













清華大學、DeepMind等指出現有小樣本學習方法并不穩定有效,提出評價框架
評價準則的差異極大阻礙了已有小樣本學習方法基于統一的標準公平比較,也無法客觀評價該領域的真實進展。近期,來自清華大學、DeepMind 等團隊研究者在論文《FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding》中指出:現有小樣本學習方法并不穩定有效,且目前已有工作不存在單一的小樣本學習方法能夠在大多數 NLU 任務上取得優勢性能。小樣本自然語言理解領域發展依然面臨著嚴峻的挑戰!該工作被 ACL2022 主會接收。

- 論文地址:https://arxiv.org/abs/2109.12742
- 項目地址:https://github.com/THUDM/FewNLU
- Leaderboard 地址:https://fewnlu.github.io/
本文貢獻如下:
(1) 該研究提出了一個新的小樣本自然語言理解評價框架 FewNLU,并且從三個關鍵方面(即測試集小樣本學習性能、測試集和驗證集相關性、以及穩定性) 量化評估該評價準則的優勢。 (2) 研究者對該領域相關工作進行重新評估,結果表明:已有工作未準確估計現有小樣本學習方法的絕對性能和相對差距;目前尚不存在單一在大多數 NLU 任務取得優勢性能的方法;不同方法的增益是優勢互補的,最佳組合模型的性能接近于全監督 NLU 系統等關鍵結論。(3) 此外本文提出 FewNLU,并構建了 Leaderboard,希望幫助促進小樣本自然語言理解領域未來研究工作的發展。
小樣本自然語言理解評價框架
模型選擇對小樣本學習是必要的嗎?
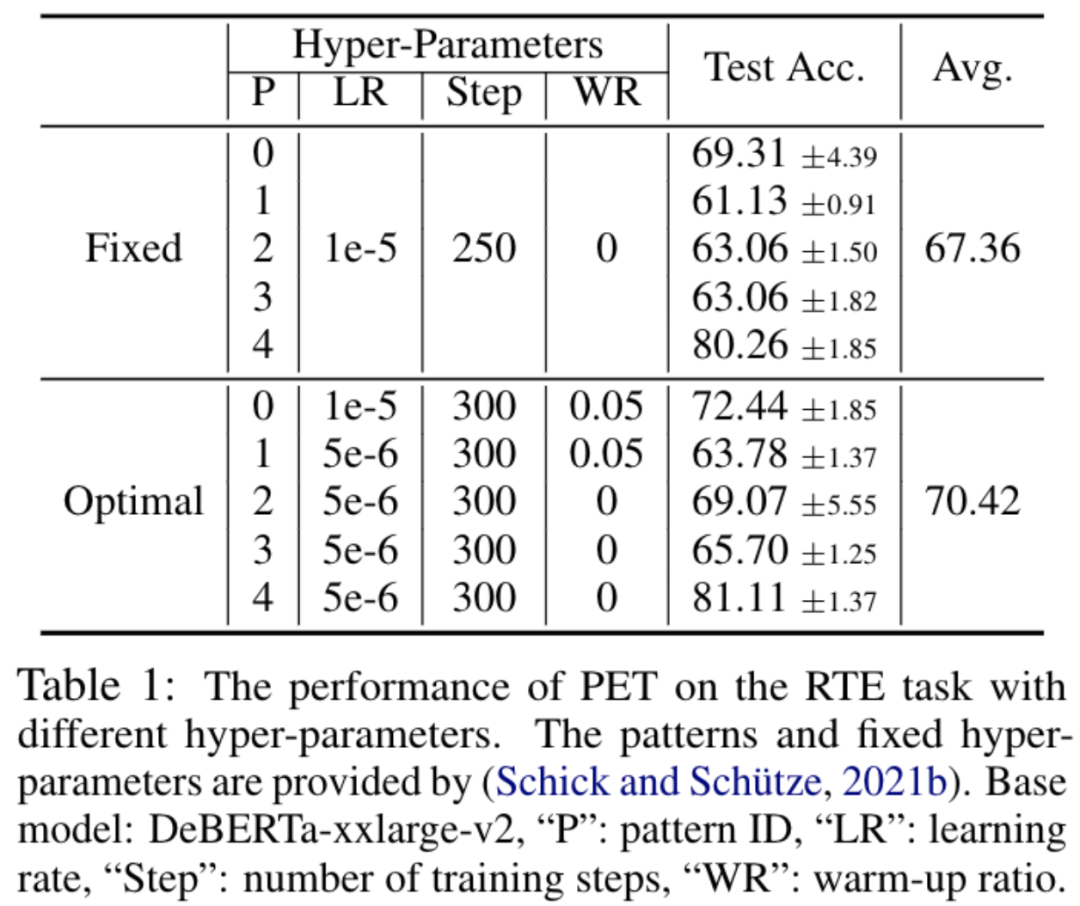
初步實驗結果表明 (如表格 1 所示),就如已有大多數工作那樣基于一組(根據既往實驗經驗) 預先固定的超參數的實驗設置,并不是最佳選擇。實驗條件的細微變化或者擾動都會帶來性能的急劇波動。基于小的驗證集在不同實驗中分別進行模型選擇是不可或缺的。
小樣本自然語言理解評價框架
基于上述結論,本文為小樣本自然語言理解提出一種更穩健且有效的評價框架,如算法 1 所示。

該評價框架中有兩個關鍵設計選擇,分別是如何構建數據拆分以及確定關鍵搜索超參數。
如何構建數據拆分?
本文首先提出數據拆分構建的三個關鍵指標: (1) 最終測試集小樣本學習性能、 (2) 測試集和驗證集關于一個超參數空間分布的相關性、以及 (3) 關于實驗執行次數的穩定性。
