歸一化提高預訓練、緩解梯度不匹配,Facebook的模型超越GPT-3
在原始的 Transformer 架構中,LayerNorm 通常在 Residual 之后,稱之為 Post-LN(Post-Layer Normalization)Transformer,該模型已經在機器翻譯、文本分類等諸多自然語言的任務中表現突出。
最近的研究表明,在 Post-LN transformer 中,與較早層的網絡相比,在較后層的網絡中具有更大的梯度幅度。
實踐表明,Pre-LN Transformer 可以使用更大的學習率、極小的學習率進行預熱(即 warm-up),并且與 Post-LN Transformer 相比通常會產生更好的性能,所以最近大型預訓練語言模型傾向于使用 Pre-LN transformer。
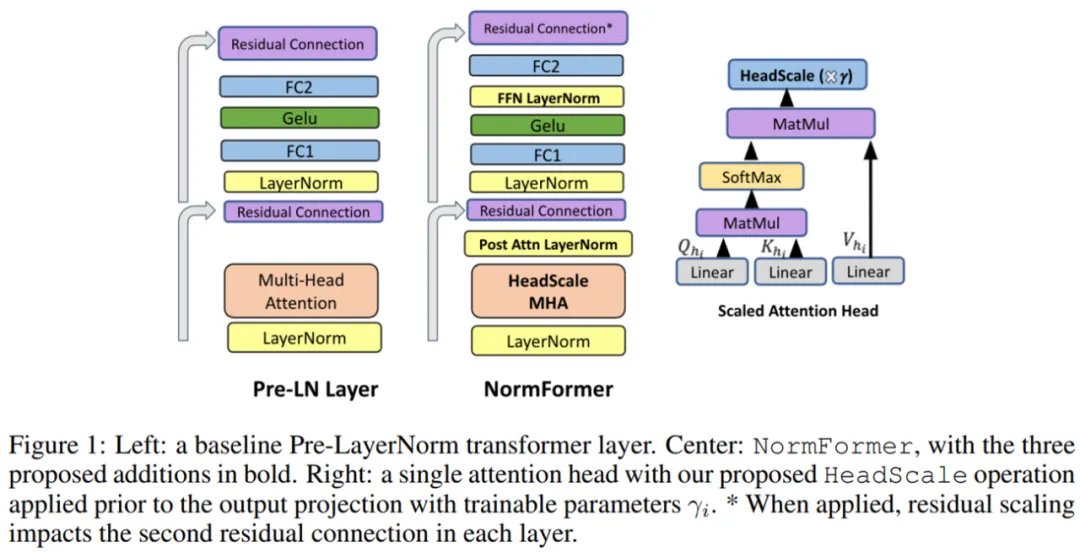
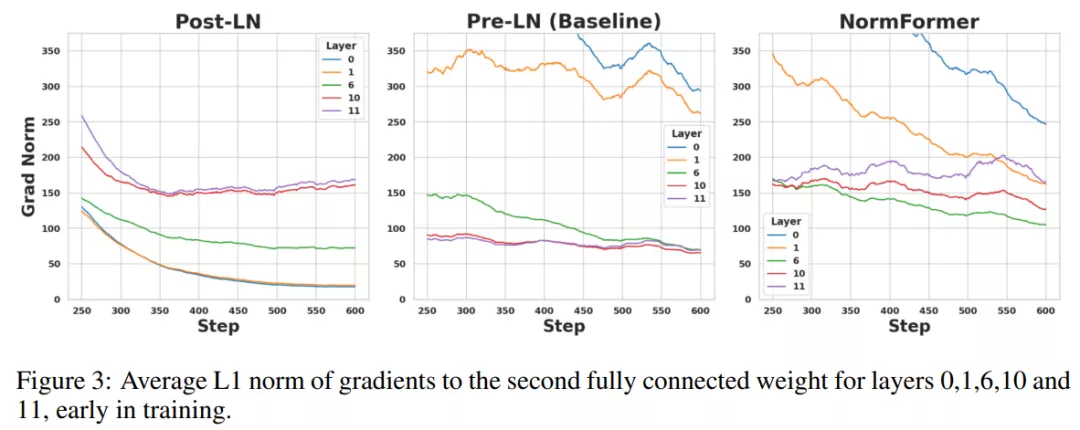
來自 Facebook AI 的研究者表明,雖然 Pre-LN 比 Post-LN 提高了穩定性,但也具有缺點:較早層的梯度往往大于較后層的梯度。這些問題可以通過該研究提出的 NormFormer 來緩解,它通過向每一層添加 3 個歸一化操作來緩解梯度幅度不匹配問題(見圖 1,中間):自注意力之后添加層歸一,自注意力輸出的 head-wise 擴展,在第一個全連接層之后添加層歸一。這些操作減少了早期層的梯度,增加了后期層的梯度,使不同層的梯度大小更接近。
