突破百萬(wàn)億參數(shù)規(guī)模,追求極致的效率和性?xún)r(jià)比:華人團(tuán)隊(duì)開(kāi)源首個(gè)異構(gòu)并行推薦系統(tǒng)訓(xùn)練框架Persia
?個(gè)性化推薦是互聯(lián)網(wǎng)行業(yè)提升 DAU (Daily Active Users)和收入的核心技術(shù)手段。隨著深度學(xué)習(xí)的廣泛應(yīng)用,現(xiàn)代的推薦系統(tǒng)通過(guò)神經(jīng)網(wǎng)絡(luò)變相地「記住」用戶(hù)的行為習(xí)慣,從而精準(zhǔn)預(yù)測(cè)出用戶(hù)的喜好。在移動(dòng)互聯(lián)網(wǎng)普及之后,用戶(hù)的行為數(shù)據(jù)呈現(xiàn)幾何級(jí)數(shù)增加,單位時(shí)間內(nèi)產(chǎn)生和收集的用戶(hù)行為數(shù)據(jù)更是極其龐大,因此需要更大的模型來(lái)對(duì)用戶(hù)的興趣編碼。
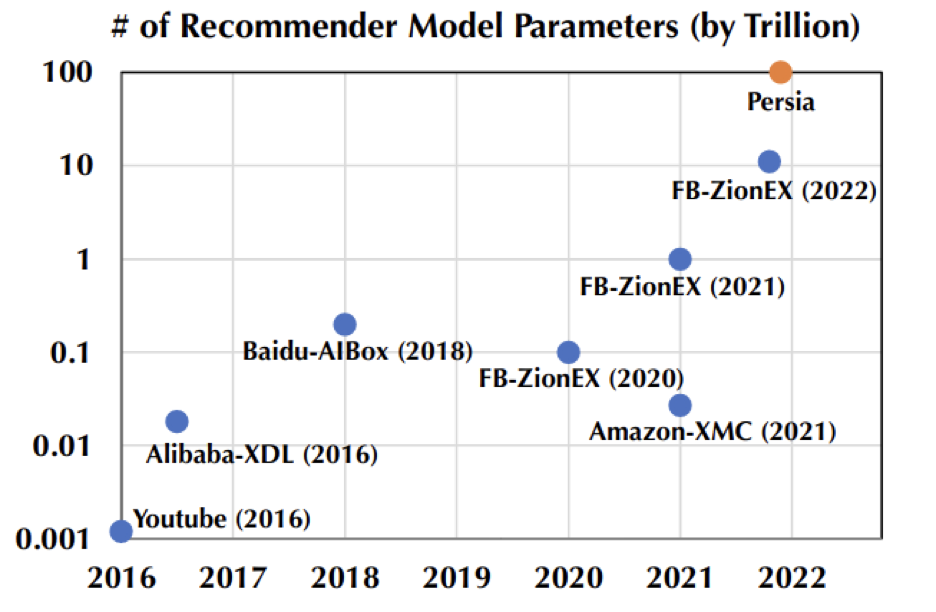
更大的數(shù)據(jù)規(guī)模意味著需要更大的模型容量,模型參數(shù)量從 5 年前的十億已經(jīng)迅速增長(zhǎng)達(dá)到前段時(shí)間 Facebook 公開(kāi)的十萬(wàn)億參數(shù)規(guī)模。在這樣的趨勢(shì)下,更大規(guī)模的訓(xùn)練需求無(wú)疑將會(huì)成為下一個(gè)需要攻克的里程碑。
最近,由兩個(gè)華人團(tuán)隊(duì)聯(lián)合開(kāi)源的訓(xùn)練框架 Persia 通過(guò)設(shè)計(jì)混合架構(gòu)并在 Google cloud 上成功地把模型規(guī)模又推向了一個(gè)新的量級(jí) -- 百萬(wàn)億參數(shù)量(需占用數(shù)百 T 的存儲(chǔ)),并能同時(shí)兼顧效率和精度。目前該框架已經(jīng)受邀集成進(jìn) Pytorch 生態(tài)圈 Pytorch Lightning。
- GitHub: https://github.com/PersiaML/PERSIA
- 論文: https://arxiv.org/abs/2111.05897
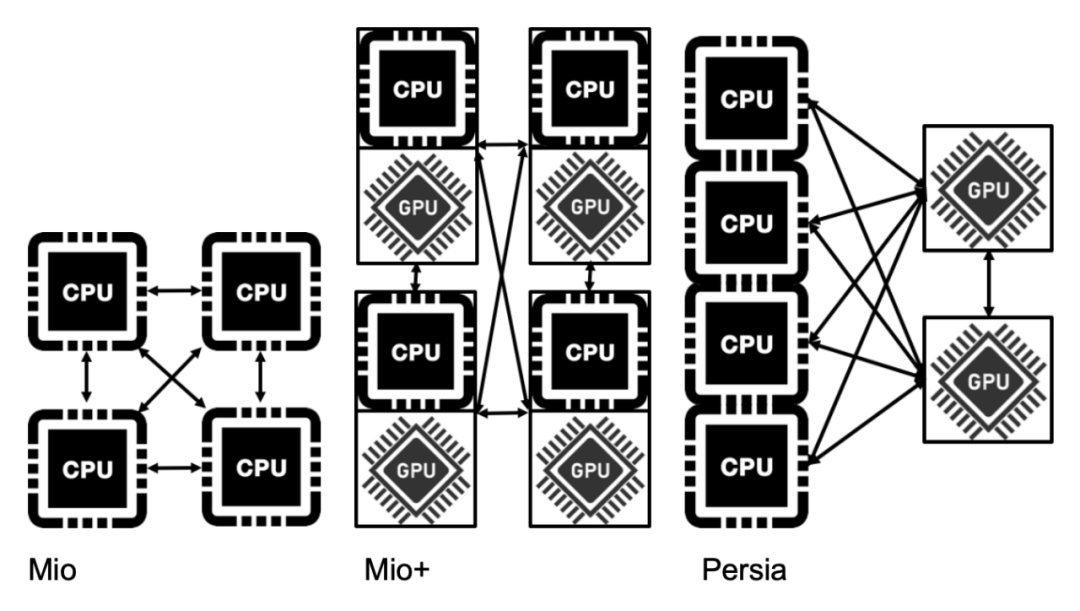