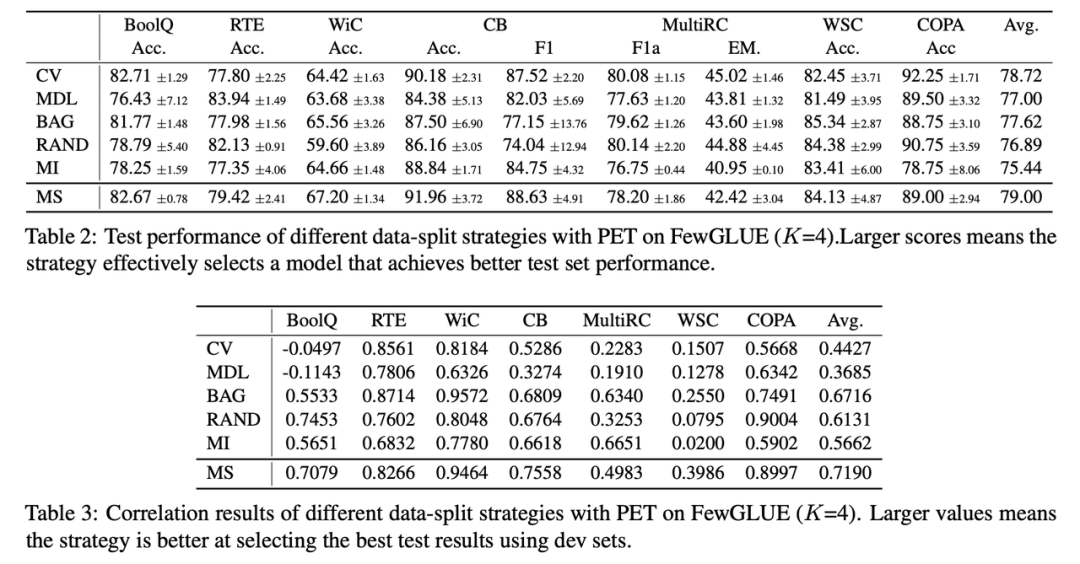
基于此,本文對多種不同的數據拆分策略進行了量化實驗和討論,包括 (1) K 折交叉驗證 (K-Fold CV)[2], (2) 最短描述距離(MDL)[2],(3) Bagging [9], (4) 隨機采樣策略 (5) 模型指導的拆分策略 (6) 以及本文提出的多次數據劃分(Multi-Splits)。
實驗結果如表格 2、3 和圖 1 所示。表格 2、3 的實驗結果表明:從小樣本性能和相關性看,多次數據劃分 (Multi-Splits) 是比其他幾個基準方案更好的數據拆分策略。
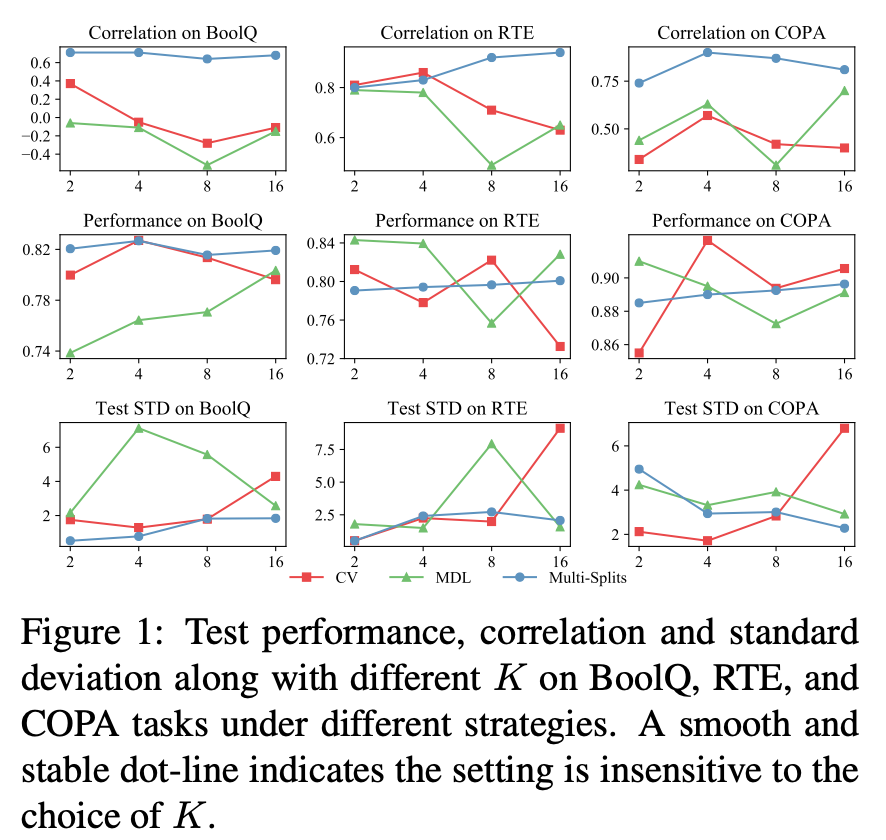
此外,由圖 1 可知,Multi-Splits 的優勢還源于增大執行次數 K 的取值并不會對訓練集和驗證集的數據量產生影響,相反會進一步增加該結果的置信度,故實驗過程中總可以選擇盡可能增大 K 的取值。然而對于 CV 和 MDL,較大的 K 值會導致失敗(Failure Mode),較小的 K 值導致高隨機性不穩定的結果;同時在實踐中很難先驗地知道應該如何取值。故 Multi-Splits 是更具實際使用意義的數據拆分策略。
小樣本學習方法重新評價
