手把手教你用Pandas讀取所有主流數據存儲
Pandas提供了一組頂層的I/O API,如pandas.read_csv()等方法,這些方法可以將眾多格式的數據讀取到DataFrame數據結構中,經過分析處理后,再通過類似DataFrame.to_csv()的方法導出數據。
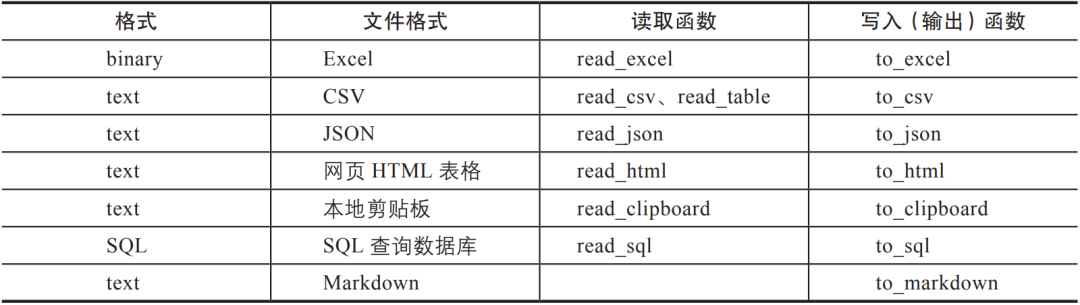
表3-1列出了一些常見的數據格式讀取和輸出方法。
▼表3-1 Pandas中常見數據的讀取和輸出函數
輸入和輸出的方法如下:
- 讀取函數一般會賦值給一個變量df,df = pd.read_();
- 輸出函數是將變量自身進行操作并輸出df.to_()。
一、CSV文件
CSV(Comma-Separated Values)是用逗號分隔值的數據形式,有時也稱為字符分隔值,因為分隔字符也可以不是逗號。CSV文件的一般文件擴展名為.csv,用制表符號分隔也常用.tsv作為擴展名。CSV不僅可以是一個實體文件,還可以是字符形式,以便于在網絡上傳輸。
CSV文件的讀取方法如下(以下代碼省略了賦值操作):
# 文件目錄
pd.read_csv('data.csv') # 如果文件與代碼文件在同一目錄下
pd.read_csv('data/my/data.csv') # 指定目錄
pd.read_csv('data/my/my.data') # CSV文件的擴展名不一定是.csv
CSV文件可以存儲在網絡上,通過URL來訪問和讀取:
# 使用URL
pd.read_csv('https://www.gairuo.com/file/data/dataset/GDP-China.csv')
CSV不帶數據樣式,標準化較強,是最為常見的數據格式。
二、Excel
Excel電子表格是微軟公司開發的被廣泛使用的電子數據表格軟件,一般可以將它的使用分為兩類。一類是文字或者信息的結構化,像排班表、工作日報、客戶名單之類,以文字為主;另一類為統計報表,如學生成績表、銷售表等,以數字為核心。
Pandas主要處理統計報表,當然也可以對文字信息類表格做整理,在新版本的Pandas中加入了非常強大的文本處理功能。
Excel雖然易于上手,功能也很強大,但在數據分析中缺點也很明顯。
- 無法進行復雜的處理:有時Excel提供的函數和處理方法無法滿足復雜邏輯。
- 無法支持更大的數據量:目前Excel支持的行數上限為1 048 576(2的20次方),列數上限為16 384(2的14次方,列標簽為XFD),在數據分析、機器學習操作中往往會超過這個體量。
- 處理方法無法復用:Excel一般采用設定格式的公式,然后將數據再復制,但這樣仍然無法對數據的處理過程進行靈活復用。
- 無法自動化:數據分析要經過一個數據輸入、處理、分析和輸出的過程,這些都是由人工來進行操作,無法實現自動化。
Pandas可以讀取、處理大體量的數據,通過技術手段,理論上Pandas可以處理的數據體量無限大。編程可以更加自由地實現復雜的邏輯,邏輯代碼可以進行封裝、重復使用并可實現自動化。
Pandas也提供了非常豐富的讀取操作,這些在《手把手教你用Python讀取Excel》有詳細介紹。最基礎的讀取方法如下:
# 返回DataFrame
pd.read_excel('team.xlsx') # 默認讀取第一個標簽頁Sheet
pd.read_excel('path_to_file.xlsx', sheet_name='Sheet1') # 指定Sheet
# 從URL讀取
pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
三、JSON
JSON是互聯網上非常通用的輕量級數據交換格式,是HTTP請求中數據的標準格式之一。Pandas提供的JSON讀取方法在解析網絡爬蟲數據時,可以極大地提高效率。可如下讀取JSON文件:
# data.json為同目錄下的一個文件
pd.read_json('data.json')
可以解析一個JSON字符串,以下是從HTTP服務檢測到的設備信息:
jdata='{"res":{"model":"iPhone","browser":"Safari","version":"604.1"},"status":200}'
pd.read_json(jdata)
'''
res status
browser Safari 200
model iPhone 200
version 604.1 200
'''
Pandas還提供了pd.json_normalize(data)方法來讀取半結構化的JSON數據。