隨著模型的參數(shù)量隨著指數(shù)級(jí)別的增長(zhǎng),對(duì)于高性能的訓(xùn)練框架的需求也越來(lái)越迫切。傳統(tǒng)架構(gòu)在應(yīng)對(duì)越來(lái)越多參數(shù)量面前也顯得越來(lái)越力不從心。傳統(tǒng)架構(gòu)采用 CPU 的同構(gòu)并行機(jī)制,對(duì)應(yīng)的參數(shù)分布采用模型并行。
其最大的優(yōu)點(diǎn)是便于機(jī)器的水平擴(kuò)展以支持相對(duì)更大的模型,因此至今仍然在很多公司廣泛使用(雖然在各個(gè)公司有不同的命名方式,本文統(tǒng)稱(chēng)為 mio 架構(gòu))。當(dāng)推薦模型從傳統(tǒng)的 Logistic regression 升級(jí)到基于 Deep Learning 的模型,且參數(shù)量急劇增大的時(shí)候,傳統(tǒng)的方案就顯得捉襟見(jiàn)肘 ---- 效率低下且難以兼顧精度。后來(lái)的進(jìn)化版通過(guò)引入 GPU 承擔(dān)了深度網(wǎng)絡(luò)部分的計(jì)算(本文稱(chēng)為 mio + 架構(gòu)),由于采用的仍然是同構(gòu)的設(shè)計(jì)思路(只是把CPU機(jī)器換成了CPU帶GPU的機(jī)器),雖然能取得一定效率提升,部分緩解了效率和精度的矛盾,但是當(dāng)需要應(yīng)對(duì)不同規(guī)模的網(wǎng)絡(luò)結(jié)構(gòu)的時(shí)候,往往出現(xiàn)昂貴的 GPU 資源大量空閑的情況,導(dǎo)致性?xún)r(jià)比受損嚴(yán)重。
為了解決這兩個(gè)因模型規(guī)模不斷膨脹而帶來(lái)的難題,Persia 的核心設(shè)計(jì)思路如下:
- 采用異構(gòu)的架構(gòu)設(shè)計(jì)解決 GPU 資源利用率的問(wèn)題。當(dāng) CPU 和 GPU 的配比綁定的時(shí)候,任何框架都難以同時(shí)保證在任何模型結(jié)構(gòu)下的資源利用率。因此 Persia 設(shè)計(jì)了一種靈活的異構(gòu)架構(gòu)來(lái)實(shí)現(xiàn)按模型需求分配資源,保證效率的前提下資源的充分利用,大幅提升了性?xún)r(jià)比。
