Adobe把GAN搞成了縫合怪,憑空P出1024分辨率全身人像
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
換臉見多了,換身材的見過嗎?
給定一張臉,就能自動換一個下半身,服飾、身材、膚色都毫無PS痕跡:

核心技術(shù)當然還是我們熟悉的GAN,但不同的是,現(xiàn)在身體的每個部分都能被PS了。
從臉,膚色、服飾、頭發(fā)等身體各個部位,甚至到肢體動作,都能被隨意設(shè)計和組合,最終“縫”成一張1024 × 1024分辨率的全身照片:

而且這張“縫合怪”還完全沒有拼接行為帶來的陰影和邊界:

△上方的面部由新方法生成,陰影邊界很少
怎么做到的?把用于生成人體不同部位的GAN“拼”起來。

這就是Adobe團隊最新提出的一種結(jié)合多個預(yù)訓(xùn)練的GAN進行圖像生成的新方法,論文目前已被CVPR 2022接收:

接下來就一起來看看他們到底是如何實現(xiàn)的。
用PS的方式GAN出個人體
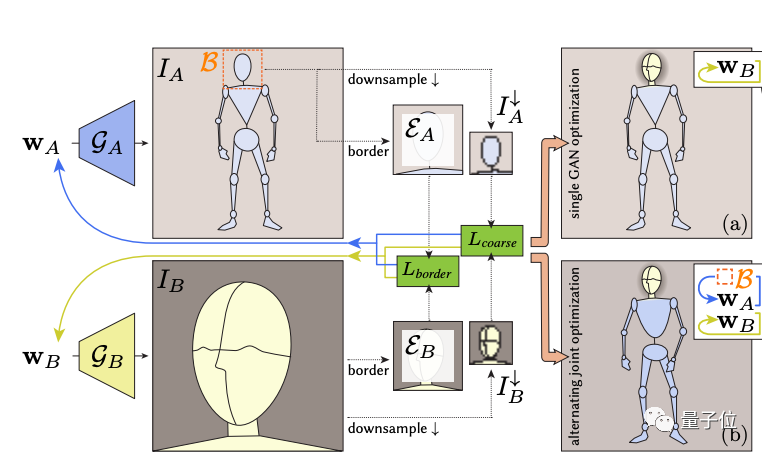
如我們開頭所說,這是一種將多個GAN拼接起來使用的方法,研究團隊將其稱之為InsetGAN。
共分為兩類GAN:
- 全身GAN (Full-Body GAN),基于中等質(zhì)量的數(shù)據(jù)進行訓(xùn)練并生成一個人體。
- 部分GAN,其中包含了多個針對臉部、手、腳等特定部位進行訓(xùn)練的GAN。
這兩類GAN的合作方式類似于PS:全身GAN是一張已經(jīng)有打底線稿的畫布,而部分GAN則是一張一張疊在上面的圖層。
但不同邊界的“圖層”在疊到畫布上時,一定會有出現(xiàn)對齊問題。
比如,將一張臉添加到身體上時,在膚色的一致性、衣服邊界和頭發(fā)披散的自然性上可能出現(xiàn)細節(jié)的扭曲和丟失,或出現(xiàn)偽影(Artifacts):

如何才能更好地協(xié)調(diào)多個GAN,讓它們產(chǎn)生一致的像素呢?
研究團隊設(shè)計了這樣一種架構(gòu):
他們首先引入了一個邊界框檢測器,檢測部分GAN生成的特定區(qū)域在底層畫布,也就是全身GAN生成的區(qū)域中的位置,經(jīng)過裁剪后再將特定區(qū)域嵌入。
這一過程相當于找到了兩個區(qū)域之間的一種隨機潛碼 (latent code),使得所選區(qū)域的邊界能夠和嵌入?yún)^(qū)域相匹配,以實現(xiàn)無縫合成。
同時,他們還會對這兩個區(qū)域進行下采樣(Downsample),再次增加圖像像素內(nèi)容的一致性。
基于這種方法,InsetGAN可以在訓(xùn)練后生成多張完整人像,同時膚色、頭發(fā)和相關(guān)姿勢都能作出相應(yīng)調(diào)整:

研究團隊也與之前的生成全身人像的方法CoModGAN做了比較,都是基于左側(cè)的人體進行面部的替換,顯然,InsetGAN生成的面部更加自然:

△上為InsetGAN,下為CoModGAN
作者介紹
論文共有6位作者,5位來自Adobe研究院,還有1位來自阿卜杜拉國王科技大學(xué)(KAUST)。
其中有Adobe的首席科學(xué)家Jingwan Lu,是PS 2020中智能肖像、皮膚平滑、著色和神經(jīng)風(fēng)格化等過濾器的主要算法貢獻者,也是RealBrush筆刷合成器的開發(fā)者。
她目前領(lǐng)導(dǎo)的團隊主要致力于利用大數(shù)據(jù)和生成性AI(比如GAN)來進行視覺內(nèi)容的創(chuàng)造。

所以,準備好足不出戶換身材了嗎?(手動狗頭)
論文地址:
??https://arxiv.org/abs/2203.07293