此外,這些額外的操作產生的計算成本可以忽略不計(+0.4% 的參數增加),但這樣做可以提高模型預訓練困惑度和在下游任務的表現,包括在 1.25 億參數到 27 億參數的因果模型和掩碼語言模型的性能。例如,該研究在最強的 1.3B 參數基線之上添加 NormFormer 可以將同等困惑度提高 24%,或者在相同的計算預算下更好地收斂 0.27 倍困惑度。該模型以快 60% 的速度達到了與 GPT3-Large (1.3B)零樣本相同的性能。對于掩碼語言模型,NormFormer 提高了微調好的 GLUE 性能,平均提高了 1.9%。

論文地址:https://arxiv.org/pdf/2110.09456.pdf
與計算匹配、微調好的 Pre-LN 基線相比,NormFormer 模型能夠更快地達到目標預訓練的困惑度,更好地實現預訓練困惑度和下游任務性能。
論文一作 Sam Shleifer 在推特上表示:很高興發布 NormFormer,這是我們新的語言建模架構,在實驗過的每個擴展(高達 2.7B 參數)上都優于 GPT-3。
來自魁北克蒙特利爾學習算法研究所的機器學習研究者 Ethan Caballero 表示:「更多的歸一化 is All You Need,在 GPT-3 架構中使用 NormFormer 達到了 SOTA 性能, 速度提高了 22%,并在下游任務中獲得了更強的零樣本性能。」
方法架構
NormFormer 對 Pre-LN transformer 做了三處修改:在注意力模塊內部應用 head-wise 縮放,并添加兩個額外的 LayerNorm 操作(一個放在注意力模塊后面,另一個放在首個全連接層后面)。這些修改引入了少量額外的可學得參數,使得每個層都能以經濟高效的方式改變特征大小,進而改變后續組件的梯度大小。這些變化的細節如下圖 1 所示:
縮放注意力頭。標準多頭注意力操作定義如下:
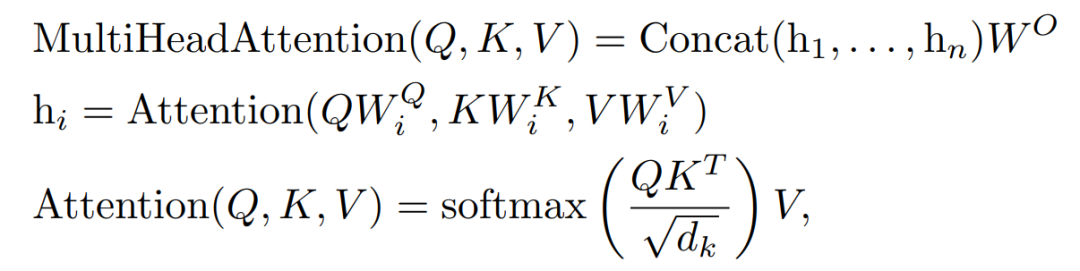