- 采用同步和異步的混合訓(xùn)練模式同時(shí)兼顧效率和精度。傳統(tǒng)的方案中或是采用純同步的訓(xùn)練,或是采用純異步的訓(xùn)練。在模型越來(lái)越大、機(jī)器數(shù)量越來(lái)越多的情況下,同步的訓(xùn)練會(huì)導(dǎo)致機(jī)器之間相互等待,訓(xùn)練效率容易受損嚴(yán)重。而異步的訓(xùn)練方式雖然避免了機(jī)器之間相互等待,訓(xùn)練的效率顯著提高,但是隨著機(jī)器數(shù)量增加,模型的準(zhǔn)確率(Accuracy)會(huì)大幅下降。針對(duì)超大模型情景下這樣的挑戰(zhàn),Persia 設(shè)計(jì)了一種同步和異步 Hybrid 訓(xùn)練架構(gòu),集二者之長(zhǎng)而避其短。并從理論和實(shí)踐兩個(gè)維度都驗(yàn)證了 Persia 能同時(shí)達(dá)到同步訓(xùn)練的準(zhǔn)確率和異步的訓(xùn)練的效率。
這里簡(jiǎn)要列出幾點(diǎn) Persia 的特點(diǎn):
- 原生支持 PyTorch 生態(tài):鑒于 PyTorch 極大地降低了研究人員定義模型的門(mén)檻,趨勢(shì)上在整個(gè)深度學(xué)習(xí)領(lǐng)域的占比越來(lái)越大,有別于已有的推薦訓(xùn)練框架(如 XDL,PaddlePaddle 等),Persia 決定基于 PyTorch 生態(tài)。用戶(hù)模型定義等操作可直接借助 PyTorch 實(shí)現(xiàn),因而即便是在研究領(lǐng)域最新最前沿模型(如 Transformer 等)也可直接調(diào)用,達(dá)到最大限度的靈活性與易用性。
- 高性能:在 Criteo 標(biāo)準(zhǔn)數(shù)據(jù)集上,相較其他流行的開(kāi)源推薦模型訓(xùn)練框架,同樣資源條件下 Persia 可達(dá)到一倍以上的性能提升。Persia 支持 CPU-GPU 異構(gòu)訓(xùn)練,支持 GPU 與 GPU 直接通訊,顯著降低訓(xùn)練成本。
- 可擴(kuò)展性:Persia 在高達(dá) 100 萬(wàn)億模型參數(shù)訓(xùn)練的 scale 下保持高訓(xùn)練效率。同時(shí)在多數(shù)場(chǎng)景能夠接近線(xiàn)性加速(投入 n 倍的資源量,訓(xùn)練效率提升接近 n 倍)。
- 工業(yè)級(jí)場(chǎng)景大規(guī)模驗(yàn)證:Persia 為 Kubernetes 實(shí)現(xiàn)了定制化的 operator,支持云原生部署。并實(shí)現(xiàn)了各種容錯(cuò)機(jī)制,經(jīng)過(guò)在線(xiàn)上生產(chǎn)環(huán)境穩(wěn)定運(yùn)行兩年以上的驗(yàn)證。Persia 經(jīng)過(guò)多個(gè)億級(jí) DAU 核心業(yè)務(wù)場(chǎng)景的實(shí)踐檢驗(yàn),取得了顯著的性能和業(yè)務(wù)指標(biāo)提升。
