計算機內存中,統一使用Unicode編碼。
python3字符編碼
在Python3版本中,字符串都是以Unicode編碼的,也就是說,Python字符串支持多語言。
單個字符的編碼,Python提供了ord()函數獲取單個字符的十進制整數表示,chr()函數把編碼轉換成對應的字符。
示例:
>>> ord(‘A’)
65
>>> ord(‘中’)
20013
>>> chr(66)
‘B’
>>> chr(25991)
‘文’
Python源代碼也是一個文本文件 ,所以,當你的源代碼中包含中文的時候,在保存源代碼時,就需要務必指定保存為UTF-8編碼。當Python解釋器讀取源代碼時,為了讓它按UTF-8編碼讀取,我們通常在文件開頭寫上這行。
#-*- coding:utf-8 *-
注釋是為了告訴Python解釋器,按照UTF-8編碼讀取源代碼,否則,你在源代碼中寫的中文輸出可能會有亂碼。