研究者提出通過學得的標量系數γ_i 縮放每個注意力頭的輸出:
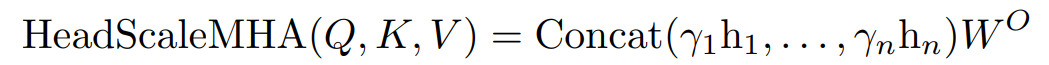
額外層歸一化以及將所有組件放在一起。在 Pre-LN transformer 中,每個層 l 將輸入 x_l 做出如下修改:

相反,NormFormer 將每個輸入 x_l 修改如下:
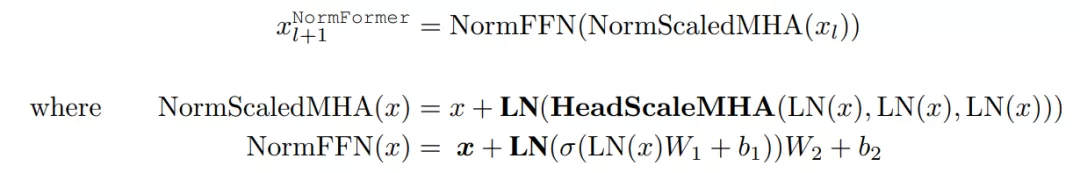
其中,新引入了 bolded operations。
實驗結果
對于因果語言模型(Casual Language Model),研究者預訓練的 CLM 模型分別為 Small(1.25 億參數)、Medium(3.55 億參數)、Large(13 億參數)和 XL(27 億參數)。
他們訓練了 3000 億個 token 的基線模型,并用等量的 GPU 小時數訓練 NormFormer 模型,由于歸一化操作的額外開銷,后者通常會減少 2%-6% 的 steps 和 tokens。
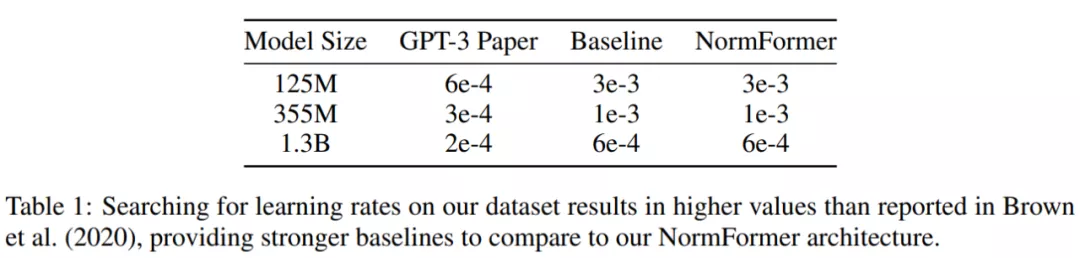
在使用的數據集上,研究者發現 GPT-3 中提出的學習率不是最理想的。因此,對于除了 27 億參數之外的每個大小的基線和 NormFormer 模型,他們通過訓練 5 萬 steps 的模型并從 {1e−4, 6e−4, 3e−4, 6e−4, 1e−3, 3e−3} 中選擇性能最佳的學習率來對學習率進行調整。這一過程中獲得的學習率如下表 1 所示,NormFormer 的學習率是 GPT-3 的 3-5 倍。