- 安全、故障易排查:Persia 由注重內(nèi)存安全、速度和并發(fā)性的 Rust 語(yǔ)言實(shí)現(xiàn),在編譯期就排除了大量的內(nèi)存安全問(wèn)題。原生提供大量打點(diǎn)監(jiān)控,與 Grafana 完美結(jié)合,可自定義各類(lèi)報(bào)警條件。同時(shí)基于 tracing 實(shí)現(xiàn)了分模塊、分層級(jí)的 log 輸出,使得實(shí)際場(chǎng)景中故障排查更加輕松。
- 靈活的特征處理:支持交叉特征等各種常見(jiàn)特征處理方式,且用戶(hù)通過(guò) Python 腳本即可定義各種自定義特征處理模式。兼具靈活性與易用性。
- 線(xiàn)上線(xiàn)下一致性:離線(xiàn)訓(xùn)練和線(xiàn)上訓(xùn)練代碼統(tǒng)一,解決工程師常常需要花費(fèi)大量時(shí)間排查模型上線(xiàn)效果不一致等痛點(diǎn)問(wèn)題。
Persia 設(shè)計(jì)思路
整體架構(gòu)
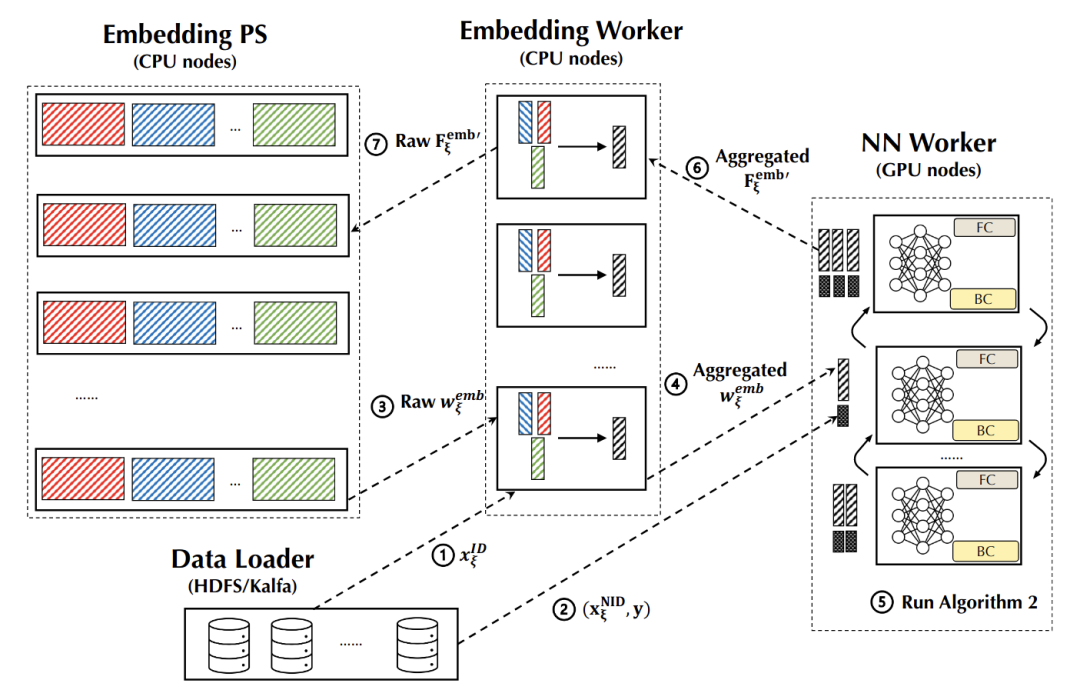
在推薦模型中,模型往往由下圖中的幾部分構(gòu)成:
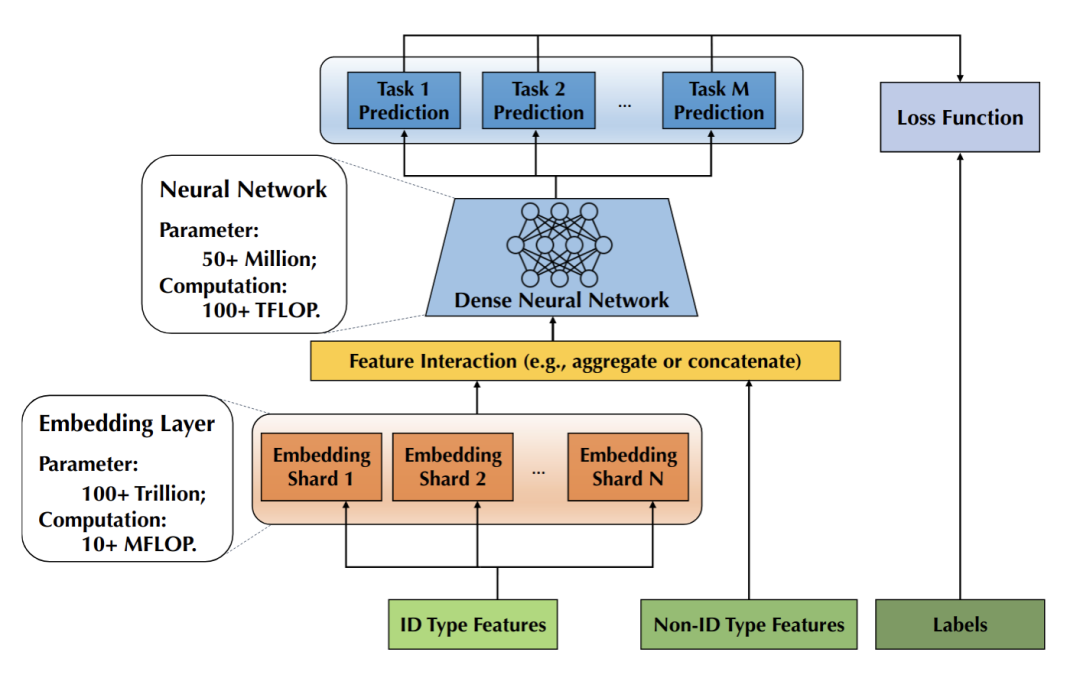
- Embedding Layer: 用戶(hù) id、item id 等 ID 類(lèi) feature 對(duì)應(yīng)的 Embedding 構(gòu)成的 Embedding 層。每個(gè) id 對(duì)應(yīng)一個(gè)預(yù)設(shè)大小的向量(稱(chēng)為 Embedding),由于 id 數(shù)量往往十分巨大,這些向量常常會(huì)占據(jù)整個(gè)模型體積的 99% 以上。
- Non-ID Type Features: 圖像信息、LDA 等實(shí)數(shù)向量特征。這部分將會(huì)與 id 對(duì)應(yīng)的 Embedding vector 組合在一起,輸入到 DNN 中預(yù)測(cè)點(diǎn)擊率等。