基于統一的評價框架下,本文對目前已有最先進的小樣本學習方法進行重新評價。本文還嘗試探索了多種不同小樣本學習方法和技術組合可以實現的最佳性能(如表格 5 中的 "Our Best" 所示)。重新評價實驗結果如表格所示。
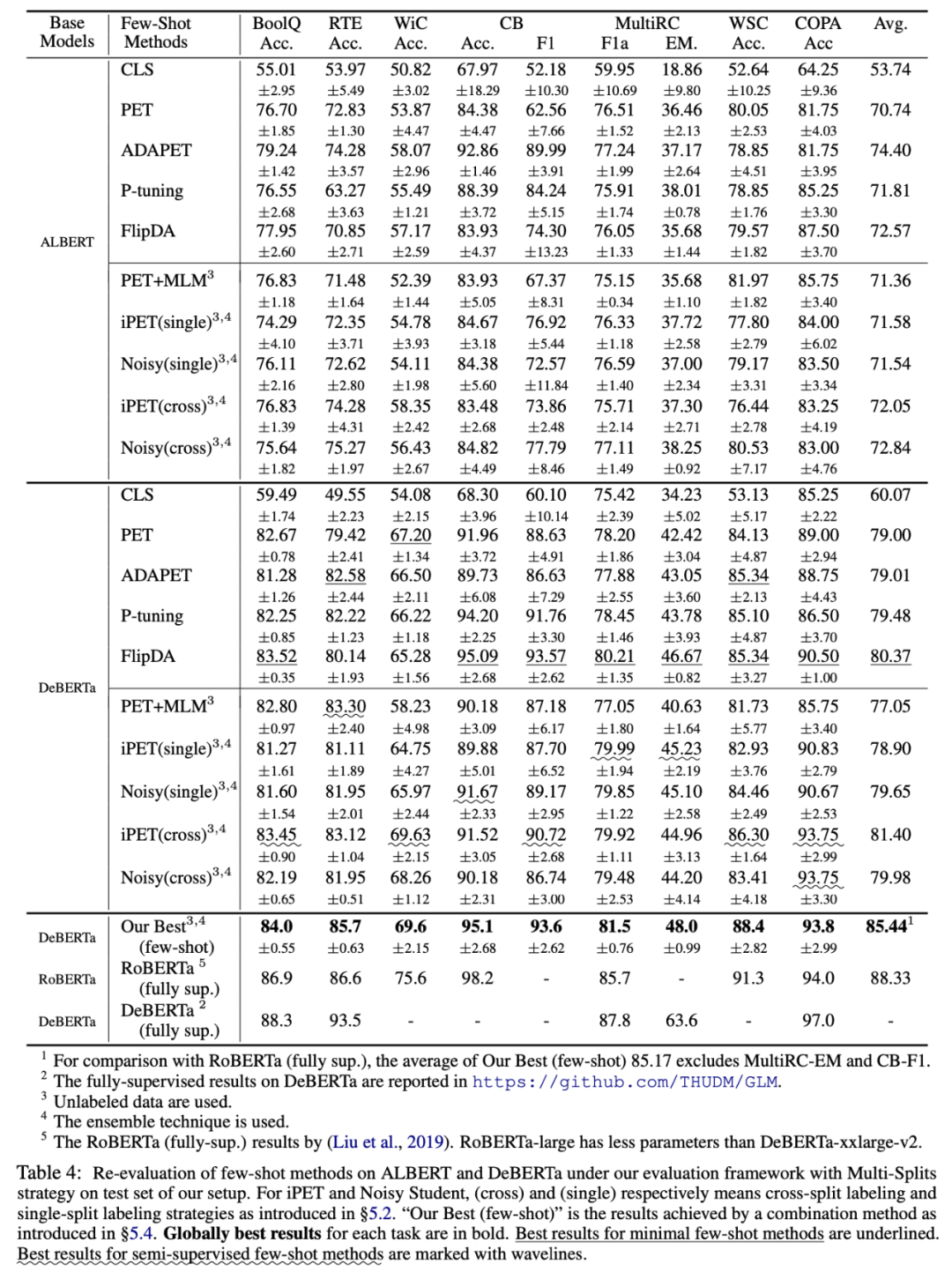
重新評估結果可揭示如下關鍵結論:
- 結論 1: 小樣本學習方法的絕對性能和相對性能差異,在先前文獻中未被準確估計。此外小樣本方法(例如 ADAPET)在像 DeBERTa 這樣的大型模型上的優勢會顯著降低。半監督小樣本方法(例如 iPET 和 Noisy Student)增益在較大的模型也可以保持一致性。
- 結論 2: 不同小樣本學習方法的增益在很大程度上是互補的。通過將目前各種先進方法加以組合,它們可以在很大程度上實現優于任意單一方法的小樣本學習性能。目前最佳組合方法的小樣本學習性能,接近 RoBERTa 上實現的全監督性能;然而和目前 DeBERTa 上實現的最優全監督性能相比,它仍然存在較大的差異性。
- 結論 3: 目前已有相關工作中不存在單一的小樣本學習方法能夠在大多數 NLU 任務上取得主導性優勢性能。這為未來進一步開發出具有跨任務一致性和魯棒性的小樣本學習方法提出新的挑戰。