對于掩碼語言模型(Masked Language Model, MLM),研究者采用了 Liu et al. (2019)中使用的 RoBERTa-base、Pre-LN 架構和超參數。對于基線模型,他們對 100 萬個 token 預訓練了 200 萬個 batch,是原始 roberta-base 訓練預算的 1/4。相較之下,NormFormer 在相同時間內運行了 192 萬個 batch。
對于預訓練數據,研究者在包含 CC100 英語語料庫以及由 BookCorpus、英文維基百科和 Common Crawl 過濾子集組成的 Liu et al. (2019)的數據英語文本集合上對所有模型進行預訓練。
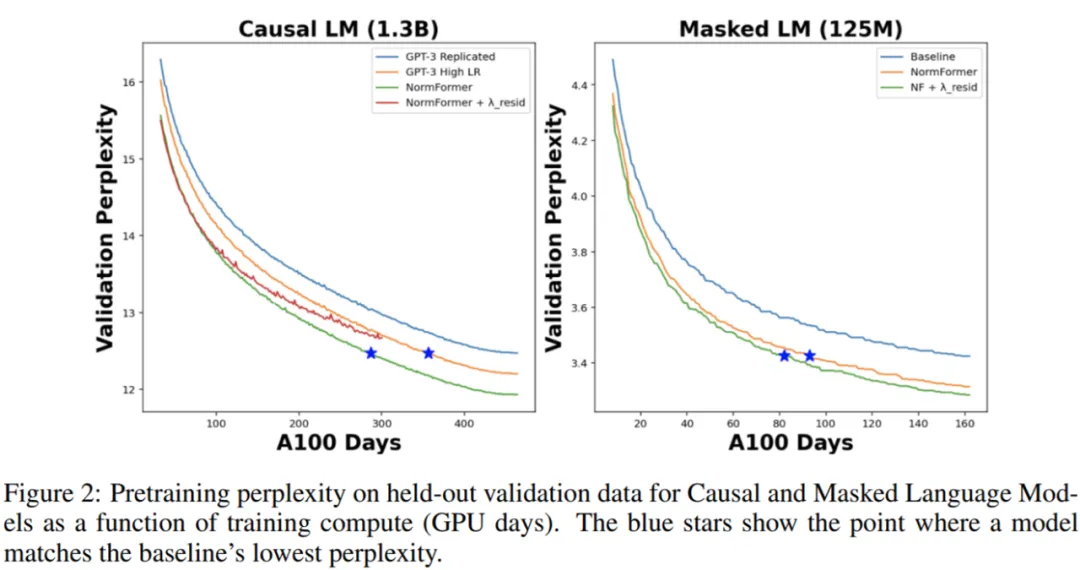
在下圖 2 中,研究者將 CLM 和 MLM 的預訓練困惑度表示訓練時間,即 GPU days。可以看到,NormFormer 的訓練速度明顯更快,并且在給定訓練計算預算下實現了更好的驗證困惑度。
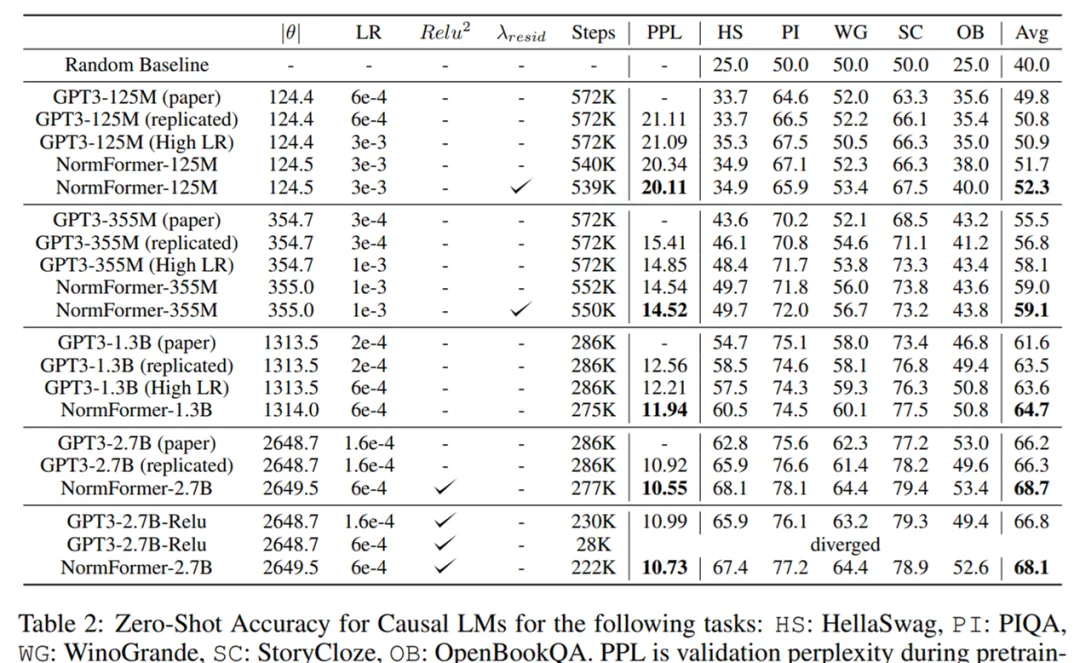
研究者在下游任務上也觀察到了類似的趨勢。如下表 2 所示,研究者使用 Brown et al. (2020)中的任務和 prompt 來觀察 CLM 模型的零樣本準確率。同樣地,NormFormer 在所有大小上均優于 GPT-3。
對于 MLM 模型,研究者在下表 3 中報告了在 GLUE 上的微調準確率。再次,NormFormer MLM 模型在每個任務上都優于它們的 Pre-LN 模型。
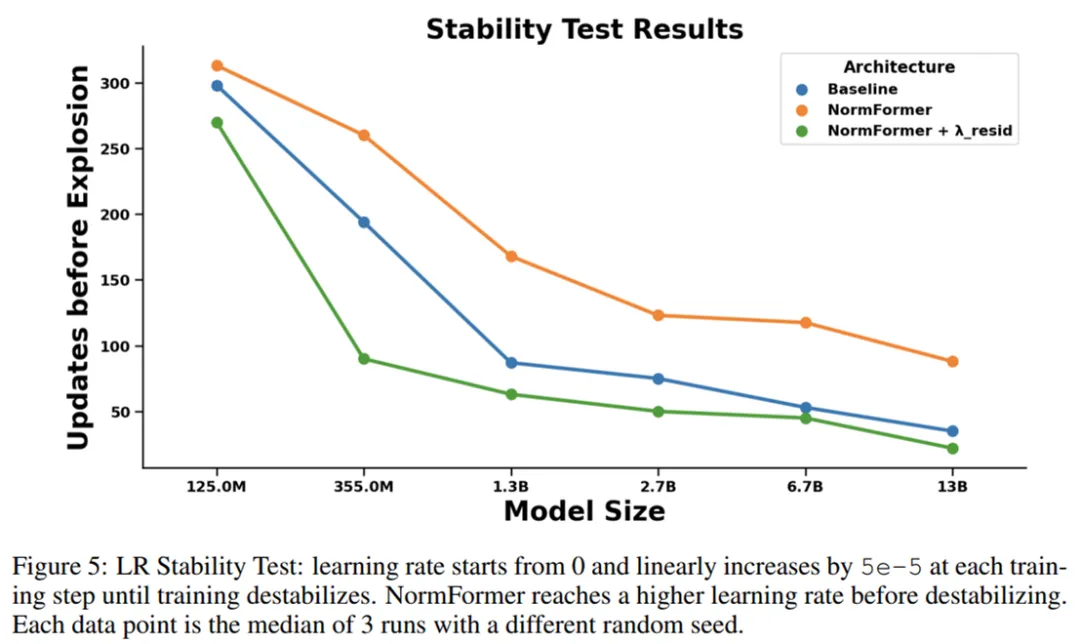
為了度量架構的穩定性,研究者使用具有極大峰值學習率的學習率計劃對其進行訓練,使得學習率每個 step 增加一點,直到損失爆炸。圖 5 顯示了與基線相比,NormFormer 模型在此環境中可以承受更多的更新。