- Dense Neural Network (以下簡(jiǎn)稱(chēng) NN): 這部分是一個(gè)神經(jīng)網(wǎng)絡(luò),接受 Embedding vector 和實(shí)數(shù)向量特征,輸出點(diǎn)擊率等希望預(yù)測(cè)的量。
這種推薦模型中, Embedding Layer 參數(shù)往往占模型體積的絕大部分,但 Embedding Layer 的計(jì)算量卻不大。而 NN 的參數(shù)量只占模型體積的很小部分,卻占了絕大部分計(jì)算量。這正對(duì)應(yīng)了:硬件上 CPU 的內(nèi)存較大,但算力較低,而 GPU 的顯存較小,但算力較高。
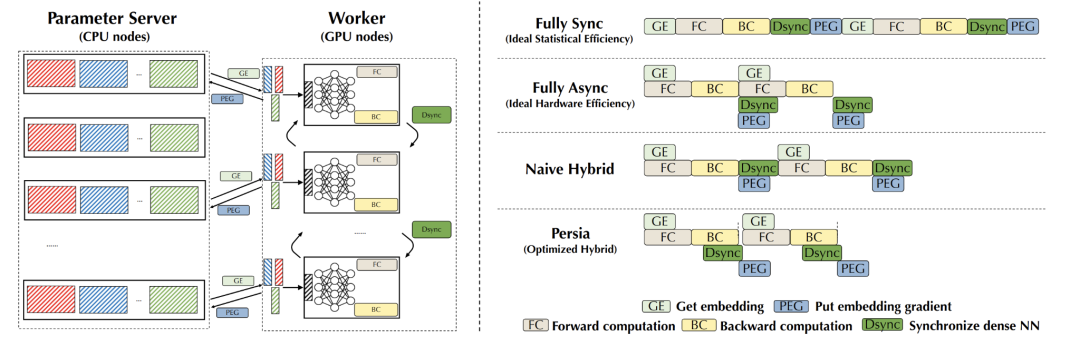
現(xiàn)有的訓(xùn)練框架雖然包含GPU算力,但是每個(gè) GPU worker 都需要跟大量 PS 之間傳遞數(shù)據(jù)和模型,這常常會(huì)觸發(fā)通訊瓶頸,從而整個(gè)效率都被拖垮了。
因此,在 Persia 系統(tǒng)設(shè)計(jì)中,NN 被置于 GPU 顯存中,通過(guò) GPU 進(jìn)行梯度計(jì)算。對(duì)于 NN 部分直接通過(guò) GPU 與 GPU 之間的高效集合通訊同步,完全不經(jīng)過(guò) PS。而 Embedding 則置于內(nèi)存中,通過(guò) CPU 進(jìn)行計(jì)算。Persia 對(duì)于 PS 進(jìn)行兩層架構(gòu)設(shè)計(jì) (Embedding PS, Embedding Worker,后文介紹),能夠在多數(shù)場(chǎng)景下進(jìn)一步降低 GPU worker 帶寬消耗,提升整體訓(xùn)練效率。
同步+異步混合訓(xùn)練
此外,現(xiàn)存系統(tǒng)往往采用全同步訓(xùn)練或全異步訓(xùn)練方式。在全同步訓(xùn)練中,所有 GPU worker 對(duì)一批數(shù)據(jù)進(jìn)行訓(xùn)練和模型更新,全部完成后再進(jìn)入下一批數(shù)據(jù)。在模型越來(lái)越大、機(jī)器數(shù)量越來(lái)越多的情況下,會(huì)導(dǎo)致機(jī)器之間相互等待、同步的時(shí)間大幅增加,難以在有限時(shí)間內(nèi)完成訓(xùn)練。這種情況下系統(tǒng)的訓(xùn)練過(guò)程如下圖中第一行 (Full Sync) 所示。在全異步訓(xùn)練中,每個(gè) worker 獨(dú)立訓(xùn)練并更新 PS 參數(shù)。