四、HTML
pd.read_html()函數可以接受HTML字符串、HTML文件、URL,并將HTML中的標簽表格數據解析為DataFrame。如返回有多個df的列表,則可以通過索引取第幾個。如果頁面里只有一個表格,那么這個列表就只有一個DataFrame。此方法是Pandas提供的一個簡單實用的實現爬蟲功能的方法。
dfs = pd.read_html('https://www.gairuo.com/p/pandas-io')
dfs[0] # 查看第一個df
# 讀取網頁文件,第一行為表頭
dfs = pd.read_html('data.html', header=0)
# 第一列為索引
dfs = pd.read_html(url, index_col=0)如果一個網頁表格很多,可以指定元素來獲取:
# id='table'的表格,注意這里仍然可能返回多個
dfs1 = pd.read_html(url, attrs={'id': 'table'})
# dfs1[0]
# class='sortable'
dfs2 = pd.read_html(url, attrs={'class': 'sortable'})
常用的參數與read_csv的基本相同。
五、剪貼板
剪貼板(Clipboard)是操作系統級的一個暫存數據的地方,它保存在內存中,可以在不同軟件之間傳遞,非常方便。Pandas支持讀取剪貼板中的結構化數據,這就意味著我們不用將數據保存成文件,而可以直接從網頁、Excel等文件中復制,然后從操作系統的剪貼板中讀取,非常方便。
'''
x y z
a 1 2 3
b 4 5 6
c 7 8 9
'''
# 復制上邊的數據,然后直接賦值
cdf = pd.read_clipboard()
變量cdf就是上述文本的DataFrame結構數據。read_clipboard的參數使用與read_csv完全一樣。
六、SQL
Pandas需要引入SQLAlchemy庫來支持SQL,在SQLAlchemy的支持下,它可以實現所有常見數據庫類型的查詢、更新等操作。Pandas連接數據庫進行查詢和更新的方法如下。
- read_sql_table(table_name, con[, schema, …]):把數據表里的數據轉換成DataFrame。
- read_sql_query(sql, con[, index_col, …]):用sql查詢數據到DataFrame中。
- read_sql(sql, con[, index_col, …]):同時支持上面兩個功能。
- DataFrame.to_sql(self, name, con[, schema, …]):把記錄數據寫到數據庫里。
以下是一些代碼示例:
# 需要安裝SQLAlchemy庫
from sqlalchemy import create_engine
# 創建數據庫對象,SQLite內存模式
engine = create_engine('sqlite:///:memory:')
# 取出表名為data的表數據
with engine.connect() as conn, conn.begin():
data = pd.read_sql_table('data', conn)
# data
# 將數據寫入
data.to_sql('data', engine)
# 大量寫入
data.to_sql('data_chunked', engine, chunksize=1000)
# 使用SQL查詢
pd.read_sql_query('SELECT * FROM data', engine)
七、小結
Pandas支持讀取非常多的數據格式,本文僅介紹了幾種常見的數據文件格式,更多格式可以在其官網查詢。
https://pandas.pydata.org/docs/user_guide/io.html
關于作者:李慶輝,數據產品專家,某電商公司數據產品團隊負責人,擅長通過數據治理、數據分析、數據化運營提升公司的數據應用水平。精通Python數據科學及Python Web開發,曾獨立開發公司的自動化數據分析平臺,參與教育部“1+X”數據分析(Python)職業技能等級標準評審。中國人工智能學會會員,企業數字化、數據產品和數據分析講師,在個人網站“蓋若”上編寫的技術和產品教程廣受歡迎。
本書摘編自《深入淺出Pandas:利用Python進行數據處理與分析》,機械工業出版社華章公司2021年出版。轉載請與我們取得授權。