雖然 worker 之間不需要相互等待,訓(xùn)練的效率較高,但是隨著機(jī)器數(shù)量增加,每個(gè) worker 上使用的模型的差異會(huì)變大,導(dǎo)致模型的訓(xùn)練效果大幅下降。這種情況下系統(tǒng)的訓(xùn)練過(guò)程如下圖中第二行 (Full Async) 所示。
針對(duì)這兩種方式的問(wèn)題,Persia 設(shè)計(jì)了 Hybrid 訓(xùn)練架構(gòu),能夠在保證訓(xùn)練效果的同時(shí),達(dá)到接近全異步的訓(xùn)練效率。推薦場(chǎng)景訓(xùn)練中的一個(gè)核心觀察是,Embedding 的更新非常稀疏,兩次更新之間往往交集很小,因此即使對(duì) Embedding 做異步更新,對(duì)最終的訓(xùn)練結(jié)果影響也不大。而 NN 部分的更新則反之,每一次都會(huì)更新全部參數(shù),如果做異步訓(xùn)練,會(huì)導(dǎo)致訓(xùn)練結(jié)果的巨大差異。Persia 所提出的 Hybrid 訓(xùn)練方式,能夠?qū)?NN 部分同步訓(xùn)練,Embedding 部分異步訓(xùn)練。最終訓(xùn)練效率接近純異步訓(xùn)練的效率,同時(shí)模型效果保持和全同步訓(xùn)練一致。兼得兩方面的優(yōu)勢(shì)。這種情況下系統(tǒng)的訓(xùn)練過(guò)程如下圖中第三行 (Naive Hybrid) 所示。Persia 在此之上還對(duì)能夠并行執(zhí)行的通訊、計(jì)算操作進(jìn)行重疊,進(jìn)一步提升系統(tǒng)效率。最終系統(tǒng)的訓(xùn)練過(guò)程如下圖中第四行 (Persia) 所示:
理論保證
有別于現(xiàn)存系統(tǒng),Persia 對(duì)于 Hybrid 算法的設(shè)計(jì)給出了嚴(yán)格的理論保證。對(duì)于 Expectation of Loss 的優(yōu)化問(wèn)題(比如推薦場(chǎng)景中最普遍的每個(gè)樣本對(duì)應(yīng)一個(gè) loss 的場(chǎng)景):
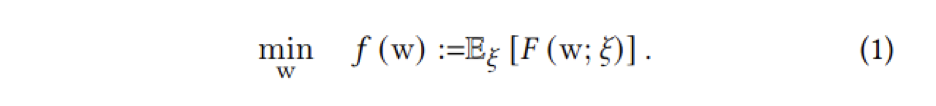
其中 f(w) 代表整個(gè)數(shù)據(jù)集上的平均 loss,ξ 代表一個(gè)樣本,w 代表模型參數(shù),F(xiàn)(w; ξ) 代表樣本 ξ 上的 loss。模型訓(xùn)練的目標(biāo)是最小化整個(gè)數(shù)據(jù)集上的平均 loss。使用 Persia Hybrid 的訓(xùn)練方式,可以證明模型的收斂速度為:

其中 σ 為數(shù)據(jù)集方差,T 為迭代次數(shù),τ 為 GPU worker 數(shù)量,α 為 ID 類(lèi) feature 碰撞概率。其中前兩項(xiàng)為全同步訓(xùn)練的收斂速度,最后一項(xiàng)為 Hybrid 訓(xùn)練引入的誤差。在推薦場(chǎng)景中,因?yàn)?Embedding 的更新非常稀疏,碰撞概率 α 遠(yuǎn)小于 1,因此 Hybrid 收斂速度與全同步訓(xùn)練收斂速度幾乎完全一致,但因?yàn)橥介_(kāi)銷(xiāo)減少,每一步的訓(xùn)練執(zhí)行效率大幅提升。對(duì)于具體的理論證明,可以參考 Persia 的論文 [1]。
其他優(yōu)化
在算法創(chuàng)新的基礎(chǔ)上,為了發(fā)揮極致的性能。Persia 提供了大量的實(shí)現(xiàn)層優(yōu)化。比如:
- 所有 PS 服務(wù)通訊使用為訓(xùn)練場(chǎng)景優(yōu)化的 zero-copy Persia RPC 系統(tǒng),在訓(xùn)練場(chǎng)景下(特點(diǎn)是 payload 非常大,包括 Embedding 和梯度等等大量 tensor 數(shù)據(jù))性能遠(yuǎn)超傳統(tǒng) RPC 框架(如 gRPC、bRPC);
- GPU 之間通訊使用同為快手開(kāi)源的 Bagua 訓(xùn)練加速框架,對(duì) GPU 之間的集合通訊性能有顯著提升,并能通過(guò)梯度壓縮等算法進(jìn)一步降低通訊開(kāi)銷(xiāo);
- Embedding 在 PS 中通過(guò)特殊設(shè)計(jì)的數(shù)據(jù)結(jié)構(gòu) (Persia Embedding Array List) 存儲(chǔ),大幅提升 PS 效率和模型存取效率。這包括運(yùn)行過(guò)程中無(wú)需動(dòng)態(tài)申請(qǐng)新內(nèi)存,同時(shí)更好地利用 CPU cache 機(jī)制。支持 Embedding 逐出邏輯。模型保存和讀取過(guò)程簡(jiǎn)化為對(duì)連續(xù)內(nèi)存的直接 Dump/Load 過(guò)程;
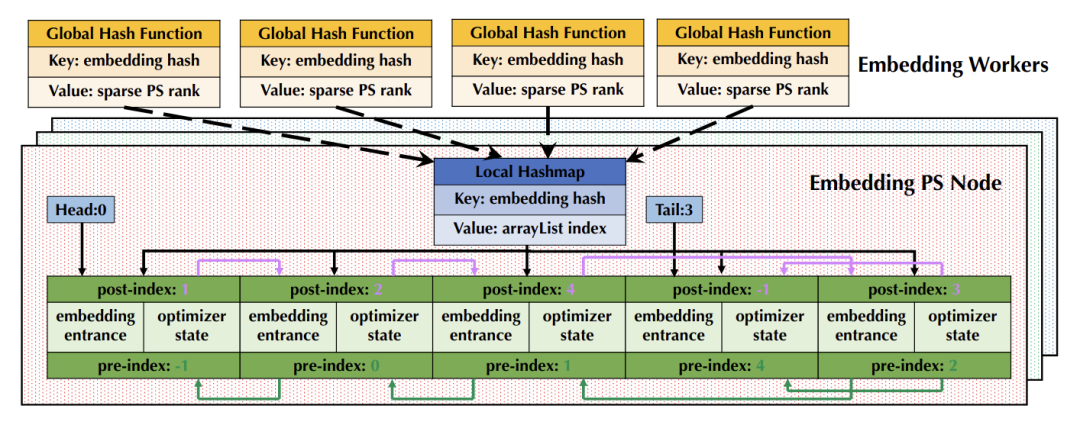
- 引入 Persia Embedding Worker 組件,將 Embedding Sum Pooling、處理原始數(shù)據(jù)等操作執(zhí)行后再發(fā)送給 GPU,大幅減少 GPU 帶寬占用;
- 原始數(shù)據(jù)處理為 Persia Compact Batch 格式,自帶 ID 去重和數(shù)據(jù)壓縮表征等性質(zhì),相比一般表示方式數(shù)據(jù)體積降低至 1/4,提升系統(tǒng)數(shù)據(jù)處理效率。
驗(yàn)證和比較
測(cè)試選用 Alibaba-Ad,Avazu-Ad,Criteo-Ad 等多種開(kāi)源數(shù)據(jù)集,訓(xùn)練效率整體有 8 倍以上提升:

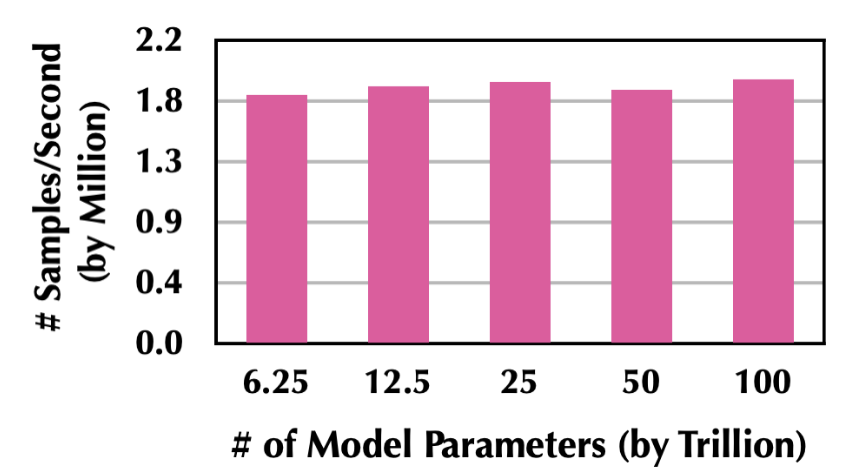
Persia 可支持高達(dá) 100 萬(wàn)億模型訓(xùn)練,并在模型規(guī)模變大時(shí)保持訓(xùn)練效率:
在資源量擴(kuò)大時(shí),Persia 可以接近線(xiàn)性擴(kuò)展(投入 n 倍的資源量,訓(xùn)練效率提升接近 n 倍):

Persia 使用實(shí)例
使用 Persia 非常簡(jiǎn)單,主要分為訓(xùn)練部署、模型定義、自定義數(shù)據(jù)集部分。
- 分布式部署:通過(guò) Persia operator 可在 Kubernetes 集群上一鍵部署 PERSIA 任務(wù)
- 模型定義:直接使用 PyTorch
- 自定義數(shù)據(jù)集:自定義預(yù)處理邏輯,將結(jié)果通過(guò) Persia 提供的 Python 工具包轉(zhuǎn)換成 Persia Compact Batch 即可
完整例子和更多場(chǎng)景,歡迎參考 Persia Tutorial 文檔(https://persiaml-tutorials.pages.dev/)。Persia 模型上線(xiàn)推理
Persia 訓(xùn)練的模型 Embedding 部分可通過(guò)線(xiàn)上部署 Embedding PS 和 Embedding Worker 直接提供服務(wù)。NN 部分為原生 PyTorch 模型,在 Persia Tutorial 中提供了通過(guò) TorchServe 推理的簡(jiǎn)單例子。用戶(hù)也可以通過(guò)原生 PyTorch 的各種工具,比如轉(zhuǎn)換成 TensorRT 模型,進(jìn)一步提升推理性能。?